干货 | 移动设备上实现“诗人也能用TensorFlow”
Posted 新智元
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了干货 | 移动设备上实现“诗人也能用TensorFlow”相关的知识,希望对你有一定的参考价值。
1 新智元推荐
来源:oreilly data
新智元获授权转载
新智元启动新一轮大招聘:COO、执行总编、主编、高级编译、主笔、运营总监、客户经理、咨询总监、行政助理等 9 大岗位全面开放。
简历投递:jobs@aiera.com.cn
HR 微信:13552313024
新智元为COO和执行总编提供最高超百万的年薪激励;为骨干员工提供最完整的培训体系、高于业界平均水平的工资和奖金。
加盟新智元,与人工智能业界领袖携手改变世界。
【新智元导读】 手机上实现TensorFlow模型,分步骤解说。
编者注:本文原始刊登在Pete Warden的博客里, 授权转载于此。
在《诗人也能用TensorFlow》那篇博文中,我介绍了如何使用你自己的图片来训练一个可识别图片对象的神经网络模型。接下来就是将这个模型运用到你的移动设备中。在这篇文章中,我会介绍如何在你的 ios 应用程序中运行这个模型。
你可以在本文中找到书面指南,也可以通过下面的视频及注解了解详细的操作步骤。
我假定你已经完成了《诗人也能用TensorFlow》的步骤。 所以你应该已经安装了Docker, 并在home路径下创建了一个tf_files的文件夹。这个文件夹里有一个包含你的模型的retrained_graph.pd文件。 如果你还没有完成以上步骤,你需要按照《诗人也能用TensorFlow》教程示例来完成你自己的模型训练。
第一步,打开Docker QuickStart Terminal并利用最新的Docker镜像启动一个新的Docker容器。 本教程依赖了一些TensorFlow的新特性,所以用于《诗人也能用TensorFlow》的v0.8版镜像不能用了。
docker run -it -p 8888:8888 -v $HOME/tf_files:/tf_files tensorflow/tensorflow:nightly-devel
你应该可以看到自己在一个新的shell窗口中,提示符以“root@”开头,以“#”结尾 ,这表示你已经运行在Docker镜像中了。为了确保设置正确,请运行ls -lah /tf_files/,并确认已生成了retrained_graph.pb文件。
接下来,首先我们要确保此模型能够产生合理的结果。在这里我使用默认的花朵图像来做测试。但如果你已经训练了自定义类别,可以用你自己的图像文件来代替。整个编译过程可能需要几分钟。如果运行速度太慢,请确认你已经更新了VirtualBox的配置来充分利用计算机内存和处理器能力。
cd /tensorflow/
bazel build tensorflow/examples/label_image:label_image
bazel-bin/tensorflow/examples/label_image/label_image \
–output_layer=final_result \
–labels=/tf_files/retrained_labels.txt \
–image=/tf_files/flower_photos/daisy/5547758_eea9edfd54_n.jpg \
–graph=/tf_files/retrained_graph.pb
对于花朵顶部是雏菊的图片,这个模型应该可以给出一个合理的第一选择标签。在我们对模型文件进行进一步处理以便其能在移动应用程序中使用后,我们还会使用此命令来确保它仍然能得到合理的结果。
移动设备的内存容量有限,而且应用程序需要下载到设备本地运行。因此在默认情况下,TensorFlow的iOS版本仅包含支持接口中常见的运算的代码,并不包含很多的外部依赖性包。你可以在tensorflow/contrib/makefile/tf_op_files.txt文件中查看此版本所支持的运算列表。其中一个不支持的运算是DecodeJpeg,因为对它的实现依赖于libjpeg(这很难在iOS中支持),并且会增加编译后代码的大小。
虽然我们可以编写一个使用iOS原生的图像库的新的实现方法,但是对于大多数移动应用程序,我们不需要解码JPEG图像。因为我们可以直接使用相机的图像缓冲区。
不幸的是,我们重新训练所基于的Inception模型包括一个DecodeJpeg运算。我们一般通过在解码之后直接反馈Mul节点来绕过这一运算。但是在不支持该运算的平台上,即使从未调用它,也会在加载图像时发生错误。为了避免这种情况的出现,optimize_for_inference脚本里删除了输入和输出节点集合中不需要的所有节点。
该脚本还做了一些其他优化以提高运行速度。例如它把显式批处理标准化运算跟卷积权重进行了合并,从而降低了计算量。运行方式如下:
bazel build tensorflow/python/tools:optimize_for_inference
bazel-bin/tensorflow/python/tools/optimize_for_inference \
–input=/tf_files/retrained_graph.pb \
–output=/tf_files/optimized_graph.pb \
–input_names=Mul \
–output_names=final_result
这将在/tf_files/optimized_graph.pb中创建一个新文件。想确认它没有更改网络输出,可以在更新的模型上再次运行label_image命令对样例图片进行识别。
bazel-bin/tensorflow/examples/label_image/label_image \
–output_layer=final_result \
–labels=/tf_files/retrained_labels.txt \
–image=/tf_files/flower_photos/daisy/5547758_eea9edfd54_n.jpg \
–graph=/tf_files/optimized_graph.pb
你应该可以看到跟第一次对图片进行识别非常类似的结果,因为不管对模型的处理流程作出什么更改,其底层的数学运算结果是应该一致的。
重新训练后的模型仍然是87MB。这导致了任何包含它的应用程序的下载包都会很大。有很多方法可以减少下载包的大小,但有一个方法非常简单有用,并且不会增加太多的复杂性。Apple使用.ipa包发布应用程序,其中所有的内容都使用zip压缩。
通常因为权重都是略微不同的浮点值,所以模型不能被很好地压缩。但是你可以通过将特定常数范围内的所有权重凑整到256个级别,同时仍然保持浮点格式,从而实现更好的压缩比。
应用以下这些改进:给予压缩算法更多可利用的重复性;不需要任何的新算子;并且仅略微降低精度(通常降低小于1%的)
以下是如何调用quantize_graph脚本以应用这些改进的方法:
bazel build tensorflow/contrib/quantization/tools:quantize_graph
bazel-bin/tensorflow/contrib/quantization/tools/quantize_graph \
–input=/tf_files/optimized_graph.pb \
–output=/tf_files/rounded_graph.pb \
–output_node_names=final_result \
–mode=weights_rounded
你会发现rounded_graph.pb文件的原始大小仍然是87MB。但是如果你在Finder(资源管理器)中右键单击它,并选择“压缩”,应该可以看到生成了一个大小约24MB的压缩文件。 这个差异就是iOS压缩的.ipa文件或者android压缩的.apk文件和原始文件(未压缩过)大小的差异。
为了验证模型仍然正常工作,请再次运行label_image命令:
bazel-bin/tensorflow/examples/label_image/label_image \
–output_layer=final_result \
–labels=/tf_files/retrained_labels.txt \
–image=/tf_files/flower_photos/daisy/5547758_eea9edfd54_n.jpg \
–graph=/tf_files/rounded_graph.pb
这一次,评分的结果有稍微明显的变化(由于量化的影响),但是标签的总体个数和顺序应该与之前两次运行的结果是相同的。
我们需要运行的最后一个处理步骤是内存映射。因为保存模型权重值的缓冲区大小为87MB,所以在需要将这些权重内容载入应用程序使用的内存时,甚至在运行模型之前,就会对iOS的内存空间造成很大的压力。这会导致稳定性出问题,因为操作系统可能会无预兆地杀掉使用太多内存的应用程序。幸运的是这些缓冲区是只读的,因此可以将这些内容映射到内存中,以便操作系统可以在有内存压力时轻松地丢弃它们,从而避免崩溃的可能。
为了支持这一点,我们需要重新整理模型,使权重值能够被保存在可以轻松地跟主GraphDef分开加载的部分,即使它们仍然在同一个文件中。以下是操作命令:
bazel build tensorflow/contrib/util:convert_graphdef_memmapped_format
bazel-bin/tensorflow/contrib/util/convert_graphdef_memmapped_format \
–in_graph=/tf_files/rounded_graph.pb \
–out_graph=/tf_files/mmapped_graph.pb
要注意的一点是,磁盘上的文件不再是一个普通的GraphDef protobuf。所以如果你尝试加载到一个像label_image这样的程序中,将会发生错误。你需要稍微改变一下加载模型文件的方法,下面我将会介绍在iOS上的一个应用例子。
到目前为止,我们已经在Docker上运行了所有的脚本。出于演示的目的,在Docker中运行脚本要容易很多,因为在Ubuntu上安装Python依赖包比在OS X上更加简单。
现在,我们将切换到本机终端,以便我们可以编译一个使用你训练的模型的iOS应用程序。
你需要安装Xcode7.3或者更高版本的命令行工具来开发编译应用程序。你可以从Apple官网上下载Xcode。完成安装后,打开一个新的终端窗口,下载TensorFlow源码(使用git clone https://github.com/tensorflow/tensorflow命令)到你本机的一个文件夹中。请把下面命令里的“〜/ projects / tensorflow”替换为该文件夹路径,然后运行以下命令编译Tensorflow框架并把模型文件复制过来:
cd ~/projects/tensorflow
tensorflow/contrib/makefile/build_all_ios.sh
cp ~/tf_files/mmapped_graph.pb tensorflow/contrib/ios_examples/camera/data/
cp ~/tf_files/retrained_labels.txt tensorflow/contrib/ios_examples/camera/data/
open tensorflow/contrib/ios_examples/camera/camera_example.xcodeproj
检查终端输出的结果以确保编译成功。这时你应该可以找到可以在Xcode中打开的相机示例项目。这个应用程序显示了你的相机的实时拍摄的内容,以及它可以识别的内容里的对象的标签,所以它是一个很好的用来测试新模型的演示项目。
上面的命令应该已经将你需要的模型文件复制到应用程序的数据文件夹中了,但是你仍然需要让Xcode知道应该将这些文件包含在应用程序中。要删除相机项目的默认模型文件,请在Xcode的左侧项目导航器中,在数据文件夹中选中imagenet_comp_graph_label_strings.txt和tensorflow_inception_graph.pb文件。删除它们,并在删除提示中选择“移至垃圾箱”。
接下来,打开一个包含新模型文件的Finder窗口,例如在命令行终端中做如下操作:
open tensorflow/contrib/ios_examples/camera/data
将mmapped_graph.pb 和retrained_labels.txt 从该Finder窗口拖动到项目导航器中的数据文件夹中。确保在对话框的复选框中为CameraExample启用了“添加到目标”。这可以在你编译应用程序时,让Xcode知道它应该包括这些文件。所以如果在后面步骤中你看到了文件丢失的错误信息,请仔细检查这一步骤。
图1 添加文件对话框,显示要选择的选项。图片由Pete_Warden友情提供
我们已经有了应用程序中的文件。现在需要更新一些其他信息。我们需要更新加载文件的名称,还有一些元数据,包括输入图像的大小、节点名称以及如何在加载图像之前对像素值进行数值压缩。要进行这些更改,在Xcode里打开CameraExampleViewController.mm,查找靠近文件顶部的模型设置部分,并用以下内容替换它们:
C++
// If you have your own model, modify this to the file name, and make sure
// you’ve added the file to your app resources too.
static NSString* model_file_name = @”mmapped_graph”;
static NSString* model_file_type = @”pb”;
// This controls whether we’ll be loading a plain GraphDef proto, or a
// file created by the convert_graphdef_memmapped_format utility that wraps a
// GraphDef and parameter file that can be mapped into memory from file to
// reduce overall memory usage.
const bool model_uses_memory_mapping = true;
// If you have your own model, point this to the labels file.
static NSString* labels_file_name = @”retrained_labels”;
static NSString* labels_file_type = @”txt”;
// These dimensions need to match those the model was trained with.
const int wanted_input_width = 299;
const int wanted_input_height = 299;
const int wanted_input_channels = 3;
const float input_mean = 128.0f;
const float input_std = 128.0f;
const std::string input_layer_name = “Mul”;
const std::string output_layer_name = “final_result”;
最后,选择并连接并你的iOS设备(这个不能在模拟器上运行,因为它需要一个摄像头)到本机,并且按Command+R键来编译和运行修改后的示例。如果一切正常,你应该会看到应用程序启动,实时显示摄像头拍摄的内容,并开始显示你的训练类别的标签。
你可以找一个想识别的对象类型的东西用来测试。把相机对准它,看看程序是否能够给出正确的标签。如果你没有任何实物对象,可以尝试在网络上搜索图像,并将相机对准你的计算机显示器。
恭喜你已经能够训练自己的模型,并在手机上运行它!
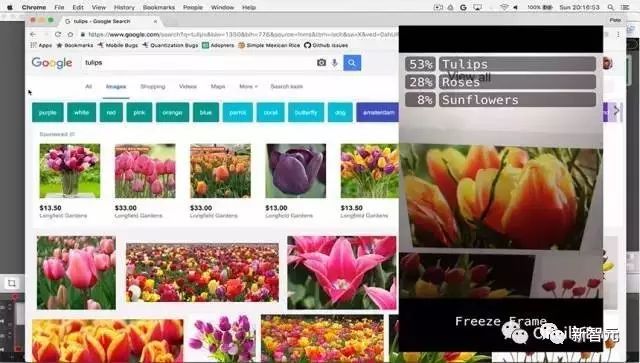
图2 郁金香的图片搜索结果与iPhone应用程序的屏幕。 图片由Pete Warden友情提供
上面步骤里的许多内容都可以被用于安卓系统或树莓派上,也包括TensorFlow提供的其他模型。它们可以被用于从自然语言处理到语音合成的多个方面。我很高兴看到在多种设备上出现了使用深不可测的深度学习的新应用程序,所以我迫不及待地想知道你搞出了什么新东西!
相关资料:
TensorFlow for poets
A poet does TensorFlow
Fundamentals of Deep Learning
Hands-On Machine Learning with Scikit-Learn and TensorFlow
Pete Warden
Pete Warden是TensorFlow移动团队的技术主管。在此之前,他是Jetpac的CTO。Jetpac于2014年被谷歌收购。它的深度学习技术经过优化,可在移动和嵌入式设备上运行。Pete曾在苹果公司从事图像处理的GPU优化工作,并为O'Reilly撰写了多本数据处理的书籍。
新智元招聘
职位 运营总监
职位年薪:36- 50万(工资+奖金)
工作地点:北京-海淀区
所属部门:运营部
汇报对象:COO
下属人数:2人
年龄要求:25 岁 至 35 岁
性别要求:不限
工作年限:3 年以上
语 言:英语6级(海外留学背景优先)
职位描述
负责大型会展赞助商及参展商拓展、挖掘潜在客户等工作,人工智能及机器人产业方向
擅长开拓市场,并与潜在客户建立良好的人际关系
深度了解人工智能及机器人产业及相关市场状况,随时掌握市场动态
主动协调部门之间项目合作,组织好跨部门间的合作,具备良好的影响力
带领团队完成营业额目标,并监控管理项目状况
负责公司平台运营方面的战略计划、合作计划的制定与实施
岗位要求
大学本科以上学历,硕士优先,要求有较高英语沟通能力
3年以上商务拓展经验,有团队管理经验,熟悉商务部门整体管理工作
对传统全案公关、传统整合传播整体方案、策略性整体方案有深邃见解
具有敏锐的市场洞察力和精确的客户分析能力、较强的团队统筹管理能力
具备优秀的时间管理、抗压能力和多任务规划统筹执行能力
有广泛的TMT领域人脉资源、有甲方市场部工作经验优先考虑
有媒体广告部、市场部,top20公关公司市场拓展部经验者优先
以上是关于干货 | 移动设备上实现“诗人也能用TensorFlow”的主要内容,如果未能解决你的问题,请参考以下文章
在移动设备上实现 DLNA/UPnP (Win7 Play To)
Forsta推出Digital Diaries移动应用,在桌面智能手机和平板电脑设备上实现无缝的消费者旅程和消费者画像捕捉