亚某逊验证码识别-使用百度OCR
Posted 不止于python
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了亚某逊验证码识别-使用百度OCR相关的知识,希望对你有一定的参考价值。
最近在抓取亚某逊的时候, 除了随机请求头之外, 还有时不时出现的验证码页面, 原来换个ip还可以, 但是时间长了, 出现的越来越频繁, 所以这次就来彻底解决这个验证码的问题
验证码长这样:
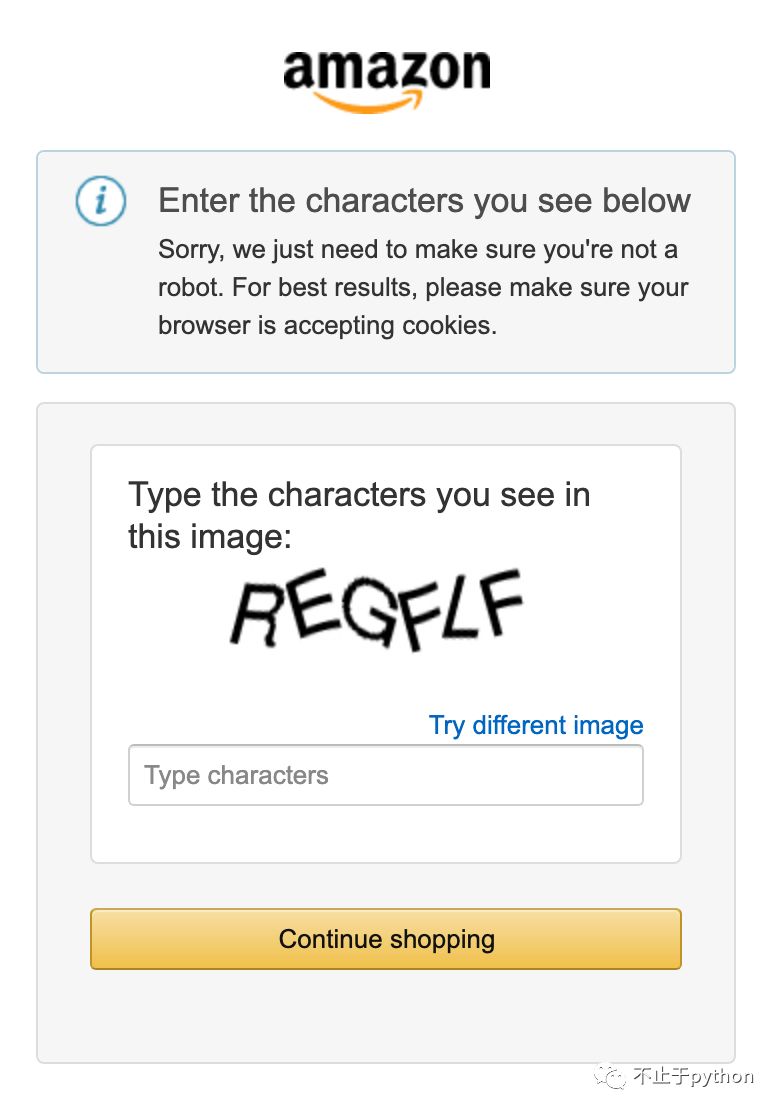
使用tesseract + pillow 这是最简单最直接的方式, 不过也是效率最低的, 识别特别正常的还是没问题的
使用第三方打码平台或者第三方OCR, 我使用过云打码, 还行(听说是一帮人在人工打码)
自己写算法, 训练模型, 达到想要的结果
使用这种方式我们来简单的试试
上代码:
import osimport pytesseractdef verify(path):result = pytesseract.image_to_string(path)true_result = path.split(".")[0].upper()print(true_result, result, true_result==result)if __name__ == "__main__":jpg_list = [path for path in os.listdir() if path.endswith("jpg")]for path in jpg_list:verify(path)
输出结果:
YYFULM FalseYUGKMK FalseYUBYNC YUBYNG FalseYXKUYB YARUYB FalseYTCKNR YICKNR FalseYXAFGL FalseYTPTAY FalseYTPURK YIAyRK FalseFUXTRN FUXTRAN FalseYXJCJL False
发现测试了10个文件没有一个正确的, 因为这种验证码没有干扰线, 所以也没必要使用pillow来进行降噪处理
所以这种方式就不多介绍了
下面介绍使用百度orc来进行识别
1. 首先要注册百度智能云账户,
然后到控制台 --> 产品服务--> 文字识别--> 创建应用--> 选择对应的服务创建
2. 安装百度sdk
pip3 install baidu-aip3. 简单使用
百度文字识别官方文档: https://ai.baidu.com/ai-doc/OCR/Ek3h7xypm
from aip import AipOcr# 你的 APPID AK SKAPP_ID = '你的APPID'API_KEY = '你的AK'SECRET_KEY = '你的SK'client = AipOcr(APP_ID, API_KEY, SECRET_KEY)# 读取图片def get_file_content(filePath):with open(filePath, 'rb') as fp:return fp.read()# 测试文件也可以写路径image = get_file_content('test.jpg')# 调用通用文字识别, 图片参数为本地图片result = client.basicGeneral(image)# 定义参数变量options = {# 定义图像方向'detect_direction' : 'true',# 识别语言类型,默认为'CHN_ENG'中英文混合'language_type' : 'CHN_ENG',}# 调用通用文字识别接口results = client.basicGeneral(image,options)print(results)# 遍历取出图片解析的内容# for word in result['words_result']:# print(word['words'])try:code = results['words_result'][0]['words']except:code = '验证码匹配失败'print(code)
现在的通用文字识别是每天50000次的免费使用次数, 一般来说够用了
识别率还可以
下面就将百度ORC使用到amazon验证码中
1. 分析结果
通过验证码页面会发现, 在验证码输入后, 点击Continue shopping按钮, 会跳转到指定页面
需要的三个参数
# 在页面提取'amzn': 'AiJocMX51/V5V+rDX0LXKg==''amzn-r':'/'# 验证码'field-keywords': 'JRRRXK'
2. 直接上代码
# -*- coding: utf-8 -*-# @Author: Mehaei# @Date: 2019-12-21 16:23:32# @Last Modified by: Mehaei# @Last Modified time: 2019-12-21 16:46:08import osimport requestsfrom aip import AipOcrfrom lxml import etreefrom urllib.parse import quote# 百度API所需参数APP_ID = '******'API_KEY = '*******************'SECRET_KEY = '**************'VERIFY_CODE_API = "https://www.amazon.com/errors/validateCaptcha?amzn={amzn}&amzn-r={amzn_r}&field-keywords={verify_code}"BaiDuClient = AipOcr(APP_ID, API_KEY, SECRET_KEY)VerifyCodeImgSaveDir = "../verify_img"class VerifyCode(object):def __init__(self, rm_img=True):self.rm_img = rm_imgself._loads_file_dir()def _loads_file_dir(self):if not os.path.exists(VerifyCodeImgSaveDir):os.makedirs(VerifyCodeImgSaveDir)def get_img_download_url(self, html, xpath='//div[@class="a-row a-text-center"]/img/@src'):html = etree.HTML(html)img_list = html.xpath(xpath) or [""]return img_list[0]def get_verify_url(self, html, verify_code=None):html = etree.HTML(html)amzn = html.xpath('//input[@name="amzn"]/@value') or [""]amzn_r = html.xpath('//input[@name="amzn-r"]/@value') or [""]return VERIFY_CODE_API.format(amzn=quote(amzn[0], 'utf8'), amzn_r=quote(amzn_r[0], 'utf8'), verify_code=verify_code)def get_verify_params(self, html, verify_code=None):html = etree.HTML(html)amzn = html.xpath('//input[@name="amzn"]/@value') or [""]amzn_r = html.xpath('//input[@name="amzn-r"]/@value') or [""]if all((verify_code, amzn, amzn_r)):return {"amzn": amzn[0], "amzn-r": amzn_r[0], "field-keywords": verify_code}else:return {"errors_code": 404, "msg": "Missing the necessary parameters"}def save_verify_img(self, html):img_download_url = self.get_img_download_url(html)img_name = img_download_url.split("/")[-1]img_save_pname = "%s/%s" % (VerifyCodeImgSaveDir, img_name)try:res = requests.get(img_download_url)if res.ok:open(img_save_pname, "wb").write(res.content)return img_save_pnamereturn ""except Exception:return ""def get_file_content(self, file_path):if not os.path.exists(file_path):return ""with open(file_path, 'rb') as fp:return fp.read()def get_verify_code(self, html=None, get_url=True):img_pname = self.save_verify_img(html)if not img_pname:return {"errors_code": 404, "msg": "Not found img save path or not download success"}image_content = self.get_file_content(img_pname)if not image_content:return {"errors_code": 404, "msg": "Non read image content"}result = BaiDuClient.basicGeneral(image_content)if self.rm_img:os.remove(img_pname)if result.get("error_code") == 17:return {"errors_code": 429, "msg": "Maximum number of requests"}try:verify_code = result.get("words_result", [{}])[0].get("words", "")except Exception:verify_code = ""if verify_code.isalpha() and len(verify_code) == 6:if get_url:return self.get_verify_url(html, verify_code)return self.get_verify_params(html, verify_code)return {"errors_code": 404, "msg": "The correct verification code was not obtained, get code: %s" % verify_code}if __name__ == "__main__":v = VerifyCode(rm_img=False)html = "含有验证码的页面"url = v.get_verify_code(html, get_url=True)print(url)
主要参数说明:
rm_img: 默认为True, 识别验证码首先要下载, 这个参数决定识别后是否删除图片
get_url: 默认为True返回拼接好参数的url, 反之返回参数dict
为True, 返回
https://www.amazon.com/errors/validateCaptcha?amzn=AHmXZd%2B0MtRKSB64dd%2FQwQ%3D%3D&amzn-r=%2F&field-keywords=regflf为False, 返回
{'amzn': 'AiJocMX51/V5V+rDX0LXKg==', 'amzn-r': '/', 'field-keywords': 'JRRRXK'}html: 是出现验证码的页面源码
如果不出意外, 填入正确的百度api的参数, 就可以直接接入到你的项目中了,
就是判断如果是验证码页面, 就将验证码页面源代码放入程序中, 再次请求返回的url就可完成自动跳转到指定页面
这篇到这里结束了, 下篇来讲使用训练模型来进行验证码识别
扫描二维码
获取更多精彩
不止于python
以上是关于亚某逊验证码识别-使用百度OCR的主要内容,如果未能解决你的问题,请参考以下文章