Elasticsearch:构建机器学习模型:深入研究监督学习管道
Posted Elastic 中国社区官方博客
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Elasticsearch:构建机器学习模型:深入研究监督学习管道相关的知识,希望对你有一定的参考价值。

你听说过 “烹饪就像科学” 这句话吗? 好吧,机器学习也是如此。 就像烹饪一样,构建机器学习 (ML) 管道需要一系列精确的步骤、一点创造力以及对你正在使用的食材的充分理解。
没有时间、技能或知识? 或者你是否厌倦了在厨房里花费数小时手工切碎、混合和混合配料? 想象一下,只需按一下按钮,就可以使整个烹饪过程自动化。 这就是你可以使用 Elastic ML 监督学习作业完成的事情!
就像烹饪食物处理器一样,Elasticsearch 中的机器学习管道简化了做出准确预测和自动化决策的过程。 这篇博文将仔细研究 Elastic Stack 中数据框架分析监督学习作业的不同阶段。 它还描述了允许没有机器学习专业知识的用户训练准确模型的秘密武器。 好奇的读者会发现我们使用的高级机器学习技术的细节和实现细节。 所以抓住你的围裙,让我们开始吧!
监督学习管道
让我们首先看看创建监督学习作业时会发生什么。 启动分类(classification)或回归(regression)作业并查看 Data Frame Analytics Jobs 视图中的作业详细信息选项卡后,你可以看到以下训练阶段。

这种可视化允许用户查看作业的进度,即使作业需要花费大量时间。

数据预处理
我们从重建索引(reindex)开始,将所选数据复制到目标索引中。 然后在 loading_data 阶段,将数据传递给 Java 进程。 它分为训练和测试数据集。 为了保持数据集的代表性,我们使用分层等问题相关的抽样方法。 然后将训练数据集传递给特征选择(feature selection)。
在特征选择(feature selection)阶段,我们计算具有最小冗余和最大相关性(mRMR)的最大信息系数(MIC)的变体。 因此,我们估计了特征和目标值之间的依赖关系。 我们研究了分类字段的三种编码类型:one-hot 编码、目标均值编码和频率编码。 然后,我们对预测目标的重要程度和次要程度的特征和编码进行排序。
结果,我们得到了(编码的)特征及其采样概率。 一个特征的采样概率越高,当我们生成一棵新树时,它被选入特征包的频率就越高。 简单地说,如果 MIC 告诉我们一个特征是另一个特征的两倍,那么在创建数据子集以生成新树时,我们将以两倍的频率使用它。
超参数优化(hyperparameter optimization)
如果作业配置中未设置超参数,我们将搜索最佳值。 根据定义,许多超参数可以设置为任何正数。 这导致无限的搜索间隔,这是不可能搜索到的。
因此,在 coarse_parameter_search 阶段,我们限制了未指定超参数的搜索间隔。 我们为选定的超参数采样几个值。 然后解决二次优化问题以找到最有希望的搜索区间。 我们将超参数值固定为最佳可见值,然后转到下一个超参数。
为了评估超参数,我们使用交叉验证误差并根据可用数据量选择折叠数。 为了加快大型数据集的这个过程,我们使用单一分割成训练和验证集。 在这里,我们将使用不到 50% 的数据进行训练。
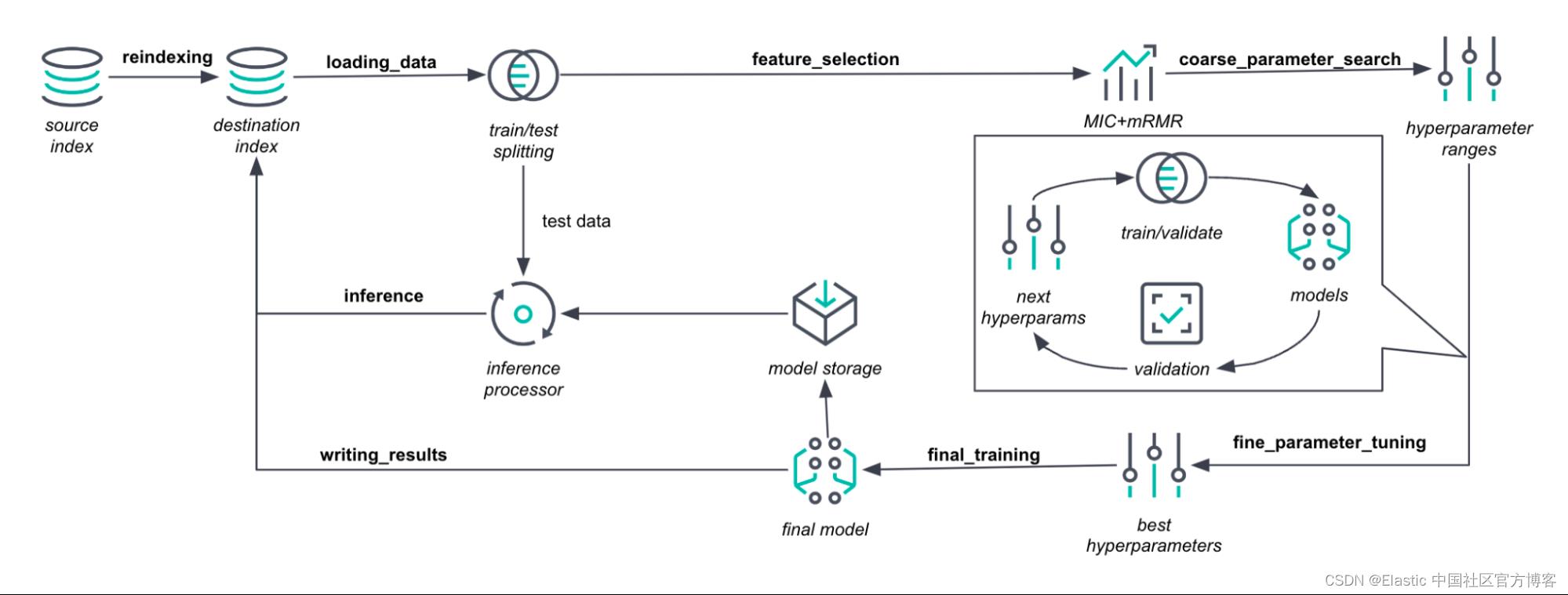
确定有限间隔后,我们进入 fine_tuning_parameters 阶段。 在这里,我们运行由预期改进指导的贝叶斯优化程序(Bayesian optimization)。 在贝叶斯优化内部,我们创建了一个描述模型超参数与模型精度之间关系的高斯过程(Gaussian process)。 这是工作中最耗时的阶段。 如果启用了 early_stopping 作业参数(默认情况下),我们可以减少调整时间。 为此,我们使用高斯过程的方差分析分解。 它告诉我们优化步骤的收益何时与噪声无法区分。
最终培训和评估
在 final_training 阶段,最优超参数和所有训练数据用于训练最终模型。 这会导致更高效和准确的模型,特别是对于中小型数据集。 然后最终模型计算预测和特征重要性值。
在 writing_results 阶段,模型和预测存储在 Elasticsearch 索引中。 该模型作为压缩的 JSON 文档存储在模型定义索引中。 预测和特征重要性存储在目标索引中。
最后,在推理阶段,推理处理器评估测试集。 结果也存储在目标索引中。
结论
有了 Elastic ML,机器学习的未来就在眼前! 因此,拿起你的搅拌勺,预热你的数据,开始构建你自己的机器学习杰作。 立即开始免费试用 Elastic Cloud 以访问该平台。 快乐的烹饪!
以上是关于Elasticsearch:构建机器学习模型:深入研究监督学习管道的主要内容,如果未能解决你的问题,请参考以下文章