Lucene搜索流程(下)
Posted NoSQL漫谈
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Lucene搜索流程(下)相关的知识,希望对你有一定的参考价值。
在上一篇文章中,重点讲到了如何通过TermsDict定位Term所对应的Postings的位置,以及读取Posting的过程,我们姑且将这部分理解为一次搜索过程中的后端处理。上篇文章还将搜索的主要流程,简单概括为如下七个步骤:
解析查询条件生成一棵逻辑语法树
提取基于Term的原子查询
通过字典信息定位Term的Postings位置
读取Posting用于文档匹配
构建评分器对文档评分
按语法树的定义执行逻辑运算
通过Collector收集目标文档集合
如此看来,上篇文章的内容只讲解了第3步与第4步的处理流程。这篇文章,将继续探讨余下的内容。
Query
对于常见的组合查询条件,IndexSearch需要先将查询条件解析成一颗语法树。语法树的所有叶子结点均为一个原子搜索,如TermQuery,这意味着需要基于IndexReader读取某一个Term对应的Postings信息。非叶子节点则需要汇聚子节点的计算结果。
但如果用户提交的查询原本就是一个原子查询,那就略去了上面提到的解析过程。
TermQuery
我们先来看一下最基础的TermQuery的处理流程。
TermQuery按下图流程得到Postings信息,并构建成一个PostingsEnum对象(Postings信息被封装在PostingEnum对象中),它是一个迭代器。PostingsEnum中的元素按DocID升序存放,它提供了advance操作来将迭代器指针移动到指定位置并返回相应的元素。advance操作将在本文后面的内容中详细介绍。
关于Posting读取的过程,在上篇文章中已详细讲过,这个过程中,还记录了Term的相关统计信息(如TTF, TDF等),这些信息将被应用在后续的评分过程中。
有了Posting信息以后,紧接着就是文档的匹配和评分流程。IndexSearch利用Query创建一个Weight对象用于文档的二次匹配(诸如PhraseQuery需要去除距离不符的文档),这部分内容上文中也讲过,然后,再由Weight对象创建出一个Scorer对象用于文档评分工作。
Weight
Query查询TermsDict之后获得的Postings会给Weight,所以,Weight对象可直接访问Postings。对于TermWeight而言,它只负责两件事: 一方面创建一个与它对应的Scorer评分器,由它负责文档的评分方面工作。另一方面,通过matches接口向外部提供访问Term的Postings信息,即指定的Term出现在哪些文档上,在每个文档中出现的次数位置和每个位置附带额外信息。
Scorer由Weight对象创建,但Weight需要结合Terms在候选文档上的位置信息和Payload信息对评分结果进行explain。
Scorer
Scorer是Lucene在搜索流程用于计算Query与文档相似度计算的外围组件,它实际上并不负责文档得分的计算,这部分工作委托给了Similarity。Similarity才是真正的评分器,而Scorer只是负责评分外围的工作。比如它为文档评分提供必须参数,决定文档是否需要评分,哪部分文档进行评分,哪些文档不用评分。也就说它决定了读取Postings信息的种类和模式,是否启用跳表优化等。
注:Query与文档的相似度代表文档在这次查询的得分,得分越高,相似度越高。可将文档得分与相似度理解为相同的含义.
虽然Scorer不负责文档得分的计算,但文档的最终评分却是由Scorer提供的。Lucene实现了两种常用的评分计算模型,空间向量模型和BM25概率模型。这两种模型都依赖于TF-IDF,它是一种统计方法,可以粗略的将二者关系理解为:TF-IDF用于计算权重,两模型通过权重计算相似度。从Lucene 6.0版本开始,已经默认使用了BM25概率模型。
TF-IDF用于计算查询词Term文档或者Query的权重,那么文档与Query的相似度如何用这两种权重来表示呢?以空间向量模型为例,Query中的Term系列,可以计算得每个Term的文档权重,得到文档权重系列,它也是文档权重的向量。同样的方式也可以得到Query权重的向量,那么Query与文档的最终相似度便可以表示为两向量的距离。
评分模式:Score_Mode
至于如何决定文档是否需要评分,Lucene定义了三种模式分别如下:
TOP_SCORE,最常用的方式,即按文档得分取查询结果集的TopK
COMPLETE,则需要为所有候选文档都进行评分
NOT_COMPLETE,与COMPLETE相反,它表示完全不需要评分
关于评分模式,通常由collector决定的,如在大部分的facet查询的collector便是完全无须评分的。但也有由排序的条件决定,如按字段排序。
在默认情况下,即如果没有指定Collector和排序条件,IndexSearcher就会采用TOP_SCORE模式,仅给用户返回TopK文档。显然Lucene仅需要对头部文档进行评分即可,即跳过部分候选文档不用为之计算就可以淘汰的。
Lucene为什么可以直接淘汰跳过部分文档,而不需要为之计算评分,且最终不影响召回的结果集呢?
首先从评分角度看,哪些因素会最终影响了评分呢?下面是对Lucene官方文档给出的TFIDFSimlarity相似度评分公式:
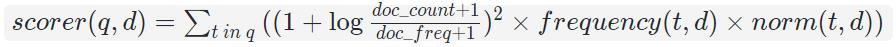
doc_freq表示搜索关键词term出现在多少个文档中
doc_count表示整个Segment的总文档个数
frequency(t,d)表示词条t在文档d中出现频次 norm(t,d)表示词条t在文档d归一化因子 其中这两个函
norm(t,d)和frequency(t,d)的值与本文中的上下文均用norm和freq表示。
由此可见,其中只有norm(t,d)和frequency(t,d)是随文档变化的,其它参数都在segment内确定不变的固定值。也可以理解为,在一个Segment范围内,freq和norm值直接决定了一个文档的得分排序。
其次是与Postings的存储结构相关,Postings是有序且分块存储的。为了让Postings实现非顺序查找,Lucene为此构建了多层SkipList,且在构建的时候,为每个节点记下当前以及之前所有Block的freq和norm信息。此时,Lucene便可以启用SkipList的优化,直接跳过低的文档。
Postings采用了分块存储的方式,为了能够快速访问某一个块,Lucene采用了SkipList的设计,前面的系列文章中已经讲过,这里我们再来简单回顾一下它的设计,并且结合搜索流程来探讨一下它是如何帮助提升搜索性能的。
SkipList
SkipList本质上是在有序的链表上实现实现二分查找,它能有效的提升链表的查找效率,其时间复杂度为O(logn)(其中n为链表长度)。简单说SkipList优化了Postings的随机查找的性能问题。
SkipList的节点存储了三部分数据,分别是当前节点指向Block的信息,是关于Block本身的信息;指向下层的索引;最后是存储freq和norm的信息,它被封装在Impact对象里面。
Impact结构仅存储了<freq, norm>键值对,与文档无关,在SkipList的索引节点中,Impacts表示一系列Impact结构,用有序的TreeSet存储。这里强调的是Impact并没有与具体文档关联,其次按freq和norm作为主键去重。也就是Impacts代表了该索引节点指向数据节点以及之前所有数据节点所包含的文档得分的分布信息。在TOP_SCORE模式下,如果此索引节点中最大的Impact都小于Scorer的水位线,那么此节点的范围内的所有节点都不需要再进入Scorer评分程序。
从.doc文件读取出来的SkipList如下图所示,为了方便制图,把步长缩小为2。在第0层,每两个Block创建一个索引节点,第1层在第0层的基本上构建,依此类推。
常规多层跳表结构,每个索引节点两个指针,一个指向同层下一个节点,叫next指针;另一个指向下一层的down指针。在下图中,第1层的节点4指向第0层的节点4的指针即是down指针,而从节点4直接指向节点8的叫next指针。
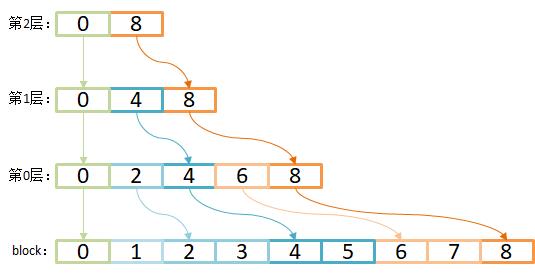
SkipList提升性能的思路,其实是通过在链表上加了多级索引获得的,以空间换时间。层级越高,索引的步长越短,构建索引的空间代价也会越高。这也解释了Lucene为何采用8个Block的步长,虽然查询性能会差一些,但需要的空间也减少了n/8,这是一种存储空间与性能的折中方案。
我们再来看一下SkipList的查找过程:以查找第7个Block为例,与最上层第二层的第1个节点比较,7 < 8;通过down指针下沉到第一层,7 > 4,通过next指针找到下一个索引节点继续比较,7 < 8。所以回溯到节点4,然后下沉到第0层,7 > 6且7 < 8。所以回到6节点并下沉,前进一个节点之后发现7 = 7,成功找到并返回。
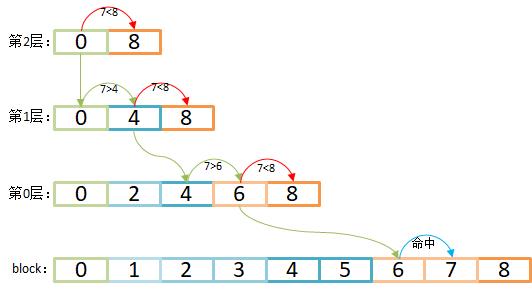
Lucene的SkipList仅多花费n/8的存储空间,便将Block的随机查询的性能提到O(logn)的时间复杂度。PostingsEnum的advance(target)是SkipList主要应用场景,它除了应用于TOP_SCORE,还能用在多个结果集间做析取和合取运算上。
BooleanQuery
在真实的运用情景下,多个条件的复合查询场景最为常见,Lucene使用BooleanQuery来描述一个符合查询,如下图所示:
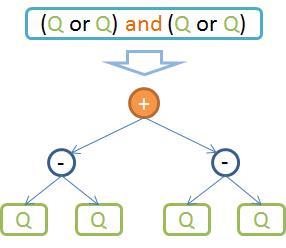
其所有叶子节点都是原子查询,它需要读取Postings信息,但非叶子节点都通过对叶子节点的Postings进行谓词运算获得。简单的BooleanQuery,是由多个原子查询以AND,OR,NOT等操作符连接起来,再复杂一点,BooleanQuery还可以包含嵌套的BooleanQuery。
在执行查询的时候,某些Term所关联的Postings可能过大,此时,如果对整个Postings中所有的文档都进行评分计算的话,代价太大。针对纯AND以及纯OR运算的BooleanQuery(也可能是一个嵌套的子BooleanQuery),Lucene专门设计了如下两种算法。
Conjunction算法
布尔运算的与运算,要求所有的查询关键词(查询条件)共同命中候选文档,即候选文档同时出现了所有查询条件的关键词。也就是Postings中都出现的文档号才是最终结果集。
实际上就是在多个集合间取交集,易知最终结果集必然是任意集合的子集。因此,基于最小的集合开始遍历,可以避免不必须尝试。而Lucene通过二阶验证,可以进一步减小无效尝试。基本思想是,合并后的结果集中每个文档必须是每个Postings都存在。
Lucene的实现比较巧妙,首先在Posting Lists中取出最短Postings命名为Lead1,接着取出次短Postings命名为Lead2,除此之外称为Others。然后遍历Lead1的每个文档的过程中,每个文档都在Lead2中做校验。假如在Lead2中不存在,则直接退出,否则到others中校验判断是否存在。简单说通过Lead1可以非常有效的减小尝试次数,通过Lead2则能进一步减小尝试的次数。总体思路就是避免到Others列表校验文档是否存在,流程如下。
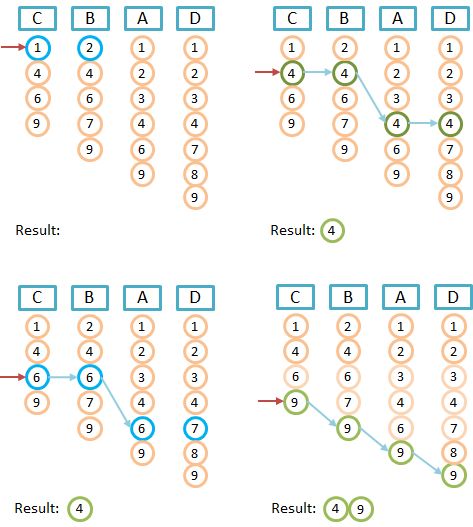
在Others的校验的式子如下,一旦max(...)返回NO_MORE_DOCS退出循环,合并完成。
boolean matches = (DocID == max(pe1.advance(DocID), pe2.advance(DocID), pe3.advance(DocID), ...);
通过如上流程中,都是通过PostingsEnum#advance(target)方法寻找离target最近且不小于target的DocID。而advance(target)在有SkipList的情况下,可能会启用SkipList优化。
Disjunction算法
布尔运算的或运算,要求将每个查询条件的结果集进行并集运算。每个查询的结果集Postings,在Lucene中都被表示为PostingsEnum。前面介绍PostingsEnum的操作advance(target),这个方法是取Postings的文档号不小于target的最小文档号。所以用编程语言描述为:
DocID = min(pe1.advance(DocID), pe2.advance(DocID), pe3.advance(DocID), ...);
此过程用图示如下,这里简化的Lucene的运算流程。实际上就是将DocID++之后进行上面式子的运算,直至每个元素都至少会被触达一次,也是DocID恰为NO_MORE_DOCS时表示计算完成。
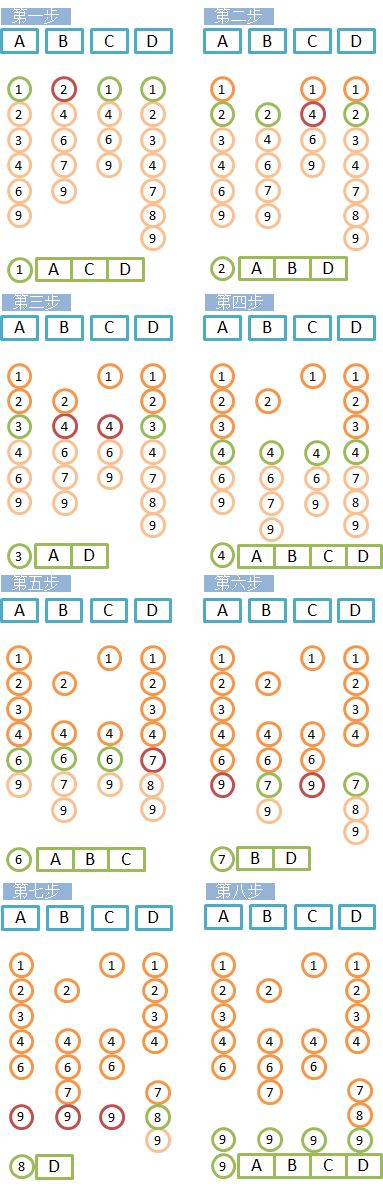
每一轮都会得到一条存在当前DocID的Postings数组,然后计算查询条件命中率,即拥有当前DocID的Postings占所有原子查询条件的比例。当它小于某个阀值时,该DocID被以为不匹配直接丢弃。而对于满足条件的DocID的Postings链表则会用于计算文档最终评分的计算,它有两种常用的计算策略,有SumScore和MaxScore,即是对每个子询的文档得分汇总并获取所有原子查询中的最高得分。需要简单提一点,Disjunction在计算文档得分时,针对TOP_SCORE模式,采用的是Weak-AND算法(一种剪枝算法),请参考论文”Efficient Query Evaluation Using a Two-Level Retrieval Process”。
文档结果集收集器:Collector
收集目标文档集可以算是Search流程的最后一个步骤了,它是对候选文档集进行过滤。这里有多种策略,比如通过该查询的候选文档的评分取TopK,或者按文档的某些字段值取TopK等。此外还有一些高级用法,如Group、Facet和Stats以统计为主的聚合运算。
这里主要以文档评分取TopK为例,介绍Collector搜索过程的主路径中充当的角色以及职责,顺带介绍取TopK的常见方案。
Search流程中,Collector会为每一个Segment分配一个所属的LeafCollector,用来负责这一个Segment的文档收集任务,由它触发Scorer对文档进行评分,再收集文档的得分和文档编号。在LeafCollector在收集过程会不断更新它的最小得分,有利于scorer更快的过滤不满足条件的文档。
在收集过程中,由于最终只按文档得分来取TopK文档,Lucene并不需要保留过程中所有的文档,因此问题转为化如何取TopK方案,Lucene采用经典的做法,依赖于优先队列,它的插入的取出的复杂度均为O(logK),而需要的内存仅为O(K)。关于PriorityQueue,我们可以详细展开一点内容:
PriorityQueue的创建时,需要先指定期望获得结果集的长度,然后PriorityQueue创建一个指定长度的数组。PriorityQueue在数组上构建一棵完全二叉树,其中第0个元素留空,第1个元素作为树的根节点。
如上图可能看起来还不够直观,为此把它位置重新调整一下变成如下所示。注意,图中的数字表示数组下标,而非是数据的值。
比较特殊的是PriorityQueue并不保证任意一个父节点的左右两个子节点之间有序,它只保证父节点小于任意子节点。它的根节点称为队首,也是整棵树中最小的节点。PriorityQueue主要包含如下几个操作:1. 定义节点排序器。2.取队首节点。3. 出队。4. 入队。
PriorityQueue的出入队的时间复杂度为O(logK),其中K为队列的长度,而取队首的时间复杂度为O(1)。
入队可以区别为两种方式,第一种是列队仍不满时,将数据放入队列中,然后将它与父节点比较,如果小于父节点,则对换位置之后,继续比较直至不小于父节点,入队操作完成。 第二种是列队已经满时,如果入队的数据小于父节点,入队操作完成。否则,将队首置换为入队的节点,然后它不断与它的子节点比较,直到它不大于子节点。相比之下,出队则比较简单,即将队尾置换队首,然后执行一下第二种入队操作。
不管是出队还是入队,都是被更新的节点是上浮或下沉两种操作。在下沉的过程,它还需要与两个节点都做一次操作,选择继续下沉的路径。
小结
这篇文章主要继续上篇文章,先基于原子查询TermQuery,介绍了文档的匹配与评分流程,而后介绍了复合查询BooleanQuery的合取与析取算法,文中还结合搜索流程讲到了两个重要的数据结构:SkipList与PriorityQueue。将搜索流程与索引构建流程结合,可进一步加深关于Lucene倒排索引的原理,所谓知其然也知其所以然。
以上是关于Lucene搜索流程(下)的主要内容,如果未能解决你的问题,请参考以下文章
搜索引擎系列六:Lucene搜索详解(Lucene搜索流程详解搜索核心API详解基本查询详解QueryParser详解)