深度学习三人行(第2期)---- TensorFlow爱之再体验
Posted 智能算法
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了深度学习三人行(第2期)---- TensorFlow爱之再体验相关的知识,希望对你有一定的参考价值。
上一期,我们一起学习了TensorFlow的基础知识,以及其在线性回归上的初体验,该期我们继续学习TensorFlow方面的相关知识。学习的路上,我们多多交流,共同进步。本期主要内容如下:
梯度下降TF实战
模型保存和恢复
TensorBoard可视化
模块与共享变量
文末附本期代码关键字,回复关键字即可下载。
一. 梯度下降TF实战
11 TensorFlow直接计算
下面代码基本上函数都有接触过,其中tf.random_uniform()函数在图中创建一个包含随机值的节点,类似于NumPy中的random()函数。
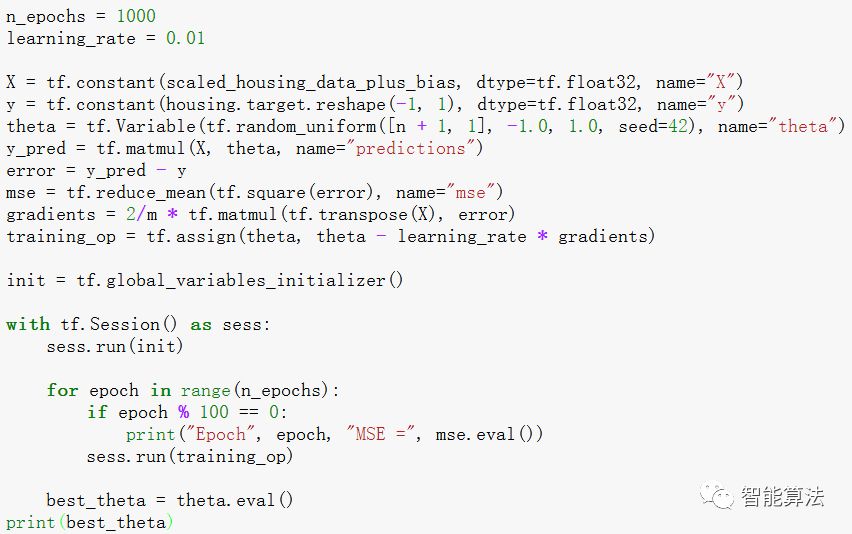
tf.assign()函数的作用是创建一个将新值赋给变量的一个节点,这里相当于执行如下迭代:
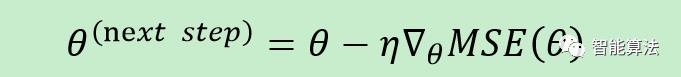
接下来就是不断迭代更新θ值,来我们看下迭代的最终结果:
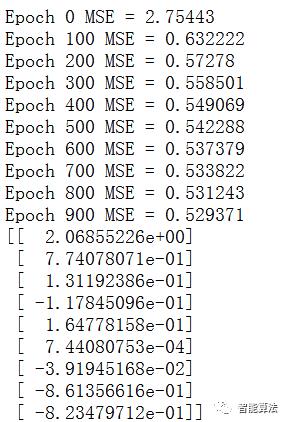
我们可以看到,每次迭代损失函数都在下降。
1.2 autodiff方法计算
上面的方法并没有什么问题,但是唯一不足的是需要数学推导梯度的损失函数公式。在线性回归中,这个是没问题的,但是如果在深度神经网络中,我们就死翘翘了,即使我们使用其他方法推出数学公式来运行,也不会得到高效的运行代码。外面只需要将下面的代码替换成上面的梯度公式即可:

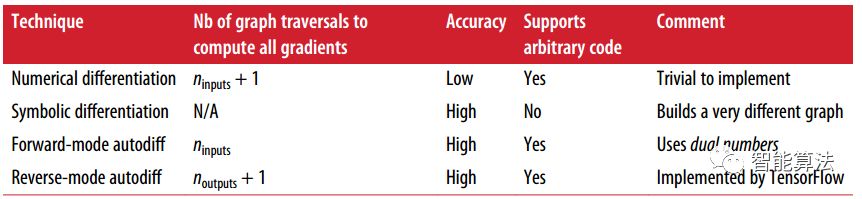
自动计算梯度一般有以下四种方法,TensorFlow用了reverse-mode autodiff方法,该方法特别适用于大量输入,少量输出的神经网络系统中。
1.3 优化器来计算
对于梯度下降法,TensorFlow还可以更简单一些,直接用优化器来做,如下代码:

而且,当我们想选择不同类型的优化器的时候,直接修改其中一行代码即可,比方说,我们想用一种收敛更快的方法矩优化(后面系列会有介绍)的话,那么我们只需要修改具体查看代码如下即可:

1.4 训练过程中传输数据
我们之前学习学习梯度下降的时候,学过一种叫做小批量数据梯度下降的方法,其基本思想就是不断输入小批量的数据进行梯度下降寻优(详情可见机器学习第五期 )。这里就牵涉到一个如何在训练过程中传输数据的问题,我们一起学习下。
要想在训练的过程中进行更新输入参数,最简单的方法是用placeholder节点,从字面意思我们也可以看出来,这种节点不参与计算,这种节点一般用在运行过程中进行传输训练数据,当然,如果在运行时没有对placeholder节点进行赋值的话,将会出现异常。既然我们知道了原理,那么我们看一下如何实现:

正如上面代码所示,我们创建placeholder节点是通过调用placeholder函数完成的,函数中我们需要说明tensor的数据类型,如上图,我们在图中并未对节点A进行数据传入,而是在计算B的时候通过feed_dict将数据A进行传入。为了实现我们的MBGD梯度下降算法,我们需要对之前代码进行稍微修改,如下:

首先就是在创建图的阶段,我们通过placeholder来修改X和y。然后再执行阶段通过feed_dict将X和y逐个的传入,如下图:

二. 模型保存和恢复
2.1 保存模型
当我们训练好一个模型之后,一般情况下都会保存下来,以备后面调用,或者在训练的过程中,我们有时候也希望将训练的中间结果保存下来,防止训练过程中断电等异常出现,避免重新训练,那么如何保存下来呢?
TensorFlow中保存模型还是比较简单的,我们只需要在创建图阶段创建一个Saver的节点,然后在执行阶段需要保存模型的地方调用Save()函数即可,如下代码:

从上面我们也可以看出,在构建图的结尾我们创建了saver节点(with语句前面),而在执行阶段中,if语句下面和最后一行代码的地方,我们调用了save函数来保存模型。保存在save函数的输入路径中。那么如何恢复呢?
2.2 模型恢复
恢复模型也很简单和保存一样在构建图的结尾创建一个saver节点,不同的是在执行阶段的开始,用restore()函数进行模型恢复,如下图:

默认情况下,保存和恢复模型是按照变量自有的名字来进行的,但是如果我们想更高级些的话,我们可以指定保存和恢复哪些变量,以及用什么名字来保存变量,如下:

我们将theta变量保存为weights名称。
其实在上面的保存过程中,saver默认将计算图也以.meta为后缀的文件保存起来了,当我们需要恢复计算图的时候,我们可以调用tf.train.import_meta_graph()函数来进行恢复,该函数自动将meta计算图加载到默认图中,如下:
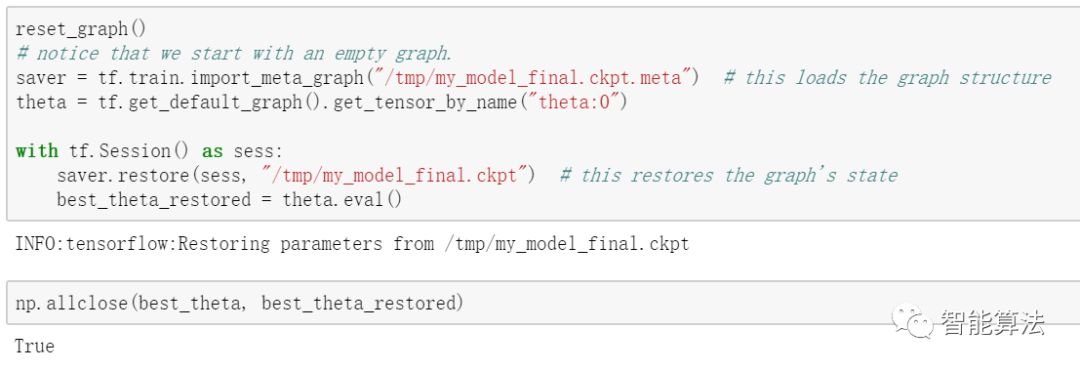
到目前为止,我们学习了构建计算图,以及利用MBGD的方法来进行线性回归。学习了如何保存和恢复模型。但是到目前为止,我们的输出信息还是依赖于print函数,有木有一种更好的可视化的方法呢?
三. TensorBoard可视化
我们可以通过TensorBoard来进行可视化训练过程,比如学习曲线等信息。对于诊断错误和发现模型瓶颈很有帮助,下面我们一起学习下如何玩转TensorBoard吧。
其实TensorBoard可视化训练过程是读取log信息的过程,那我们就需要将需要可视化的内容写成log存下来,然后调用TensorBoard进行读取显示。
比方说我们想看一下我们创建的图到底长什么样子,那么我们可以把这个图FileWriter把图存下来,如下:
其中logdir是保存路径。那么保存下来之后,如何用TensorBoard打开呢?
windws下,我们重新打开cmd,输入如下指令:
tensorboard --logdir =E://PyProjects//tf_logs//run-20180306133922
后面的路径是你log保存的路径,然后在浏览器中打开http://localhost:6006/#graphs,就可以看到我们代码中创建的图了,如下:
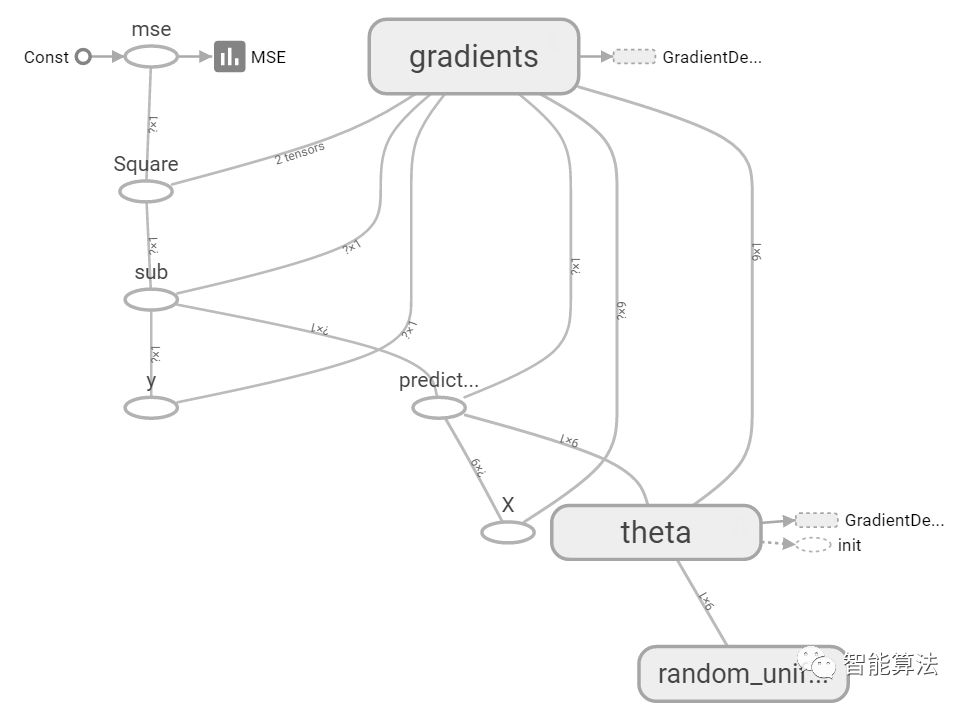
其中每个节点点开都会有关于该节点的输入输出等说明,如下:
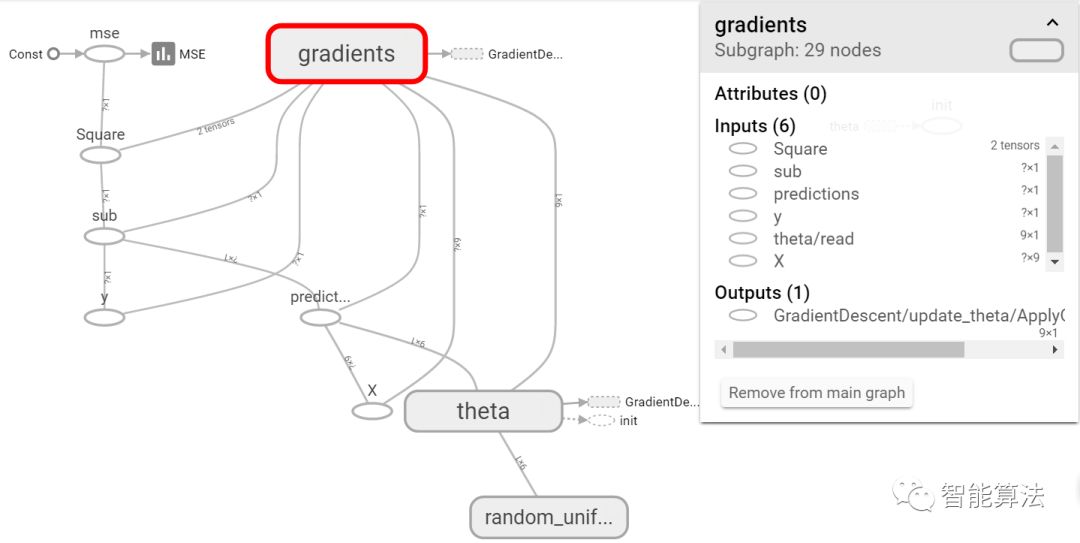
好了,至此我们学会了如何打开TensorBoard查看log,那我们看下基于MBGD的线性回归的学习曲线如何,如下:
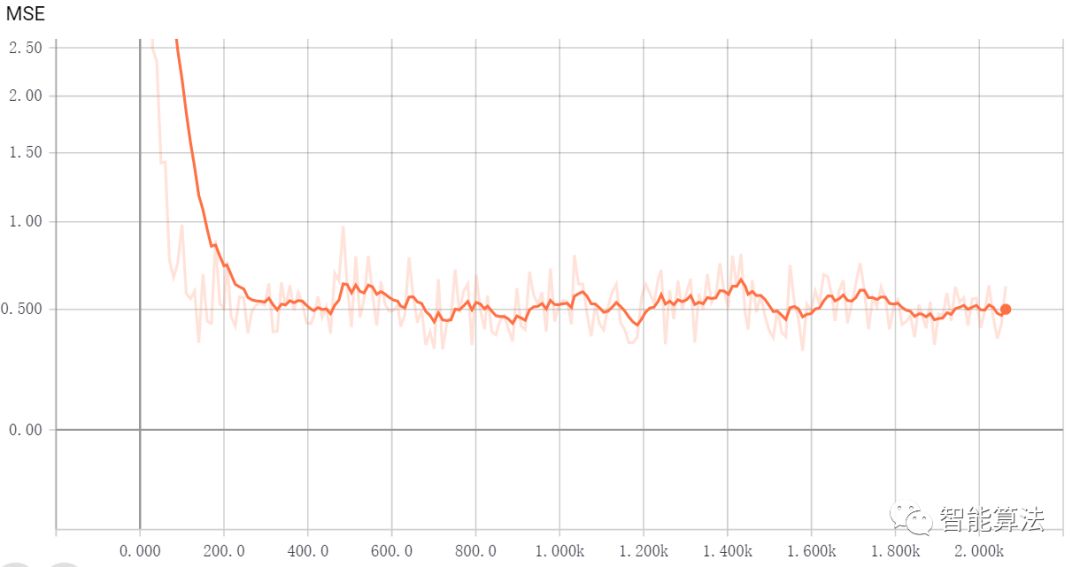
从学习曲线上可以看出来我们的MSE是成下降趋势的。关于TensorBoard的更多有趣的玩法,我们边学边探索。
四. 模块化与共享变量
4.1 节点分组
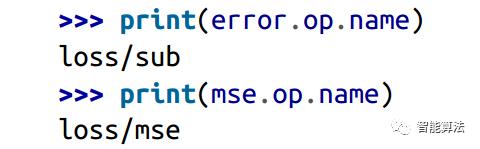
当我们处理比较复杂的模型的时候,比如神经网络的时候,计算图可能会有N多节点,为了避免节点混乱,我们可以对节点分组。比方说,我们要对前面代码中的error和mse进行分组为loss,那么我们可以code如下:

用with语句对ops进行分组,该op的名字前面会有一个组名的前缀如下:
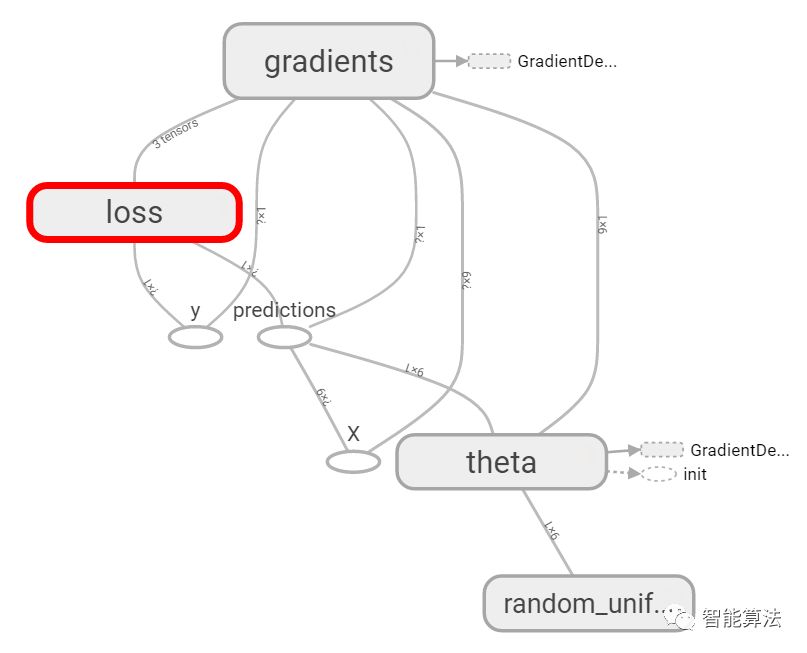
而在TensorBoard中mse和error也将会以loss的形式出现:
4.2 模块化
假如我们想创建一个图,并增加两个修正线性单元(ReLU),ReLU计算输入的线性加和,并且输出0和计算结果中的最大值,如下:
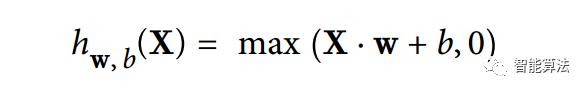
用代码实现,如下:

可以看出上面的代码是具有很大的重复性,这种代码很难维持,且容易出错,比方说上面代码中就有一个复制粘贴的错误,看出来了么?而且,如果我们想再增加一些ReLU的话,会显得很繁琐易错等,所以说我们需要避免这种类型的代码,我们可以对代码进行模块化封装,如下我们可以将ReLU封装如下:

这样,我们可以很easy的创建一堆ReLU,比方说5个,如下:

当然,我们也可以给这一堆relu进行前面介绍的命名分组,这样会显得更为简洁,尝试下吧。
4.3 共享变量
如果我们想在计算图的不同组件用同一个变量的话,一个简单的方法就是先创建这个变量,然后通过函数传到需要的地方,如下:

这样我们就做到了将threshold共享给所有的ReLU。也就是说,我们可以通过threshold来控制所有的ReLU了。这样做是没问题的,也实现了我们想要的功能。但是如果有很多的变量需要共享,按照这样的方式进行逐个传入的话,我们就会比较痛苦。有些人为了减轻这种痛苦,将众多共享变量封装成字典或者一个类传入函数中,这样是可以的。但是还有一种值得推荐的方法就是,将共享变量设置为函数的一个属性:

TensorFlow还提供了更为简洁和模块化的方法,那就是通过get_variable()进行创建一个共享变量(如果已经存在的话,就重新利用)。如下:

如果该变量之前已经通过get_variable()创建过了,那么此时就会出错。如果已经存在的话,我们可以通过设置变量范围的属性reuse为true来避免异常,如下:

或者在with语句块中,通过调用reuse_variables()函数。如下:

下面我们来看一下上述共享变量方法的完整代码,

上面的代码定义了relu函数,然后创建了共享变量threshold,最后通过函数内重新利用threshold创建了5个ReLUs。然而上面的代码中,我们在函数relu外面定义和初始化共享变量,那么能不能在函数里面进行定义共享变量呢?上代码如下:
上面创建5个ReLU的代码中保证了在创建第一个的时候resue=false,而后4个的时候resule=true保证了变量的共享。
五. 本期小结
至此,我们从TensorFlow直接计算梯度下降法入手,分别学习了autodiff方法,优化器的方法以及MBGD。接着为了利用训练好的模型,我们学习了模型的保存和恢复,之后我们又一起学习了TensorBoard来可视化我们的计算图和学习曲线等,最后,从节点分组下手,学习了代码的模块化和几种共享变量的实现。当然还有很多功能,我们边学边聊。
本文代码回复关键字:runtf2
以上是关于深度学习三人行(第2期)---- TensorFlow爱之再体验的主要内容,如果未能解决你的问题,请参考以下文章
学习看深度学习框架排名第一的TensorFlow如何进行时序预测!
第535期机器学习日报(2016-03-06) 深度学习框架大战正在进行,谁将夺取“深度学习工业标准”的荣耀?
第497期机器学习日报(2016-01-28) 深度学习框架的评估与比较
异周话题 第 18 期TensorFlow与PyTorch,深度学习框架你选哪一个?