Lucene搜索流程(上)
Posted NoSQL漫谈
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Lucene搜索流程(上)相关的知识,希望对你有一定的参考价值。
前面的一系列文章,都是围绕着Lucene的索引文件格式与索引的流程展开的,涉及到不少复杂而巧妙的设计,而这一切工作,都是为文档的快速搜索而服务的。从本文开始,我们开始探讨Lucene的搜索流程。
搜索,就是Lucene依据用户提供的灵活的搜索条件,匹配出满足条件的文档集合的过程。借着搜索的流程,我们也可以再回顾一下Lucene的索引文件设计,这样才能更好的理解这些设计的初衷。
整体流程
Lucene搜索的流程,可以被简单描述为:
1. 解析查询条件,生成一棵逻辑语法树
2. 提取基于Term的原子查询
3. 通过字典信息定位Term的Postings位置
4. 读取Posting用于文档匹配与文档评分
5. 按语法树的定义执行逻辑运算
6. 通过Collector收集目标文档集合
关于完整索引目录的读取,被封装在了一个IndexReader对象中,而一个索引目录下,可能包含多个Segments,关于每一个Segment的读取,又被封装成了一个SegmentReader对象。如果简单将整个搜索流程分解为前端处理与后端处理(注意:这都是一个进程内部的处理),上面步骤中的1,2,5,6都属于前端处理的部分,而3,4则是后端处理,如下图所示:
上图中的PostingsEnum中,装在了Term相关联的Postings信息,图中未描述文档评分和文档收集的过程。
在下面的章节中,将展开更多的细节。
如何获取Postings位置信息?
我们先来简单回顾一下TermsDict的存储结构,它包含两部分信息:
索引部分FST
索引信息Block列表
它们组成了一个Burst-Trie结构,FST是以TermsDict的block的共同前缀构建的,可以将其理解为Trie。每个block记录了每个Term以及其索引信息的位置。
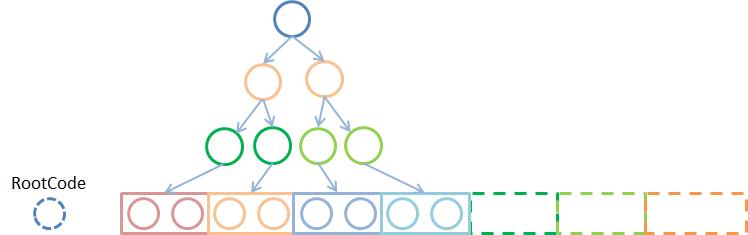
TermsDict构建一个Burst-Trie的过程是这样的:先将所有Terms排序,而后按照从小到大的遍历过程,一步步将共同前缀合并。合并的意思是将共同前缀的每个字符变成一个节点,当一节点超过25个子节点时,TermsDict将这个节点的所有子节点变换成一个Block写入Block列表中。当一个节点的子节点数超过25个时,就会改写成Block并将这些子节点从Tree中删除;当一个节点的子节点数据超过48个时,会拆分Block,从而保证每个Block的Terms数目在25-48个范围内。
最终生成的树,如上图所示,它包含一个Root节点和一系列Block,上图以2个节点作为一个Block,虚线框表示非叶子节点。
在内存中,TermsDict由SegmentTermsEnum或者IntersectTermsEnum表示,分别代表两种查询TermsDict的方式,精确查询和近似查询,此外还有一种应用于Points类型的区间查询能力。TermsDict中的Block部分称之为Frame,Frame的加载过程分为两个步骤:在初始化过程中读取元数据;按需读取索引数据。
已然知道,Search过程得先确认Terms在Segment的词典中存在,才能继续后续操作。精确查询、近似查询与区间查询,在如何确认搜索目标Term是否存在以及如何定位目标Term相关Postings位置信息方面有所不同,下面将分别展开介绍。
精确查询
SegmentTermsEnum为精确查询服务,它利用TermsDict的索引FST加速TermsDict的查询。FST可以快速定位到Term可能存在的Block,获取到Block以后,还需要遍历Term的后缀信息才能真正确认Term是否存在。
当某个节点的子节点数量比较多时,则会拆分多个Block存储,此时SegmentTermsEnum需要读取多个Block的数据来确定Terms是否真正存储,如果存在,再获取Postings所在的位置信息。
近似查询
IntersectTermsEnum除了支持通过FST定位Term的Postings所在位置之外,它支持通过有限决定状态机的查询来获取所有满足表达式的Terms以及其Postings信息的位置。它可以支持以正则表达式作为搜索条件,通过正则表达式来筛选TermsDict,最终返回所有符合表达式的Terms集合。
IntersectTermsEnum在支持近似查询时,支持设置开始与终止位置,从而减少数据扫描区间以提升性能。IntersectTermsEnum也是可以支持基于FST快速定位Block位置,通过设置的开始条件快速定位到第一个起始遍历的Block。
关于区间查询,它与近似查询在定义上区别如下:
近似查询:近似查询的查询关键词可能是通配符查询和前缀查询,甚至是正则表达式,总之查询涉及的Term不是唯一确定的。
区间查询:区间查询的Terms也是不确定的,它只指定一个范围,需要先通过TermsDict找到所有在Query指定区间内的所有Terms,再转成BooleanQuery进行查询。
近似查询和区间查询都是先按照自己的匹配规则得到一个符合条件的Terms集合,后续流程与精确查询流程类似。近似查询的类型有很多,实际上都是用正则表达式来表示的。在验证Term是否存在以及查找Term索引信息的位置时,如果不考虑Points数据,区间查询与精确查询流程也是类似的,但近似查询需要先构建正则表达式DFA来查找具体的Terms。
需要用到posting的哪些信息?
我们先回顾一下Posting的结构:
图中对述Lucene的索引结构描并不准确,但是它完全展现了完整索引表包含的信息,以及各种信息之间的关系。 只是Lucene存储时,出于读写性能的考虑改变了存储结构。它说明了Postings包含的信息有DocID、TermFreq和Positions,表示一个Term在文档DocId出现了TermFreq次,分别出现在Position位置以及相关附加信息。位置信息是指第几个词(Posititon),从第几个字段符到第几个字符(StartOffset,EndOffset),和附加信息Payload。每个Position含有三部分信息,它们是一个三元组结构。
关于Lucene的倒排表存储结构内容,请参考《》一文。
我们知道posting在Lucene分成三个文档存储,拆分是为了更灵活的满足各类查询需求的同时,减少数据冗余读取。不同的查询,可能需要读取Posting中的不同过的信息组合,可以将查询大致分为三种类型:TermQuery,PhaseQuery和PayloadQuery。
虽然在读取postings时,不管读多少种索引信息,实际影响可能并不明显。而读取的流程也因此变得更不复杂,因为在block中已经记录所有需要记录元数据了,同时Term被查找出来之后,其Postings的所有元数据信息也已经被完全解析存在内存中。所以读取一种或者两种,三种实质性能影响并不大。
1. 基于doc的TermQuery
首先,读取DocIDSet是所有查询都不可避免的过程,包含Facet/Stats统计查询,但不包括MatchAllQuery。而涉及TF-IDF评分的查询,读取索引文件中的TermFreq信息也必不可少。Lucene也正是将TermFreq与DocID存储在同一个索引文件(.doc)中,它也是Postings不可或缺的部分。
TermQuery是Lucene最基础的查询类型,查询过程中仅需要.doc文件的信息。在TermsDict找到Postings的位置之后,将元数据信息装载到BlockDocsEnum交给Scorer遍历所有命中的文档进行评分。Scorer是Query根据自己类型创建的,Query除了创建Score之外,还有用于计算Query权重的Weight。Scorer和Weight的计算公式由Simarity提供。最后由Collector收集所有命中的文档以及最终相似度的评分,由于它可能实现多种结果集的展示形式,诸如Facet/Group等。
2. 基于doc+pos的PhaseQuery
短语查询和坡度查询,它要求关键词有连续出现,或者编辑距离小于指定长度才算命中,因此PhraseQuery/SpanQuery必须用到Position信息才能确定关键词在文档的位置是否满足查询条件的要求。它依赖Position过滤查询预设的位置要求的文档,然后将结果再由Query交给scorer进行对文档的评分。
1.短语查询(PhraseQuery)要求多个Term之间连续出现,且编辑距离小于指定长度。
2.坡度查询(SpanQuery)要求多个Term之间出现位置小于指定长度。
在TokenStream中Position表示相对位置,相对于前一个Token而言。它是如下定义Position的:
0表示是两词为同源词,或者采用了同义词表;
1表示连续,有停顿词;
>1表示中间有停顿词,其数值表示停顿词的个数。
但在索引(.pos文件)中,它存储的是绝对位置信息,即需要累加前所有Token的Position,相同数值表示同源词,或者同义词;两个Position差值为1,表示连续;在有停顿词的情况下,也会记录停顿词的个数。
Offset信息也是由TokenStream产出的,Offset分为StartOffset和EndOffset两种情况,分别代表Term的第一个字符的位置,以及最后一个字符的位置,它们表示Term在文档中绝对位置。也就是说StartOffset和EndOffset两个位置可以共同决定唯一个Term,与Postition不同,相同的Position可以有多个Term。
例如,索引时采用IK分词器的索引时分词策略时,IK可能会切出多个同源词,比如将“中国人民共和国”分成“中国”、“中国人”等多个同源词。此时,如果使用Postition来计算两个词之间的相对位置会很方便,比起使用StartOffset和EndOffset。
从Position和Offset的区别上可知,正常来说PhraseQuery和SpanQuery两种类型的查询并不涉及Offset。另外.pos主要是存储Postition和一小部分Offset信息和Payload信息,Offset和Payload主要是存储于.pay文件中。
3. 基于doc+pos+pay的PayloadQuery
PayloadScorerQuery允许用户在查询时,可以利用索引写入的额外信息用于影响查询评分,它是索引时的Boost升级版本,它支持更丰富信息和手段来干预文档的最终评分。关于PayloadQuery查询更详细的介绍、使用场景和用法,请参考《Solr迟到的Payloads》一文。
总结
这里主要介绍了搜索后端流程主要两大步骤,如何在字典找到目标Postings所在位置信息,以及为需要读取哪些信息为查询提供筛选和评分的依据。以及每个步骤都以不同的角度将查询类型进行分类,且对它们做了简单的介绍。
关于"NoSQL漫谈"
NoSQL主要泛指一些分布式的非关系型数据存储技术,这其实是一个非常广泛的定义,可以说涉及到分布式系统技术的方方面面。随着人工智能、物联网、大数据、云计算以及区块链技术的不断普及,NoSQL技术将会发挥越来越大的价值。
更多NoSQL技术分享,敬请期待!
以上是关于Lucene搜索流程(上)的主要内容,如果未能解决你的问题,请参考以下文章
搜索引擎系列六:Lucene搜索详解(Lucene搜索流程详解搜索核心API详解基本查询详解QueryParser详解)