案例分享 | QQ 音乐应用 TensorFlow 构建 AI 赋能的音乐曲库
Posted TensorFlow
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了案例分享 | QQ 音乐应用 TensorFlow 构建 AI 赋能的音乐曲库相关的知识,希望对你有一定的参考价值。
文 / QQ 音乐音频团队
QQ 音乐是腾讯音乐娱乐集团推出的网络音乐平台,拥有超过 8 亿的用户,是中国互联网领域领先的正版数字音乐服务的领先平台,同时也是一款免费的音乐播放器,始终走在音乐潮流最前端,向广大用户提供方便流畅的在线音乐和丰富多彩的音乐社区服务。
QQ 音乐曲库数量庞大,怎样有效智能的管理曲库,最大化利用曲库,为曲库赋能是一个重要研究课题。QQ 音乐基于 TensorFlow 开源机器学习平台提供了自动音乐标签、音乐评估、声伴分离、音乐缺陷检测与复原等基础算法,这些基础算法应用于全曲库所有歌曲,构建了一个 AI 赋能的音乐曲库。
构建训练框架
我们基于 TensorFlow 框架搭建了一个通用训练框架,在此基础上可以快速实现算法特征提取、模型搭建、训练以及推理过程,该训练框架使用众多 TensorFlow 提供的高级 API,方便算法实施,如图一所示。
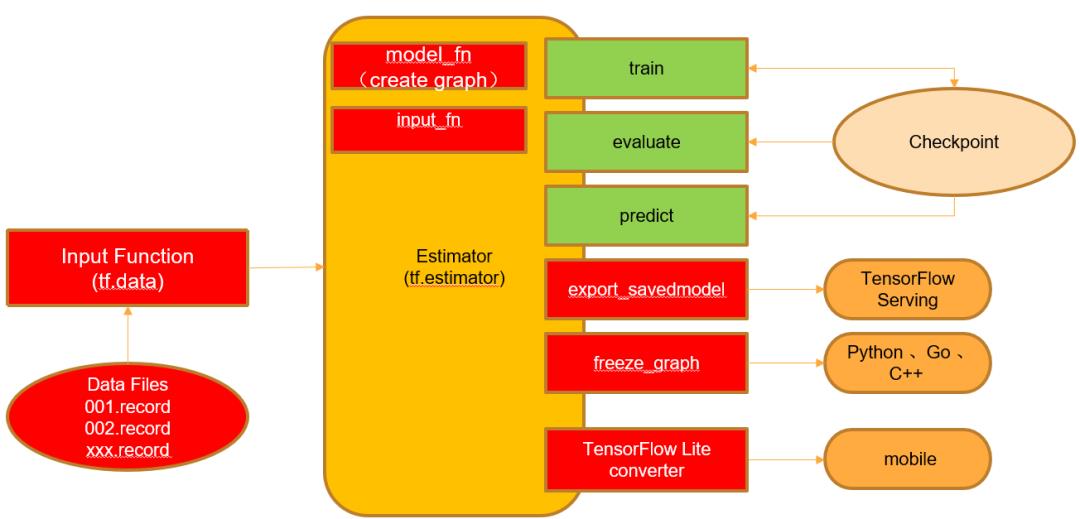
图一 基于 tf.estimator 的训练框图
处理音频领域相关问题需要提取音频特征,这里主要使用 tf.signal 下的信号处理相关 API:提供常用 STFT,MFCC 等特征提取,结合 tf.py_func() 函数还可以使用其他开源音频处理框架,例如 librosa 等。最后使用 tf.data 相关接口进行封装,即可实现输入数据的操作,这样既可转换为 tfrecord,也可转换为 tensor 直接喂给网络进行训练。
如下为一个简单的示例,使用 librosa 读取音频源文件,然后提取特定特征,先使用 tf.py_func() 将其封装成 tensor,然后使用 tf.data.Dataset.map() 进行多线程封装,最后借助 dataset.filter(lambda XXX).map(lambda XXX).apply(XXX) 实现其他相关数据转换。
def _load_wav(filename, gt_rate=16000):
try:
data, _ = librosa.load(filename, sr=gt_rate)
except Exception as e:
raise ('the file %s catch the exception...'%filename)
#T0DO
features =......
#T0DO
return features
def audio_dataset_from_fileslist(path=None, num_parallel_calls=4, gt_rate=16000):
fn_dset = load_fileslist(path)
read_wav = lambda x: tf.py_func(partial(_load_wav, gt_rate=gt_rate),
[x],
tf.float32)
audio_dset = fn_dset.map(read_wav,
num_parallel_calls=num_parallel_calls)
return audio_dset使用 tf.keras、tf.layers、tf.contrib.slim 下的接口即可快速搭建训练网络的模型,免去自定义各个卷积核的权重大小,还可以直接使用其预定义好的现有模型,在其基础之上进行定制化等操作,同时也方便直接在此基础上进行 finetuning。
训练主要是定义好数据输入、模型输出、损失函数、梯度下降方法,然后将其组织在一起进行迭代训练即可,这里使用 tf.estimator 框架,其提供 input_fn, model_fn 对外接口,然后直接调用 train() 进行训练,evaluate() 进行评估,predict() 进行预测推理,同时提供多种分布式训练:单机多卡,多机多卡。最后还可以将模型保存文件进行转换,转换为 pb 或者 SavedModel 抑或者是 tflite 格式进行不同方式的部署,整个框图如上图一所示。
将模型保存为 pb 格式,部署时使用 TensorFlow Serving 作为最终的部署方案。TensorFlow Serving 内部通过异步调用的方式,实现高可用,并且自动组织输入以批次调用的方式节省 GPU 计算资源。最终部署在 P40 的 GPU 上,GPU 的性能被极大利用。
下面我们来看一下 QQ 音乐使用 TensorFlow 的具体场景。
音乐分类
音乐分类,在浩瀚的音乐海洋里,将歌曲按流派、心情、场景等分门别类打上标签,就可将音乐展现出来,并将相关歌曲进行聚类或者给不同的用户进行推荐。
-
分类频道; -
构建音乐电台; -
提升曲库的歌曲标签覆盖率,构建智能曲库; 根据用户兴趣推荐歌曲
音频分类是一个比较经典的分类问题,最大的挑战是曲库中存在成千上万的歌曲,必须同时保证准确率和召回率。为了近一步解决这一挑战,争取做到整个分类过程无需人工参与,我们引进深度学习技术,打造更强、更准的“全天候”精准分类系统!
针对音乐所表达出的多样性,根据具体分类场景提出结合基于音频内容和基于歌词内容的融合的分类系统,提升音频分类的精确度,如图二为基于音频内容分类系统框图;
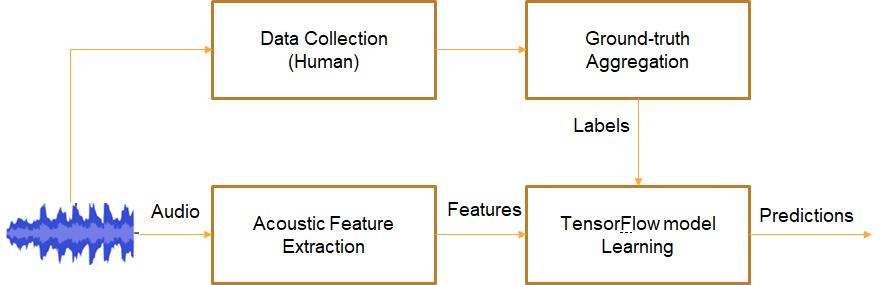
图二 音频分类训练框图
与深度学习中常规的 N 分类器系统不同,使用 N 个二分类器乃至多级分类系统,提升分类效果。如图三为二分类多级分类系统框图,例如我们需要精准召回 “music label A1” 可以设计两个二分类网络进行级联,最终识别出目标类别 “music label A1”,并对该类别歌曲进行全库打标签。
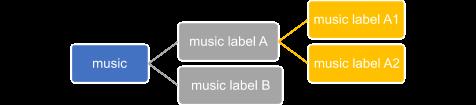
图三 二分类多级分类系统
声伴分离
声伴分离,也常称为歌声分离(Singing Voice Separation),是一种将人声(Vocal)和伴奏(Accompany)分开的技术。我们可定义声伴分离模型为:给定 V + A = M,以及 V 和 A 的一些先验信息,求解出 V 和 A。信号不但可以叠加增强,还可以抵消抑制,因此这里的加号 “+” 只表示 V 和 A 的关系,而不表示数学运算符加法,如下图四为频域看声伴分离。
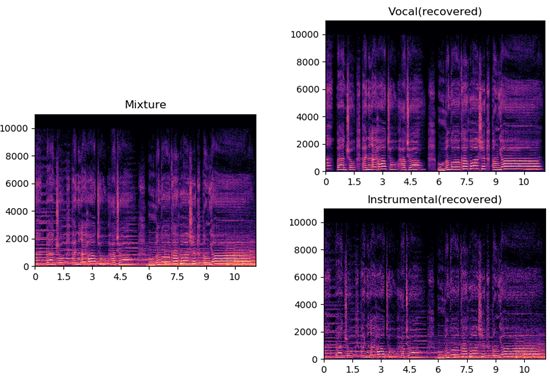
图四 频域看声伴分离
-
高质量曲库伴奏的生成,补充伴奏曲库; -
原唱干声提取,用于声纹识别,歌声转换,修音模板,智能 MIDI 等; 结合 ASR 技术进行歌词生成,歌词对齐,自动生成音乐时间戳 QRC 歌词文件,如下图五为该技术生成的歌词时间戳 demo 展示;


QQ 音乐中文歌曲 QRC 显示
QQ 音乐英文歌曲 QRC 显示
Apple Music 英文歌曲 LRC 显示
图五 基于干声生成歌词时间戳 Demo
声伴分离是音频领域里一个比较热门的研究领域,利用丰富的曲库资源:大量纯净的伴奏和人声作为原始数据集进行训练,网络主要使用 Encoder-Decoder 结构的 Hourglass 的模型进行建模,如图六所示,输入特征为 STFT 对数幅度谱,模型的输出并不直接输出伴奏或者人声,而是输出其频谱理想浮值掩蔽(IRM,Ideal Ratio Mask),然后与原始信号频谱特征相乘即可得到想要的伴奏或者人声。
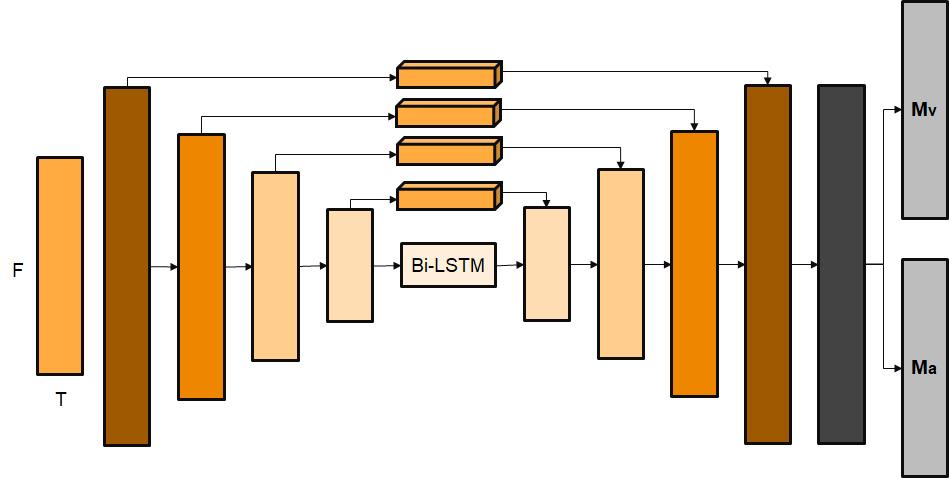
图六 基于 CRNN 的 Encoder-Decoder 的声伴分离模型架构
缺陷检测
缺陷检测,指曲库中某些歌曲存在一些人耳主观感受异常的片段,严重影响用户听感,使用技术手段自动化批量辨别。
缺陷检测的意义在于针对曲库中存量歌曲,检测出来缺陷歌曲可以做替换或者修复等操作,还能在入库过程中提前预防,阻止有缺陷问题的音频文件入库,这对曲库音质的提高非常有意义,能有效提升用户口碑和品牌战斗力。
-
强标注(strong labeling):每个事件都标注有开始时间和结束时间 -
弱标注(weak labeling):事件没有时间信息,也称为有/无标签(presence/absence labeling) 序列标注(sequential labeling):只有事件发生的先后顺序,不知道他们具体的开始和消失时间信息
为了减少人工标注成本使用第二种标注方式:弱标注,首先构建卷积循环神经网络(Convolutional Recurrent Neural Network,CRNN)模型结构:CNN+RNN,然后采用多实例学习(multiple instance learning)来解决存在和不存在标注的 SED 问题,进而得出逐帧的预测结果,最后采用多种融合手段将逐帧预测转换为逐片段预测,进而得出该片段是否包含特定缺陷,遍历整首歌曲即可得出该歌曲是否含有缺陷,最后使用 TensorFlow Serving 部署进行全库扫描。
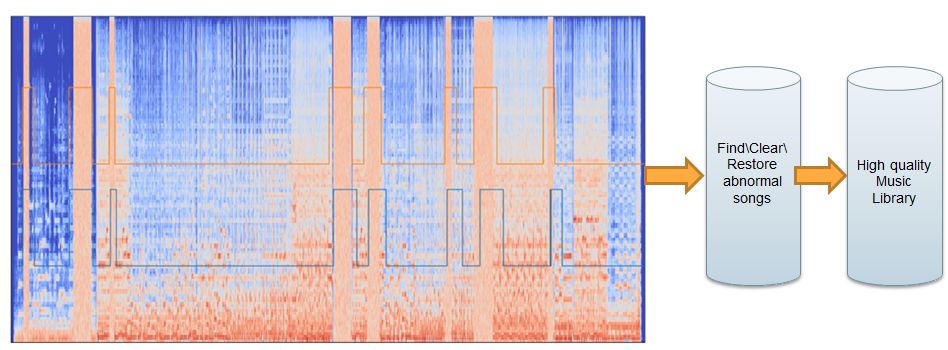
图七 缺陷检测流程
音质复原
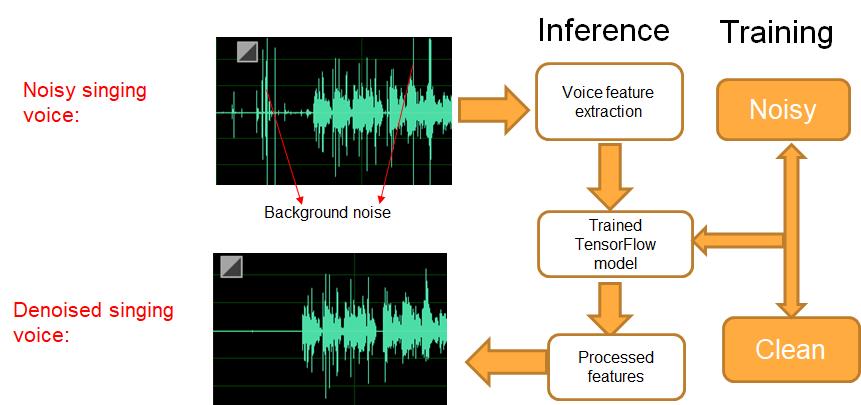
音质复原,曲库中由于一些录音设备(如手机录制)或背景环境干扰等问题,录入的歌曲会含有一些噪声信号:例如 click 噪声,背景噪声等,尤其是一些 UGC 作品,这些歌曲一定程度上影响主观听感,可以使用技术手段将噪声信号进行过滤掉,这能有效修复和提升音质,改善用户体验。
音质复原是直接提升曲库音质的有效手段,既可以部署在云端也可以直接部署在用户手机中,实现实时过滤噪声信号。
提取时-频特征:STFT 线性幅度谱,经过 CRNN 模型,整个模型训练框图如图七所示:
图八 音频去噪训练框图
需要注意的是模型的输出为频谱理想浮值掩蔽(IRM,Ideal Ratio Mask), 该 IRM 也称为时-频掩膜(Time-frequency Masking),如图八所示,即预测一个乘性的时-频掩膜,与输入的时-频特征相乘,得到预测的时-频特征,即将预测得到的 IRM 与源信号的幅度谱进行相乘即可得到干净的幅度谱,达到去噪的效果,针对音质进行修复。目前考虑算法的实时性,仅考虑了 STFT 变换后的复数谱的强度信息,未考虑相位信息,但是业界研究者也逐步认识到相位预测的重要性,通过扩展掩膜的值域,提出了一些关注相位信息的掩膜方法,如 Phase Sensitive Mask(PSM)将掩膜扩展至实数域,complex Ideal Ratio Mask(cIRM)将掩膜扩展至复数域,甚至可将普通卷积模型转化为复数卷积模型。
图九 基于 IRM 的音频去噪
总结与展望
本文以应用 TensorFlow 构建 AI 赋能的音乐曲库为主题,详细介绍了 QQ 音乐如何使用 TensorFlow 搭建深度学习训练模型来解决音频相关的具体问题。
首先介绍了使用 TensorFlow 构建通用训练框架,包括音频特征提取、模型建模、常用训练方法和策略以及模型部署上线等模块。然后紧接着围绕构建智能音乐曲库主题,分别详细介绍使用 AI 技术实现并解决音频领域的多个案例,针对每个案例着重介绍了其概念、使用场景以及具体方法,这些案例均充分利用了 TensorFlow 这一强大的工具。未来将围绕 “Music & AI” 在AI作词/作曲、音频指纹、翻唱/哼唱识别等领域继续探索,并在 Google TensorFlow 生态支持下,为构建智能曲库提供更多优秀的解决方案,为用户带来优质音质体验。
参考文献
Virtanen, Tuomas, Mark D. Plumbley, and Dan Ellis, eds. Computational analysis of sound scenes and events. Heidelberg: Springer, 2018.
想加入案例分享?点击 “阅读原文”,填写相关信息,我们会尽快与你联系。
以上是关于案例分享 | QQ 音乐应用 TensorFlow 构建 AI 赋能的音乐曲库的主要内容,如果未能解决你的问题,请参考以下文章
案例分享:某品牌音响系列协议调试工具(搜寻主机,查询通道,基本控制API,云音乐API,语言节目API等,可增删改指令)