AIOps思考
Posted SRE说
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了AIOps思考相关的知识,希望对你有一定的参考价值。
1. 背景
AIOps,即 Artificial Intelligence for IT Operations,智能运维,将人工智能应用于运维领域,基于已有的运维数据(日志、监控信息、应用信息等),通过机器学习的方式来进一步解决自动化运维没办法解决的问题。
利用大数据、机器学习和其他分析技术,通过预防预测、个性化和动态分析,直接和间接增强IT业务的相关技术能力,实现所维护产品或服务的更高质量、合理成本及高效支撑。
目前已经在百度、阿里、腾讯、华为、京东等等多家公司得到多种应用。并且取得了很多不错的效果
2. 业界思路
2.1 AIOps的基本思路
2.2 组成全景

2.3 整体方向三大方向
质量保障方向
质量保障是运维的基本场景之一,随着业务的发展,运维系统也在不断的演进,其规模复杂度、变更频率非常大,技术更新也非常的快,与此同时,软件的规模、调用关系、变更频率也在逐渐增大。
在这样背景下,需要AIOps提供精准的业务质量感知、支撑用户体验优化、全面提升质量保障效率。
效率提升方向
效率提升是运维的基本场景之一,随着业务的发展,运维系统的整体效率的提升就成为了运维系非常重要的一环。在这样的背景下,除了增加人力是远远不够的,还需要AIOps提供高质量,可维护的效率提升工具。
成本管理方向
成本管理方向是当公司内部的业务日益增多的时候,如何在保障业务发展的同时,节省不必要的开支,有效地控制成本。成本是每个企业都很关注的问题,现在业界的资源利用率普遍偏低,平均资源使用率能做到20%以上是很少的。
AIOps 通过智能化的资源优化,容量管理,性能优化实现IT成本的态势感知、支撑成本规划与优化、提升成本管理效率。
2.4 平台体系
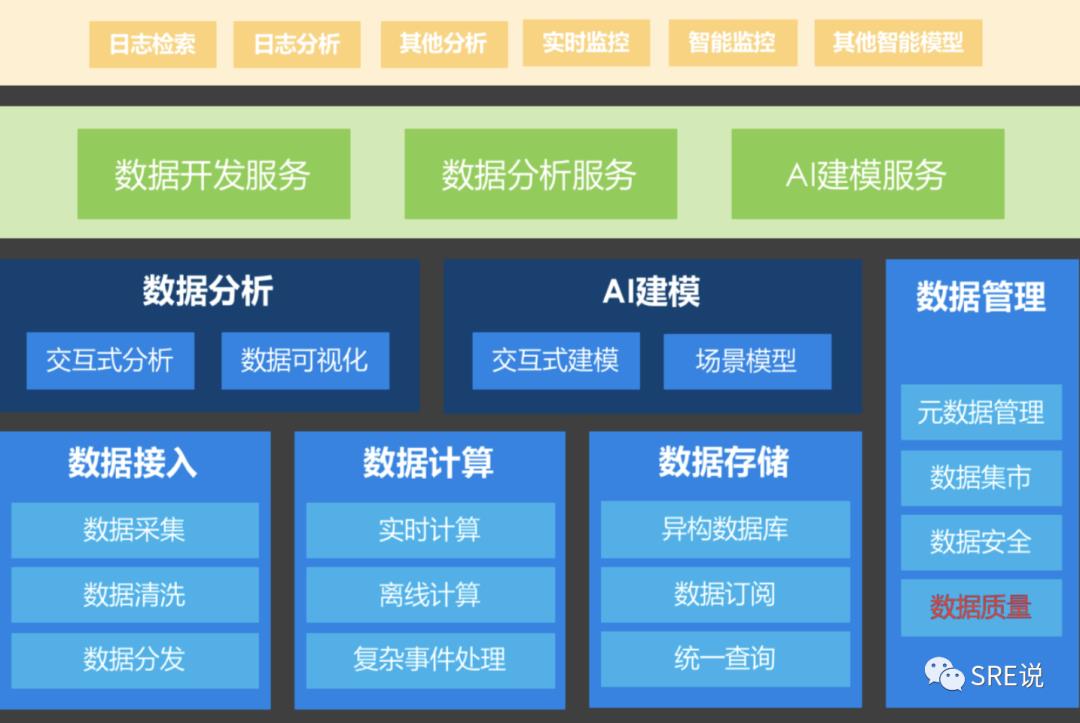
3. 落地场景分析
按照我们的实际场景建议分为四个方向 故障管理、变更管理、容量管理、服务咨询
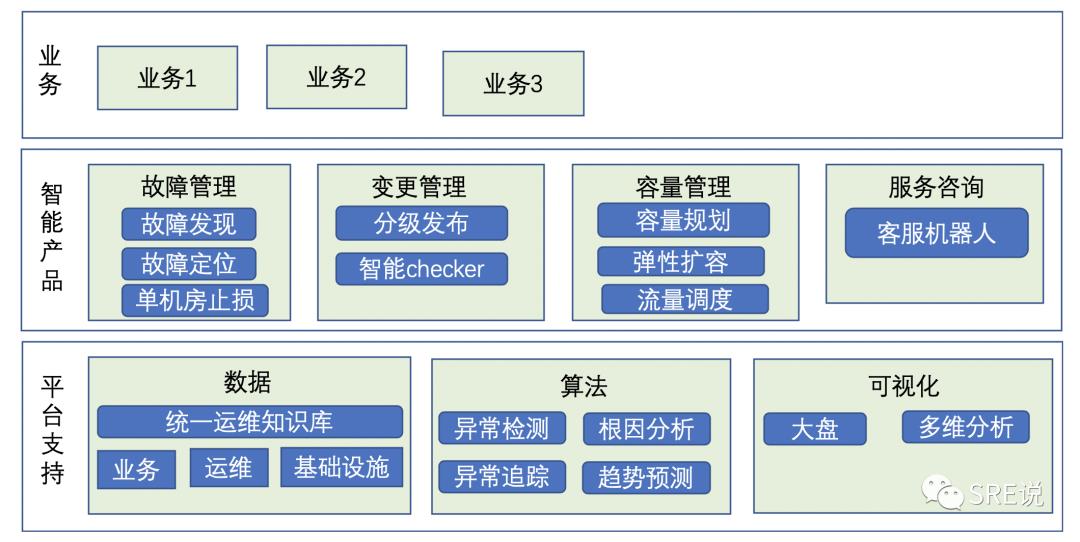
3.1 故障管理
尽管各类运维监控工具使系统运行状态的可见度有了较大的提升,但是当遇到突发业务故障时,面对海量监控数据和庞大复杂的分布式系统,当前仍主要依赖运维及研发人员在高压下人工做出故障判别、定位及决策。
目前主要依赖于通用可视化平台构建的数据看板,来进行业务态势感知和展示,各类监控曲线的波动变化均依赖人工识别异常;如果曲线同环比波动不明显,非常容易忽略、遗漏相关异常信息。
3.2 变更管理
目前的上线虽然有检测项但是都是靠人工来检测,而且各个研发同学对其他人的指标的理解程度也不一样无法准确的判断,更关键的是如果指标太多会影响上线的效率,因此需要做全面的检测就必须有相关的智能化的支持。
3.3 容量管理
第一 资源预估:管理容量就是为了让业务能有足够的资源来承担流量增加,判断按照当前的增长,多长时间需要是否扩容 ,判断当前的流量曲线是否有异常,同时防止退化
第二 服务编排,如何部署服务更加合理,如果是容器服务需要考虑,cpu、内存、磁盘等不同服务的不同部署方案
第三 释放人力 ,目前的容量评估和机器分配,都是靠人工来评估,会消耗大量的人力
第四 提前预估,节假日活动的容量评估,需要根据前一年的数据来做预估
第五 预算采购:在预算采购提交过程及时评估容量的增长情况,跟用户增加是否一致
4. 落地方案
4.1 故障管理
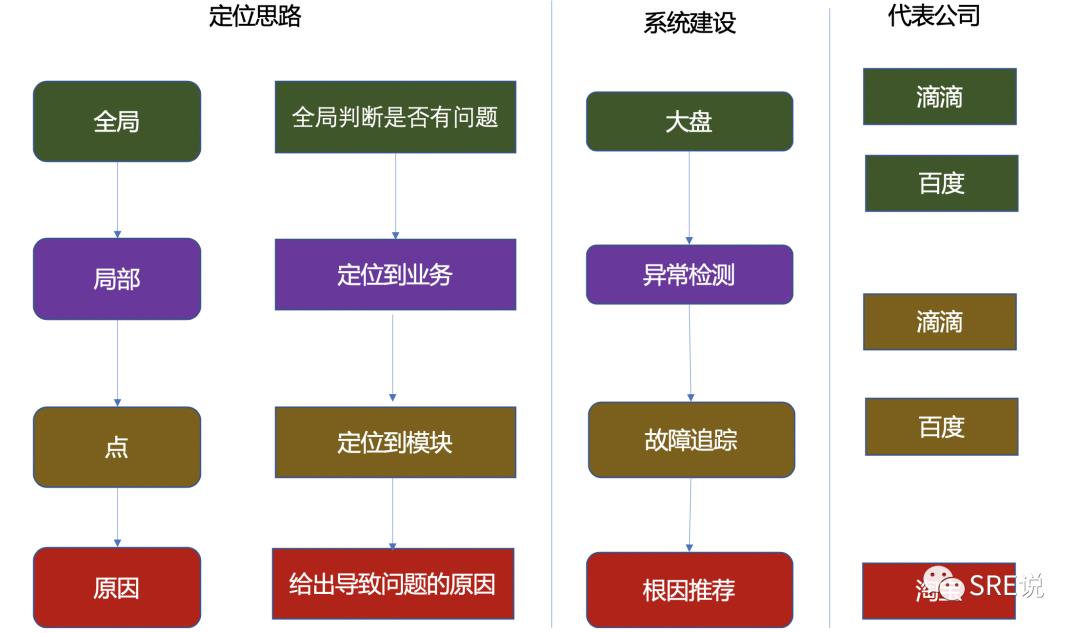
整体分为四个步骤 :定位大盘、异常诊断、模块追踪、根因推荐
首先是可视化展示:缩短人为的信息获取时间
把所有关键信息进行集中的抽象和汇总,可以通过大盘来以全局的视角观察业务全貌,覆盖从网络、接入、后端观察整体的健康状态。这一部分可以缩减故障定位50%左右的时间。业界的代表公司滴滴、美团等的监控大盘的建设都比较成熟。
第二是异常诊断:缩短异常服务的判断时间和异常信息的提取时间
通过异常诊断算法来智能判断当前的服务是否正常,自动化判断影响程度,加快决策时间,并减少人为原因导致的信息遗漏等问题。诊断的来源主要是依托第一步大盘的里面的数据做出相关判断和决策,少量的线下数据输入作为补充。
第三是自动定位故障点:缩短上下游服务关联关系的整理,并加快追踪到异常模块
线上故障一旦爆发,有问题的服务是一个局部性的,不会是孤立的,需要快速找到爆发点,由于服务上下游的关联联系是一个网状结构,信息是指数级的,快速整理这些关系获取异常信息,提取相同特征(比如相同的网段、相同的下游服务等)。并根据这些信息以及上下游关联根据模块追踪的相关算法快速捕获到根因模块。
第四点根因推荐:缩短可疑事件的提取和过滤的时间
可疑事件的来源很多,包括网络变更、机房变更、代码变更、AB测试、配置变更、上下游服务的变更等等。根据时间、业务拓扑、人工经验把可疑事件按照加权并推荐出来。业界代表公司阿里,目前已经在淘宝等部门有了成熟的应用,这个需要长期的标注和模型的训练才能达到一个比较好的效果。
4.2 容量管理
第一:容量收集、计算、展示,这个也是最关键的,
收集:需要把业务的容量数据统一收集,比如qps、cpu、内存等等跟容量相关的数据。
计算当前容量的水位,水位的表示有很多,比如cpu、内存等等目前业界主流就是CPU
展示,实时展示
第二容量的预测
节假日容量的预估
来年的容量预估
第三容量规划
基础设施的规划等等,不过很少有公司和业务能达到这一步,主要是规划都是从下到上;一般都是idc买好机房业务在按照idc的来部署
4.3 变更管理
这是一个通用的技术方案,当然可以按照自己的顺序来变更,这里强调的是要有变更检查能力,和快速止损的能力。
这里有个前提是需要做好机房隔离
智能检查
分级发布的一个核心点是,必须要做大量的检查,这样就会给上线效率造成很大的影响,因为可能是多人ci,一个人上线,那么这个上线的同学可以不清楚别人业务的指标是否正常,是否检查完整性会有大打折扣,另外,检查必然会有大量的时间浪费,那么是否可以有一个工具来实现所有指标的自动化和智能化检查呢。这个就是智能检查的出现
智能在哪里呢,异常指标的判断,一个上线可能有几百上千的指标,不可能去定义每个指标的检查算法,那么这个智能检查就会集成一些默认算法指标,以及上下游的服务。
智能检查-实现方案
智能checker
分级发布在推动过程中可能遇到很大的难度,很多研发同学可能觉得这个检查是一个比较耗时的事情。checker与AI的结合就是智能checker,解决这种不是明确指标阈值的情况。比如曲线波动等情
5 总结
AIOps是一个非常活动的理念,需要机器学习、大数据处理、业务理解、SRE定位能力等配合也是将来的一个方向。所以对于传统的SRE来说必须掌握一些机器算法、算法处理、数据处理等技能。
(注:有些图片来自aiops白皮书)
以上是关于AIOps思考的主要内容,如果未能解决你的问题,请参考以下文章