Linux上TensorFlow的深入研究:构建一个低成本快速精准的图像分类器
Posted 大数据文摘
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Linux上TensorFlow的深入研究:构建一个低成本快速精准的图像分类器相关的知识,希望对你有一定的参考价值。
授权转载自OReillyData@Justin Francis
在过去的八个月里,我花了大量时间学习了尽可能多的机器学习知识。我经常对在这个小但快速成长的社区中的在线慕课(MOOCs)上遇到的各种各样的人感到惊讶。他们中既有费米实验室(Fermilab)的量子研究员,也有硅谷的CEO们。最近我一直关注开源软件TensorFlow,这篇教程就是我的研究成果。
我觉得很多机器学习教程都是面向Mac系统的。使用Linux系统的一个主要优势是它是免费的,并支持基于GPU的TensorFlow。GPU的并行加速计算能力是机器学习重大进步的原因之一。因此你不需要为了构建一个快速分类器而使用最前沿的计算设备,像我用的计算机和显卡总共花费了不到400美元。
在本教程中我会告诉你如何在Ubuntu上使用GPU来训练自己的图像分类器。本教程跟Pete Warden的《“诗人”也能用TensorFlow》非常类似,但是稍有不同。我会假定你已经安装了TensorFlow和Bazel,并在你的主目录下git克隆了最新版本的TensorFlow。如果你还没有完成上述工作,你可以按照我博客上的教程进行操作。如果你的计算机没有与TensorFlow兼容GPU,你仍然可以使用这个教程,只不过它需要更长的时间。
整个训练过程非常简单,可以分为四个主要步骤:
1. 收集训练用的图像。
2. 使用TensorFlow和Inception模型来训练一个计算图/模型。
3. 编写脚本来用你的计算图来进行图像分类。
4. 通过对新图像进行分类来测试脚本。
我决定使用五种不同的鸷鸟来训练我的图像分类器。使用鸷鸟并不是一个偶然的决定,我曾在不列颠哥伦比亚省邓肯市的“猛龙”机构工作了两年,这是一个教育中心及野生动物管理机构。长期以来我对这些凶猛的神话生物有着深厚的热情。作为终极挑战,我把我的分类器跟康奈尔大学鸟类实验室的Merlin ID工具系统进行对比。在本文的撰写过程中该实验室升级了它的网站并发布公告:“Merlin Photo ID 暂停使用以进行维护和升级。…康奈尔鸟类实验室和Visipedia团队正在合作研发可以识别照片中鸟类的计算机视觉技术”。毫无疑问,他们正在将他们的Merlin系统(现在不可用)升级为一个现代机器学习分类器。
收集训练用的图像
我从“猛龙”的脸书页面并结合网络搜索为每类鸷鸟收集了约100张图片。我找到了鸷鸟在许多不同的环境及地点的图片以建立图像集。为了使图像分类器有很好的泛化能力,至少用100张在不同的场景和背景中的图像用来训练它是比较理想的。还有一些方法可以扭曲现有的图像以得到更多的训练样本,但这可能会降低你的训练过程的速度。注意我们不需要用成千上万的样本来训练模型,这是因为TensorFlow会用Inception模型之前训练特征检测器来重新训练一个新模型。
我多做了一个实验,即让每种鸷鸟类图像样本的大约10%是幼鸟图像。我很好奇分类器是否可以找到一个幼鸟和成年鸟之间的相似之处。
一旦有了合适的图像数量和类型,我在我的TensorFlow目录下创一个文件夹:
$ cd ~/tensorflow
$ mkdir tf_files && cd tf_files && mkdir bird_photos && cd bird_photos
$ mkdir baldeagle goldeneagle peregrine saker vulture
我的目录结构如下图所示:

然后我将鸟类的图像集移动到相应的文件夹中。该脚本接受PNG、JPG、GIF和TIF类型图像,但我发现为了避免一个错误,我不得不重命名一个有很多符号的文件名。
训练模型
然后我使用克隆的TensorFlow源码中的内置python脚本训练了一个新模型和相关标签。我们用来重新训练的原始计算图是谷歌研究人员花费了两个星期在一台包含八个NVidia Tesla K40 GPU的计算机上训练得到的。
$ cd ~/tensorflow
$ python tensorflow/examples/image_retraining/retrain.py \
–bottleneck_dir=tf_files/bottlenecks \
–model_dir=tf_files/inception \
–output_graph=tf_files/retrained_graph.pb \
–output_labels=tf_files/retrained_labels.txt \
–image_dir tf_files/bird_photos
因为我安装的TensorFlow有GPU支持,所以训练模型用了不到10分钟。如果在我的旧Xeon CPU机器上进行这个训练,它可能需要花费一整天的时间。以下是训练结果:

图2 截图由Justin Francis友情提供
我的TensorFlow模型的最终测试精度为91.2%。考虑到我用了各种各样不同的图像,我觉得这个结果是非常令人惊喜的。
构建分类器
到目前为止我采用了原始计算图并用我自己的图片集重新训练。接下来我用Bazel构建了我自己的图像分类器,它是从TensorFlow git上克隆下来的。(不要关闭终端,否则你将需要重新构建)
$ bazel build tensorflow/examples/label_image:label_image
测试分类器
有趣的部分来了——对新的一组图像进行分类器测试。为了简便起见,我把我的测试图像放在我的tf_files文件夹中。
$ bazel-bin/tensorflow/examples/label_image/label_image \
–graph=tf_files/retrained_graph.pb \
–labels=tf_files/retrained_labels.txt \
–output_layer=final_result \
–image=tf_files/bird.jpg #This is the test image
首先我尝试分类一张我立即就能识别出为猎隼的图片:

图3 成熟的猎隼,来自维基百科的DickDaniels作品
TensorFlow也识别出来是猎隼!

图4 截图由Justin Francis友情提供
接下来我尝试了一张更复杂的且没有在我的训练数据集中出现的幼年游隼图片(下面左图)。幼年游隼的前面羽毛跟猎隼类似,但当它成年后会变成条纹状的腹部、黄色的喙和灰白色的下颈部。


图5 左图:幼年游隼,来自维基百科的Spinus自然摄影图像。右图:成年游隼,来自维基百科的Norbert Fischer作品
令我惊讶的是分类器能够以相当高的精确度识别出幼年游隼:

图6 截图由Justin Francis友情提供
我的最后一个例子使用了一张人类经常会错误分类的鸟类图片:幼年秃头鹰。人类经常会错误地认为它是一只金鹰,因为它的头部和尾部没有坚实的白色羽毛。我的训练分类器使用的训练图片约包含10%的幼鹰图片。

图7 刚刚会飞的幼年秃鹰,来自维基百科的KetaDesign作品
似乎我的分类器还不能超过鸟类学家的智力:

图8 截图由Justin Francis友情提供
我特别惊讶分类器的第二个猜测是“秃鹫”而不是“秃鹰”。这可能是因为我的很多秃鹫图片的拍摄角度跟秃鹰类似。
那Merlin系统怎么样?它的第一选择是正确的而第二选择也是非常合理的。
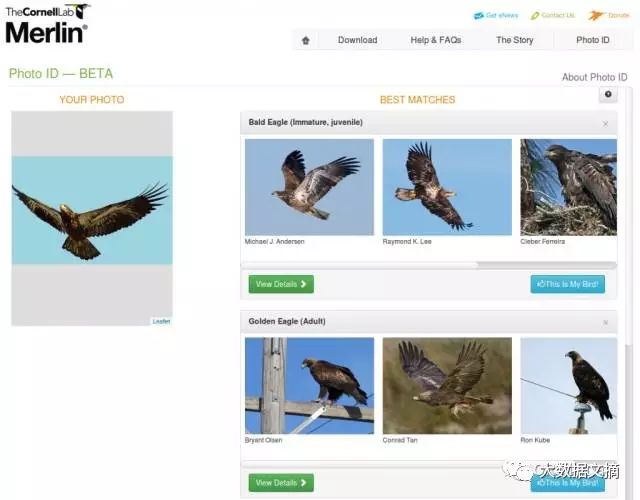
图9 截图由Justin Francis友情提供
Merlin系统只有在这张图片的分类上打败了我的分类器。但是如果有足够的训练数据,我完全相信我的分类器可以学会区别成年秃鹰、幼年秃鹰和金鹰。当然我需要一个单独的包含更多图片的幼年秃鹰文件夹。
我用这个分类器做了很多有趣的训练和实验。我希望这篇博文也能够帮你构建你自己的分类器。研究人员和爱好者的创造能力是无限的,请在Twitter上通过@wagonhelm或#TensorFlow标记我。
授权摘自OReillyData
关于转载
如需转载,请在开篇显著位置注明作者和出处(转自:大数据文摘 |bigdatadigest),并在文章结尾放置大数据文摘醒目二维码。无原创标识文章请按照转载要求编辑,可直接转载,转载后请将转载链接发送给我们;有原创标识文章,请发送【文章名称-待授权公众号名称及ID】给我们申请白名单授权。未经许可的转载以及改编者,我们将依法追究其法律责任。联系邮箱:zz@bigdatadigest.cn。
点击图片阅读文章
小白学数据之常用Python库“小抄表”(附小抄表PDF下载)
以上是关于Linux上TensorFlow的深入研究:构建一个低成本快速精准的图像分类器的主要内容,如果未能解决你的问题,请参考以下文章
深入浅出imx8企业级开发实战 | 04嵌入式Linux设备掉电数据容错研究
Elasticsearch:构建机器学习模型:深入研究监督学习管道