资源 | 在TensorFlow 1.0上实现快速图像生成算法Fast PixelCNN++
Posted 机器之心
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了资源 | 在TensorFlow 1.0上实现快速图像生成算法Fast PixelCNN++相关的知识,希望对你有一定的参考价值。
选自GitHub
机器之心编译
参与:Jane W、吴攀
近日,伊利诺大学香槟分校的研究者在 GitHub 上发布了一个快速图像生成算法 Fast PixelCNN++的实现,该算法的相关论文已被提交到 ICLR 2016。
我们通过利用缓存避免冗余计算而实现了对图像生成算法 PixelCNN++ 的加速。原始的生成算法丢弃了可以重复利用的计算,并且还会占用不用于生成特定像素的附加计算资源。原始的算法在 Tesla K40 GPU 上生成 16 张 32x32 的图像可能需要长达 11 分钟。通过重新使用之前的计算并且仅执行所需的最小计算量,我们实现了相比原始生成算法高达 183 倍的加速。
如何运行
我们用 Python 3 和 TensorFlow 1.0 测试了我们的代码。对其它版本的 Python 或 TensorFlow 可能需要稍作更改。
运行指南:
安装 TensorFlow 1.0、Numpy 和 Matplotlib
下载并解压 OpenAI 预训练的 PixelCNN++ 模型(http://alpha.openai.com/pxpp.zip)。解压后,有一个名为 params_cifar.ckpt 的文件。
设置参数 CUDA_VISIBLE_DEVICES = 0 运行脚本 python generate.py——checkpoint = /path/to/params_cifar.ckpt——save_dir = /path/to/save/generated/images
该脚本将不断地循环生成图像,并将图像保存到——save_dir。你可以随时通过使用 Control-C 中断退出该脚本。
算法原理
什么是 PixelCNN++,为什么要使用它?
PixelCNN++ 是一个生成模型,它使用所有先前生成的像素作为信息生成下一个像素。也就是说,为了生成图像中的第 10 个像素,PixelCNN++ 将查看像素 1-9 来对像素 10 的输出分布建模:P(像素 10 |像素 1,..., 像素 9)。类似地,像素 11 将查看像素 1-10,继续这个过程直到对所有像素建模。这个特性使 PixelCNN 是一个自回归(autoregressive)模型,其中每个像素由先前像素的历史建模。使 PixelCNN 独一无二的是,该算法使用巧妙、快速的方法来集合来自先前像素的信息,这对于训练速度至关重要。
PixelCNN 是由 DeepMind 最初开发的(https://arxiv.org/abs/1606.05328),并得到了 OpenAI 的改进而得到了 PixelCNN++(https://openreview.net/pdf?id=BJrFC6ceg)中进行了改进。这些模型已经在各种图像生成基准(image generation benchmark)上实现了当前最佳的结果。这些模型可以直接用来训练,有强大的应对复杂的输入建模的能力,并能够产生清晰,有吸引力的图像。例如,PixelCNN 最近已被用于图像超分辨率(superresolution)(https://arxiv.org/abs/1702.00783)。
与其它的生成模型(如生成对抗网络(Generative Adversarial Network)和变自编码器(Variational Autoencoder))相比,自回归模型的主要缺点之一是自回归模型必须一次产生一个像素,而其它方法可以一次产生整个图像。我们的方法加速了 PixelCNN 的生成过程。
加速一个带有膨胀系数(dilation)的简单的 1 维例子
在介绍加速 PixelCNN 的细节之前,让我们关注一个更简单的 1 维自回归模型:Wavenet(https://arxiv.org/abs/1609.03499)。这里提供的细节类似于 GitHub 上的 Fast Wavenet(https://github.com/tomlepaine/fast-wavenet),你可以参考更多的详细内容。
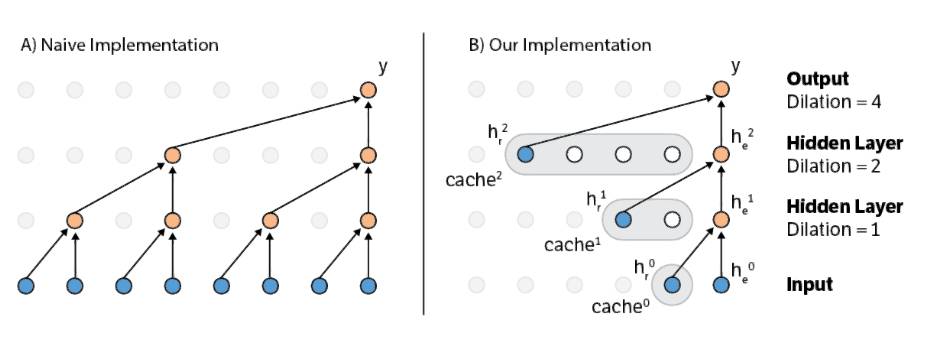
Wavenet 图(左边)看起来像一个二叉树(binary tree)。一个节点与它之前的第 n 个的邻居计算卷积(convolve),其中 n 是 2 的幂。由于 n(膨胀系数/ dilation)每经过 2 层就会增加,组合在一起的节点的范围(感受野/ receptive field)也呈指数增长。在每个生成步骤,来自感受野中的所有节点(图片中的 8)的信息必须被组合。原始的生成算法在每个生成步骤简单地重复着整个计算树。这很容易实现,但是很慢。
你可能已经注意到,当生成连续输出时,树的大部分被重复使用。例如,调用图片 t 中的当前步骤,并假设生成 t+2 的输出。在这种情况下,第一隐藏层中的四个橙色节点中的三个可以被重复使用!重新计算它们纯属浪费时间。
这启发了我们算法的核心:缓存以前计算的隐藏状态(hidden state)。如右图所示,我们为每个层保留以前计算的隐藏状态的缓存。缓存的大小等于隐藏层的膨胀系数,因为模型必须在隐藏层回溯 n 步。缓存像一个队列:最早的隐藏状态从队列的前面弹出,这完全等同于正常的膨胀卷积(dilated convolution)。在计算隐藏状态之后,必须将其推入队列的后面,因此从现在开始正好有 n 个步骤。重复这个过程给出了一个加速生成算法,它避免了原始方法的大量计算。
加速跨度卷积(strided convolution)
前一部分使用了带有膨胀系数的卷积。在这种情况下,节点 t 与节点 t-n 计算卷积,节点 t+1 与节点 t+1-n 计算卷积。这意味着一个层中的隐藏状态的数量等于输入的数量,使得能够直接利用缓存。然而,使用跨度卷积使问题更加困难,因为隐藏层中的状态数量与输入数量不同。
跨度卷积是下采样层(downsampling layer)。这意味着隐藏状态少于输入。典型的卷积在局部邻域(local neighborhood)上进行卷积计算,然后移动 1 个位置并重复该过程计算。例如,节点 t-1 和 t 将计算卷积,然后节点 t 和 t+1 将计算卷积。跨度会影响卷积移动经过的位置的数量。在前面的例子中,跨度为 1。然而,当跨度大于 1 时,输入将被下采样。例如,当跨度为 2 时,因为卷积移动 2 个位置,节点 t-1 和 t 将计算卷积,然后节点 t+1 和 t+2 将计算卷积。这意味着该层的每对输入仅产生一个输出,因此隐藏状态的数量小于输入的数量。
类似地,还有上采样层(upsampling layer),它是跨度转置卷积(strided transposed convolutions)。跨度记为 s,即上采样层将为该层的每个输入产生 s 个输出。与传入该层的输入数量相比,这增加了隐藏状态的数量。PixelCNN++ 先使用 2 个下采样层,然后使用 2 个上采样层,每个上采样层的跨度为 2,这意味着生成的像素的数量与输入像素的数量相同(即 D/2/2*2*2 = D)。关于跨度和转置卷积的详细解释可以在这两个链接中找到:https://github.com/vdumoulin/conv_arithmetic 和 https://arxiv.org/abs/1603.07285
由于隐藏状态的数量不同,因此无法在每个时间步骤(timestep)中更新缓存。因此,每个缓存都有一个附加属性 cache every,缓存每次只在 cache every 的步骤更新。每个下采样层通过增加跨度来增加该层的 cache every 属性。相反,每个上采样层通过减少跨度来减少该层的 cache every 属性。
上图显示了一个具有 2 个上采样层和 2 个下采样层的模型示例,每个采样层的跨度为 2。橙色节点在当前的时间步骤计算,蓝色节点是先前的缓存状态,灰色节点不参与当前的时间步骤。
在第 1 个时间步骤 t=0,第 1 个输入用于计算和缓存所有节点,这里有足够的信息生成节点,包括前 4 个输出。
在 t=1 时,节点没有足够的信息用来计算,但是 t=1 的输出已经在 t=0 时算出。
在 t=2 时,有 1 个新节点有足够的信息来计算,虽然 t=2 的输出也在 t=0 时算出。
t=3 的情形类似于 t=1。
在 t=4 时,有足够的信息来计算多个隐藏状态并生成接下来的 4 个输出。这类似于 t=0 的情形。
t=5 类似于 t=1,并且该循环过程适用于所有未来的时间步骤。
在我们的代码中,我们还使用一个属性 run every,等同于下一层的 cache every 属性。这在如果下一层忽略输入时避免了计算。
加速 PixelCNN++
在理解了前面的部分之后,我们将 1 维的例子直接推广到 2 维。事实上,我们的推广算法只有很少的变化。现在,每个层的缓存是 2 维的,缓存的高度(height)等于过滤器(filter)的高度,缓存的宽度(width)等于图像宽度。在生成整个行之后,将弹出缓存中最早的一行,并推送入新的一行。因为使用了大量的卷积,我们使用上一部分中详述的 cache every 的想法。
PixelCNN 有两个计算流:垂直流(vertical stream)和水平流(horizontal stream)。将细节稍微简化一下,垂直流查看当前像素上方的所有像素,而水平流查看当前像素的左边相邻的所有像素,它满足 2 维情况下的自回归属性(参见 PixelCNN 论文以获得更精确的解释)。水平流也能把垂直流作为输入。在我们的代码中,我们一次计算一行的垂直流,缓存并使用它来一次计算一个像素的水平流(和生成的输出)。
有了这一点,我们能够实现 PixelCNN++ 生成的数量级加速!下图中增加的批处理大小(batch size)表明我们方法的可扩展性。虽然初始方法的实现结果随批处理大小呈线性扩展(由于 100%的 GPU 利用率),因为最小计算要求,我们的方法具有优越的扩展(scaling/时间复杂度)性能。
PixelCNN++ 延伸
这里详述的核心概念很容易推广不同的模型。例如,直接运用于加速视频像素网络(https://arxiv.org/abs/1610.00527),并且由于更高的计算需求,可能会产生更好的加速效果。我们期待你对卷积自回归模型的快速生成的实际运用!
作者
Prajit Ramachandran (https://github.com/PrajitR)
Tom Le Paine (https://github.com/tomlepaine)
Pooya Khorrami (https://github.com/pkhorrami4)
Mohammad Babaeizadeh (https://github.com/mbz)
如果你觉得这个项目有用,请引用我们已提交 ICLR 2017 的论文《FAST GENERATION FOR CONVOLUTIONAL AUTOREGRESSIVE MODELS》:
@article{ramachandran2017fastgeneration,
title={Fast Generation for Convolutional Autoregressive Models},
author={Ramachandran, Prajit and Paine, Tom Le and Khorrami, Pooya and Babaeizadeh, Mohammad and Chang, Shiyu and Zhang, Yang and Hasegawa-Johnson, Mark and Campbell, Roy and Huang, Thomas}
year={2017}
}✄------------------------------------------------
加入机器之心(全职记者/实习生):hr@jiqizhixin.com
投稿或寻求报道:editor@jiqizhixin.com
广告&商务合作:bd@jiqizhixin.com
以上是关于资源 | 在TensorFlow 1.0上实现快速图像生成算法Fast PixelCNN++的主要内容,如果未能解决你的问题,请参考以下文章
教程 | 使用MNIST数据集,在TensorFlow上实现基础LSTM网络