知识图谱实战系列六:Lucene在知识图谱上构建索引
Posted 机器学习算法与知识图谱
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了知识图谱实战系列六:Lucene在知识图谱上构建索引相关的知识,希望对你有一定的参考价值。
这篇文章讲讲如何在知识图谱数据集上构建索引进行查询。
倒排索引是一种数据结构,它表示了这样一种映射,以字或词或数字为关键字进行索引,映射到出现这个字或词的所有文档或者数据库文件。
它大概由三部分组成term index、term dictionary 和posting list(倒排表)。
索引过程,首要需要找到term(关键词)索引的位置。term index就是用于找到关键词term在term dictionary(词典)中的位置。term index有很多种词典结构,比如哈希表,B树、B+、FST。
B树
B-树(Balance Tree)是一种多路平衡查找树,他的每一个节点最多包含M个孩子,M就是B树的阶。树的分叉多使得高度足够低,于是和磁盘的I0次数就会减少。
B+树
相比B树,其区别体现在:
父节点的元素都会出现在子节点,因此叶子节点包含所有元素信息。
从左边开始,每一个叶子节点带有指向下一个叶子节点的指针,形成一个有序链表,便于范围查询。而B-树做范围查询,只能依靠繁琐的中序遍历。
B+树非叶节点没有卫星数据(索引元素所指向的数据记录),磁盘页可以容纳更多节点元素,其高度会比B树矮,查询的IO会更少。
B+树的查询必须抵达叶子节点,查找性能更稳定
FST
FST(Finite State Transducer)原理是有限状态机原理构造的一个有向无环图。我们今天使用的Lucene就采用了FST的索引结构来构建词典。FST将关键词拆分为前缀和后缀,并在前缀部分构造了一个有向无环图进行索引。
FST其特点是非常节省内存,缺点是结构复杂、更新麻烦
Lucene是Apache软件基金会支持和提供的一套用于全文检索和搜索的开放源码程序库。用Java编写,为需要全文搜索的应用程序提供了一个简单却强大的接口,分布式检索分析系统Solr和ElasticSearch底层就是基于Lucene实现。
FST索引结构
Elasticsearch检索比mysql快的原因就是,相比Mysql以B树方式将term index和term dictionary存储在磁盘上,lucene的term index以FST的形式缓存在内存中。从term index查到关键词对应的term dictionary的块位置之后,再去磁盘上找term,大大减少了磁盘的IO次数。
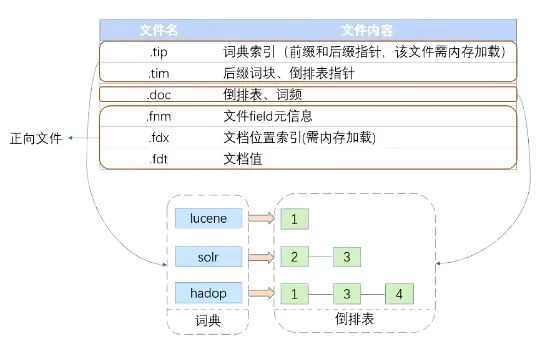
Lucene索引文件结构
DBpedia知识图谱
我们可以使用Lucene基于我们知识图谱具体的需求来构建倒排索引。这里使用的数据集是英文百科类知识图谱数据集DBpedia,其中大部分内容是从维基百科词条进行结构化得到的。我们对其中每个实体进行节点编号,将每个节点上的非实体属性文本作为每个节点的文档,就得到下面形式的文件:

节点和文本
构建索引
document是Lucene索引和搜索的原子单位。document为包含一个或多个域,每个域都有一个名称,当你将document加入到索引中时,可以通过一系列选项来控制 Lucene的行为。你需要将需要被索引的数据转换成 Lucene所能识别的document和域。
这里我们以知识图谱上的一个节点上的内容作为一个文档,包括三个域:
Document doc=new Document();
doc.add(new TextField("keywords", keywords, Field.Store.NO, Field.Index.ANALYZED));
doc.add(new IntPoint("nodeId",nodeId));
doc.add(new StoredField("nodeId", nodeId));
TextField为文本域,包含节点的文本内容,我们需要对其进行分词然后再建立到排索引,Field.Store.NO指定是否要在正向文档中保存这个域值,Field.Index.ANALYZED用于指定是否分词
Analyzer analyzer = new StandardAnalyzer();
directory = FSDirectory.open(Paths.get(indexStorePath));
IndexWriterConfig iwc = new IndexWriterConfig(analyzer);
IndexWriter indexWriter = new IndexWriter(directory, iwc);
// 建立doc这个文档的索引
indexWriter.addDocument(doc);
在构造索引写入器的时候,可以指定用于分词的工具analyzer,
Lucene比较常用的几种英文分析器,他们之间存在一些区别:
SimpleAnalyzer:空格及各种符号分割
StandardAnalyzer:混合分割,包括了去掉停止词,并且具备一定中文分词的功能
WhitespaceAnalyzer :空格分割
StopAnalyzer:空格及各种符号分割,去掉停止词,停止词包括 is,are,in,on,the等无实际意义的词
Elasticsearch内置的分词器就包含了上面这些。
另外还有许多用于中文分词的分词器如ik-analyzer、结巴中文分词等,可以根据需要进行配置。
搜索
Lucene的查询调用的是 Indexsearcher类中的search方法,调用时传人 Query类型作为参数。可以使用 QueryParser类将查询词转换成 Query类型。hitNum可以限制你要拿到的目标文档数。
IndexReader indexReader = DirectoryReader.open(directory);
IndexSearcher searcher = new IndexSearcher(indexReader);
QueryParser parser = new QueryParser("worsIdStr", new StandardAnalyzer());
Query query = parser.parse("aKeyword");
TopDocs tds = searcher.search(query, hitNum);
ScoreDoc[] sds = tds.scoreDocs;
这样,就可以找到这个查询词所在的文档id,也即查询词所在的知识图谱的图节点编号。

以上是关于知识图谱实战系列六:Lucene在知识图谱上构建索引的主要内容,如果未能解决你的问题,请参考以下文章