Python爬虫QQ音乐数据采取,公开数据获取案例之一
Posted 五包辣条!
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python爬虫QQ音乐数据采取,公开数据获取案例之一相关的知识,希望对你有一定的参考价值。
工具准备
数据来源: QQ音乐
开发环境:win10、python3.7
开发工具:pycharm、Chrome
效果展示
项目思路解析
搜索你需要的歌名或者歌曲
抓取对应的数据包
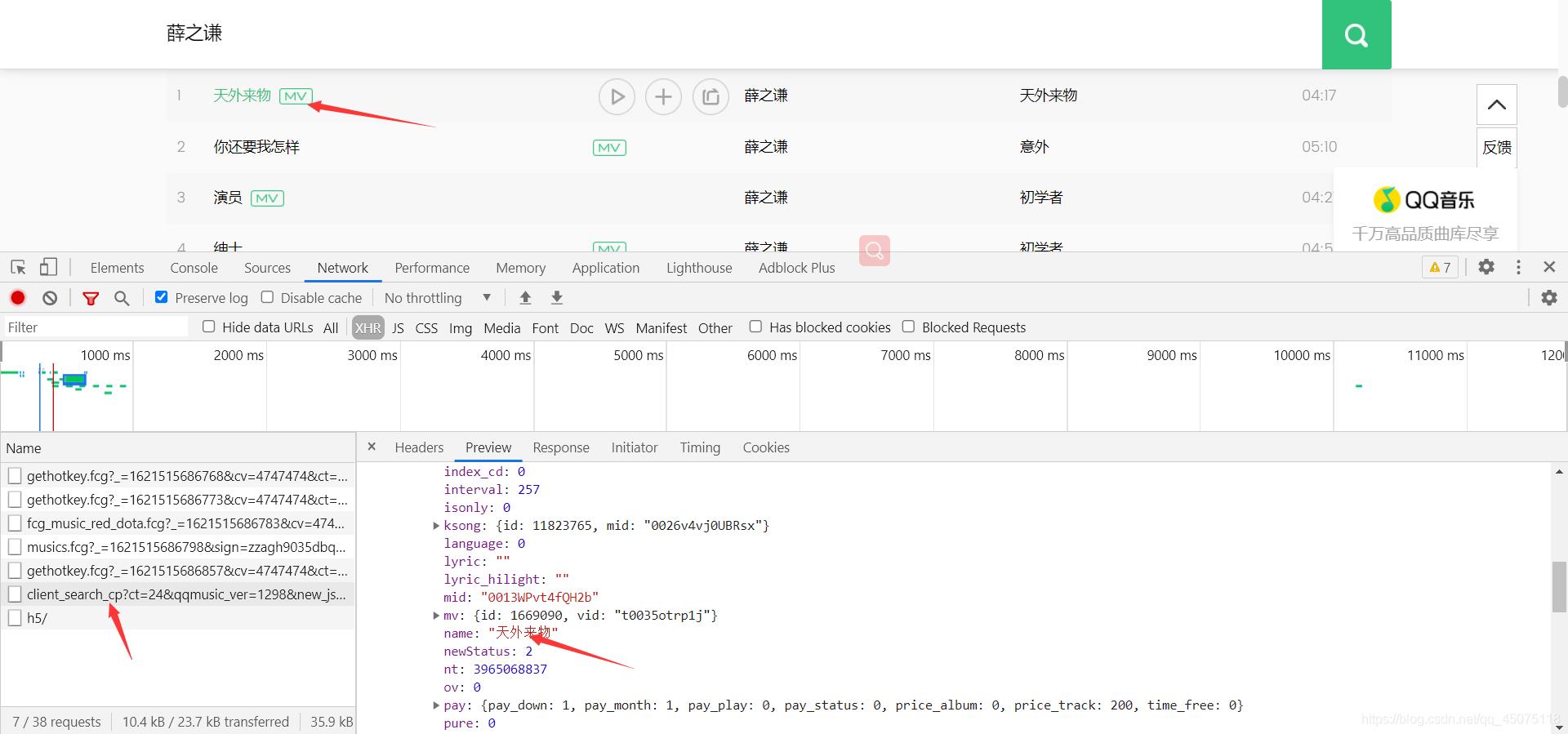
提取json数据里的歌曲名字,歌曲的mid,歌手名字

for i in range(1, 10):
url = 'https://c.y.qq.com/soso/fcgi-bin/client_search_cp'
params = {
"ct": " 24",
"qqmusic_ver": " 1298",
"new_json": " 1",
"remoteplace": " txt.yqq.song",
"searchid": " 66595602585102401",
"t": " 0",
"aggr": " 1",
"cr": " 1",
"catZhida": " 1",
"lossless": " 0",
"flag_qc": " 0",
"p": str(i),
"n": " 10",
"w": keyword,
"g_tk_new_20200303": " 1390029147",
"g_tk": " 1390029147",
"loginUin": " 1164153961",
"hostUin": " 0",
"format": " json",
"inCharset": " utf8",
"outCharset": " utf-8",
"notice": " 0",
"platform": " yqq.json",
"needNewCode": " 0"
}
response = requests.get(url, params=params, headers=headers)
# print(re.findall('callback\\((.*)\\)', response)[0])
search_result = eval(re.findall('callback\\((.*)\\)', response.text)[0])
song_info_list = search_result['data']['song']['list']
# print()
tplt = "{0:<10}\\t{1:<10}\\t{2:<20}"
print(tplt.format("序号", "歌手", "歌名"))
for song_info in song_info_list:
# print(song_info)
song_name = song_info['songname']
song_mid = song_info['songmid']
singer = song_info['singer'][0]['name']
找到单个音乐的请求数据接口
音乐的播放地址为purl
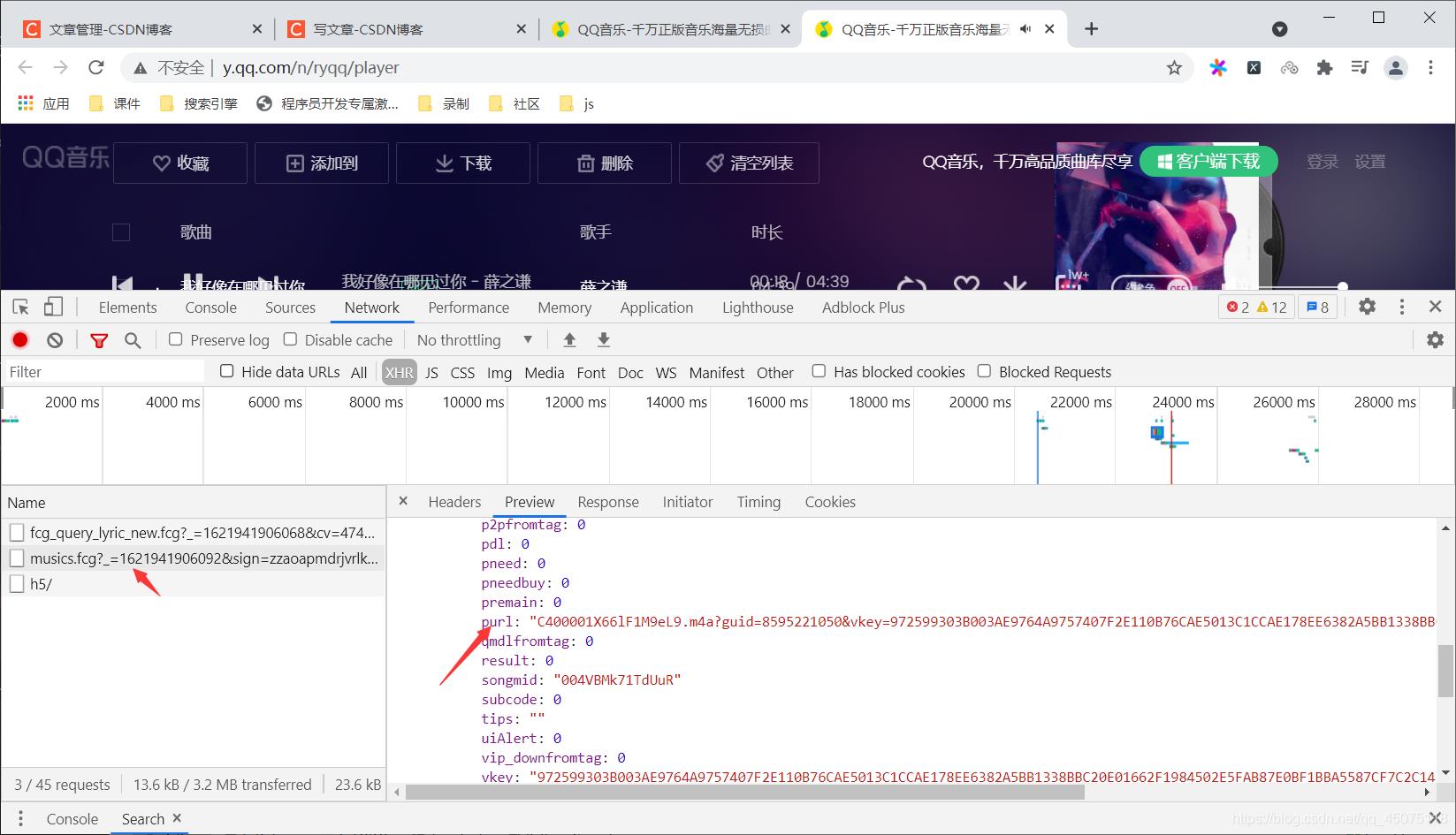
动态提交的数据来自与同一个js文件
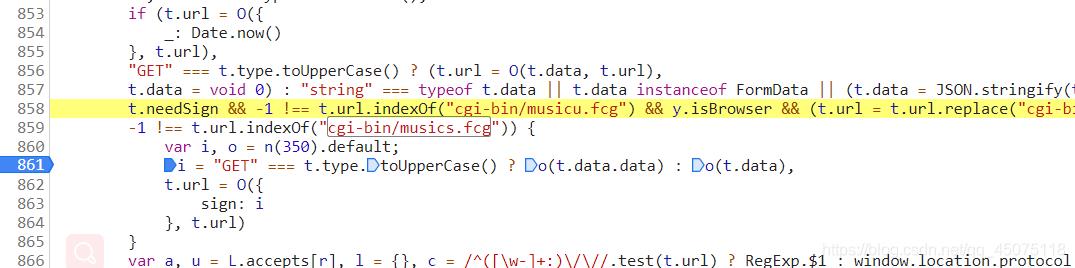
调试js代码请求方法为get
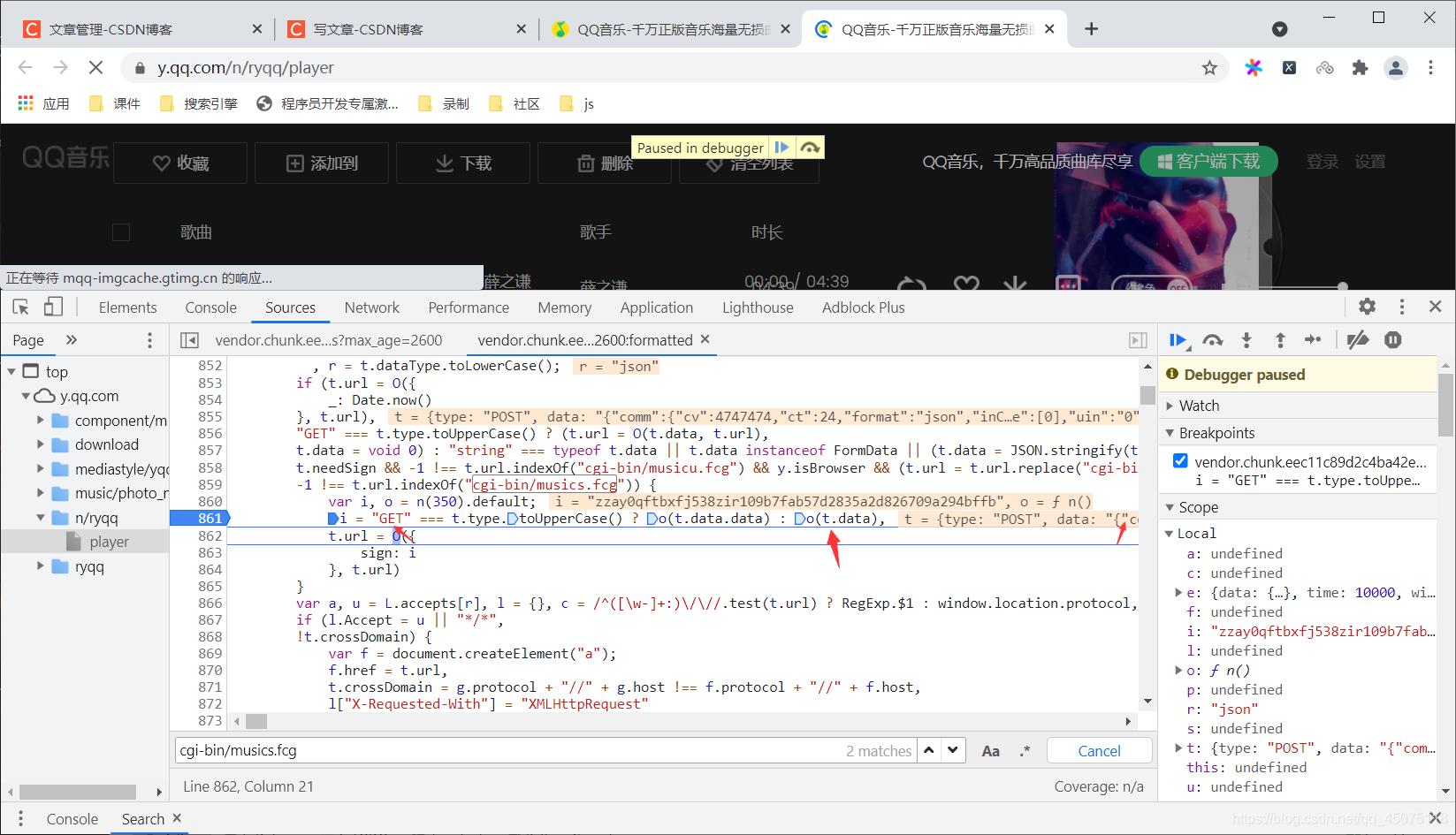
get请求的url地址拼接上post对应的表单参数
因为我们获取的数据只需要数据包含purl的req_1,只需要对应data的req_1的参数,songmid为歌曲的mid
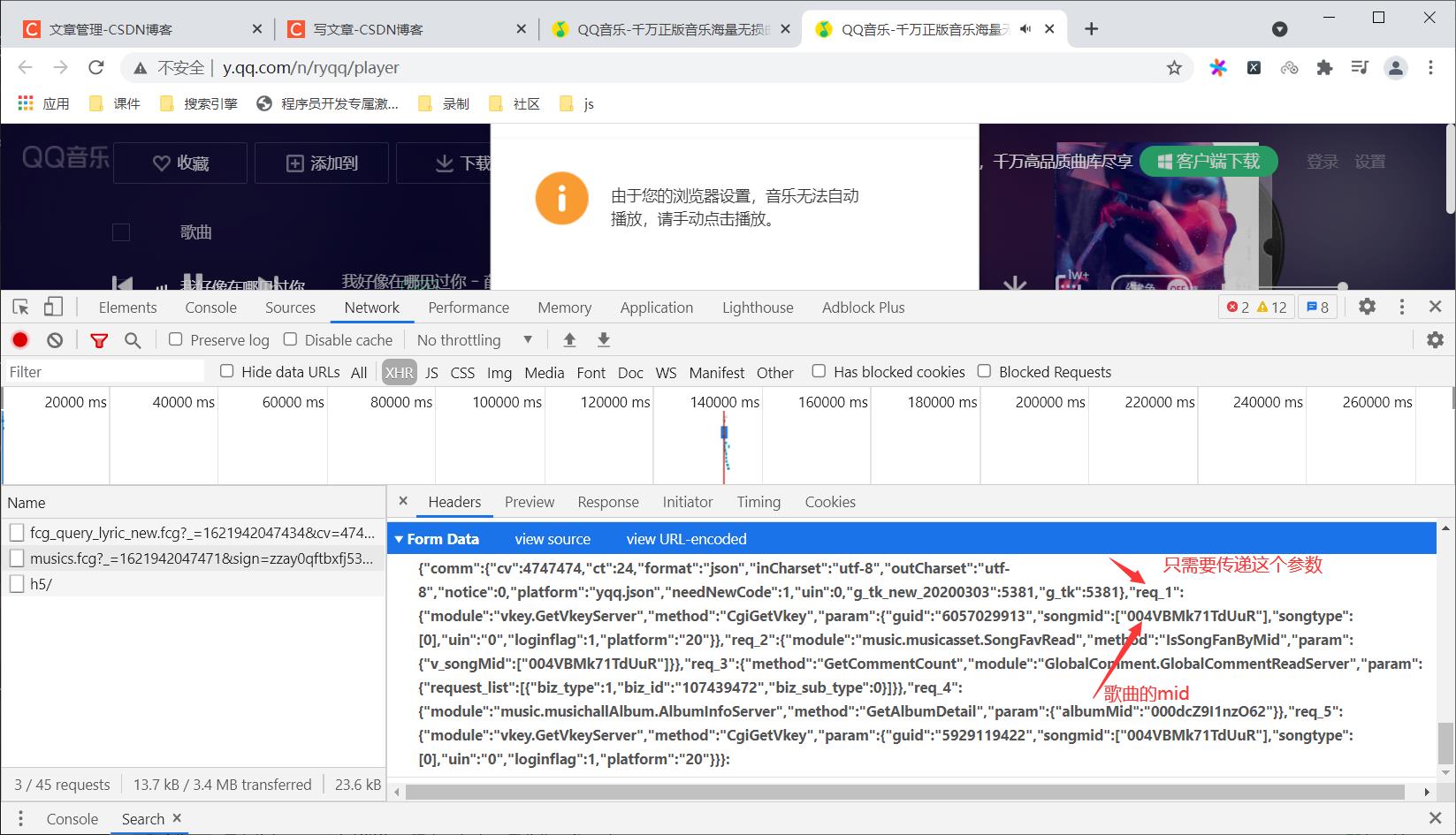
params1 = {
'_': time.time()*1000,
'sign': 'zzakgej75pk8w36d82032784bdb9204d99bf6351acb7d',
"data": '{"req":{"module":"vkey.GetVkeyServer","method":"CgiGetVkey","param":{"guid":"7469768631","songmid":["' + song_mid + '"],"songtype":[0],"uin":"1164153961","loginflag":1,"platform":"20"}}}'
}
response = requests.get(url1, params=params1, headers=headers)
得到对应的req_1的数据,取出purl值拼接成歌曲播放地址
下载对应歌曲
简易代码分享
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# @Author : BaiChuan
# @File : qq音乐.py
import requests
import re
import time
headers = {
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (Khtml, like Gecko) Chrome/80.0.3987.132 Safari/537.36",
}
keyword = input('请输入你想下载的歌手名:')
for i in range(1, 10):
url = 'https://c.y.qq.com/soso/fcgi-bin/client_search_cp'
params = {
"ct": " 24",
"qqmusic_ver": " 1298",
"new_json": " 1",
"remoteplace": " txt.yqq.song",
"searchid": " 66595602585102401",
"t": " 0",
"aggr": " 1",
"cr": " 1",
"catZhida": " 1",
"lossless": " 0",
"flag_qc": " 0",
"p": str(i),
"n": " 10",
"w": keyword,
"g_tk_new_20200303": " 1390029147",
"g_tk": " 1390029147",
"loginUin": " 1164153961",
"hostUin": " 0",
"format": " json",
"inCharset": " utf8",
"outCharset": " utf-8",
"notice": " 0",
"platform": " yqq.json",
"needNewCode": " 0"
}
response = requests.get(url, params=params, headers=headers)
# print(re.findall('callback\\((.*)\\)', response)[0])
search_result = eval(re.findall('callback\\((.*)\\)', response.text)[0])
song_info_list = search_result['data']['song']['list']
# print()
tplt = "{0:<10}\\t{1:<10}\\t{2:<20}"
print(tplt.format("序号", "歌手", "歌名"))
for song_info in song_info_list:
# print(song_info)
song_name = song_info['songname']
song_mid = song_info['songmid']
singer = song_info['singer'][0]['name']
print(tplt.format(song_mid, singer, song_name))
url1 = 'https://u.y.qq.com/cgi-bin/musicu.fcg'
params1 = {
'_': time.time()*1000,
'sign': 'zzakgej75pk8w36d82032784bdb9204d99bf6351acb7d',
"data": '{"req":{"module":"vkey.GetVkeyServer","method":"CgiGetVkey","param":{"guid":"7469768631","songmid":["' + song_mid + '"],"songtype":[0],"uin":"1164153961","loginflag":1,"platform":"20"}}}'
}
response = requests.get(url1, params=params1, headers=headers)
print(response.json())
songlink = response.json()['req']['data']['midurlinfo'][0]['purl']
if songlink == '':
print('这首歌是付费歌曲无法下载。')
else:
path = 'qq音乐/' + song_name + "-" + singer + ".mp3"
with open(path, 'wb') as f:
f.write(requests.get('https://isure.stream.qqmusic.qq.com/' + songlink, headers=headers).content)
print("正在下载:", song_name)
本文章只提供学习,切勿用在其他用途
vip音乐不做讲解
以上是关于Python爬虫QQ音乐数据采取,公开数据获取案例之一的主要内容,如果未能解决你的问题,请参考以下文章