scikit-learn训练验证码识别模型
Posted Vimin社区
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了scikit-learn训练验证码识别模型相关的知识,希望对你有一定的参考价值。
机器学习训练验证码识别模型
思路:
一、图片灰度化
二、去除噪声
三、字符切割
四、切割图像存储
五、模型训练
六、模型测试与调优
使用画图软件打开验证码图片观察如下:
观察验证码可以发现:
1、验证码主要由4~5个大写字母或数字组成;
2、噪声会布满整个图片,且像素值相同;
3、待识别字符之间存在重合/粘连的情况;
一、图片灰度化
from PIL import Image
image = Image.open('./data/profile.png')
image = image.convert('L') # 原图为RGB格式,转化为灰度图
print(image.size)
# (225, 70)
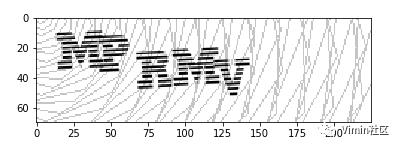
二、去除噪声
对整张图片做像素值统计:
from collections import defaultdict
length = image.size[0]
width = image.size[1]
counter = defaultdict(int)
for y in range(width): # 遍历所有像素
for x in range(length):
pix = image.getpixel((x, y)) # 获取(x,y)位置的像素值
counter[pix] += 1
# 像素值统计排序
count_list = sorted(counter.items(), key=lambda x:x[1], reverse=True)
# count_list = [(255, 10860), (203, 2902), (29, 391), (30, 30), (215, 24), (142, 23), (195, 22), ... (104, 1)]
count_list即为图片像素的统计列表,其中像素值为255(纯白色)和203的统计值明显多于其他。观察发现,255为背景色,203即为噪声,其他的像素即为字符;故对统计数最多的像素值进行保留,第二多的像素值(噪声)修改为255(纯白),其他(字符)的像素值修改为0(纯黑);
noise = count_list[1][0] # 噪声点的像素
im2 = Image.new("L", image.size, 255) # 新的图像
for y in range(width):
for x in range(length):
# 获取(x,y)位置的像素值
pix = image.getpixel((x, y))
if pix == 255 or pix == noise:
pix = 255
else:
pix = 0
# 将(x,y)位置的像素值修改为pix
im2.putpixel((x, y), pix)
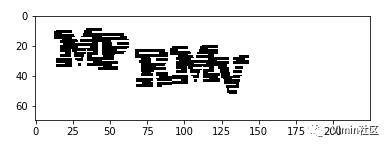
三、字符切割
切割思路:
1、对图像进行x轴切割(竖向),即切分每个字符;
2、对图像进行y轴切割(横向),即将每个字符的上下空白切除;
3、对字符图像大小标准化,便于生成训练特征数据;
3.1 对图像进行x轴切割
x轴切割思路:由于没有噪音干扰,所以先将不黏连的字符分开;对图像遍历,每列的像素值求和,当求和的值不为 255*列的长度时即为检测到黑色(像素值为0而不是255);
# 对单个图像进行X轴的切割、即字符切割
def image_split_on_x(image) -> list:
inletter = False # 判断x值所对应的列是否在字符内部
start = end = 0
length, width = image.size
letter_choice = []
for x in range(length):
pix_count = sum([image.getpixel((x, y)) for y in range(width) ])
# 此时表示检测到字符左侧所对应的x值
if not inletter and pix_count < (255 * width):
inletter = True
start = x
# 当inletter,且检测的列为纯白时表示检测到字符右侧所对应的x值
if inletter and pix_count == (255 * width):
end = x
letter_choice.append((start,end))
inletter = False
# print(letter_choice)
image_split_array = [] #存储切割后的图像
for letter in letter_choice:
# (切割的起始横坐标,起始纵坐标,结束横坐标,结束纵坐标)
im_split = image.crop((letter[0], 0, letter[1], image.size[1]))
image_split_array.append(im_split)
return image_split_array
查看image_split_array中第一个图片如下:
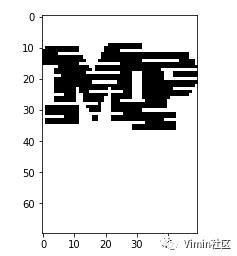
查看该图像的切割坐标记录列表letter_choice如下:
# [(13, 63), (67, 144)]
此时第一个元组值表示上图MP字符的x轴宽度63-13=50px,第二个元组值表示RMV字符的x轴宽度144-67=77px;
字符中MW等字符基本为宽度最大的字符(约为32px),所以可以人为设定当切割的字符宽度大于35px时表示含有多个字符;字符数即为(width // 35 + 1);
修改
image_split_on_x中的切割逻辑,如下:
image_split_array = [] #存储切割后的图像
for letter in letter_choice:
left, right = letter # letter左、右像素值
char_width = right - left # letter宽度
# 宽度大于35的letter视为含有多个字符
if char_width > 35:
# 计算letter含有的字符数量
char_count = char_width // 35 + 1
# letter切割后存储的坐标
split_array = []
# letter中字符的平均宽度
char_width_each = int(char_width / char_count)
for loop in range(char_count):
# 最后一个切割图像的右像素值为letter的right
if loop == char_count -1:
split_array.append((left, right))
break
split_array.append((left, left+char_width_each))
left += char_width_each
else:
split_array = [letter]
# 遍历letter切割后的坐标
for item in split_array:
# (切割的起始横坐标,起始纵坐标,结束横坐标,结束纵坐标)
im_split = image.crop((item[0], 0, item[1], image.size[1]))
image_split_array.append(im_split)
3.2 对字符图像y轴切割
def image_split_on_y(image):
"""将单个字符图片进行y轴方向切割掉空白"""
# 由于单个字符的上下部分可能不连接,所以记录每个y值
y_px_list = []
length, width = image.size
for y in range(width):
pix_count = sum([image.getpixel((x, y)) for x in range(length)])
if pix_count < (255 * length):
y_px_list.append(y)
top = min(y_px_list) # 字符的顶部y轴像素值
bottom = max(y_px_list) # 字符的底部y轴像素值
char_image_split = image.crop((0, top, image.size[0], bottom))
return char_image_split
3.3 对字符图像大小标准化
由于切割后的字符大小不一,所以需要对字符大小进行标准化,确保标准化图像的大小能放下所有字符,这里取宽32px, 高28px, 然后确保字符放在图像的中央,所以需要计算图像距离左边距
char_start_w和上边距char_start_h. 如下图。
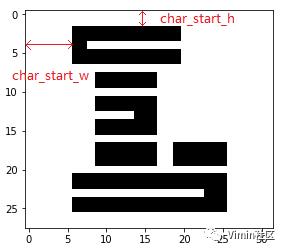
功能代码如下:
def image_split(image):
"""
切割图像的字符并标准化
:param: image:单幅图像
:return: goal_char_list 单幅图像被切割后的图像列表
"""
goal_char_list = []
char_images = image_split_on_x(image) # x轴切割
for char in char_images:
char_image_split = image_split_on_y(char) # y轴切割
# 对字符图片标准化为32x32
image_width, image_height = 32, 28
#新建标准化空白image
goal_image = Image.new("L", (image_width, image_height), 255)
# 获取y轴切割后的单字符图像大小
char_image_size = char_image_split.size
# 计算左边距
if char_image_size[0] <= image_width:
fill_w = int((image_width - char_image_size[0]) / 2)
char_start_w = 0
else:
fill_w = 0
char_start_w = int((char_image_size[0] - image_width) / 2) + 1
# 计算上边距
if char_image_size[1] <= image_height:
fill_h = int((image_height - char_image_size[1]) / 2)
char_start_h = 0
else:
fill_h = 0
char_start_h = int((char_image_size[1] - image_height)/2) + 1
# 根据左上边距 对空白image 写入字符的像素值
for i in range(char_start_w, char_image_split.size[0] - char_start_w):
for j in range(char_start_h, char_image_split.size[1] - char_start_h):
# 获取切割图像像素值
pix = char_image_split.getpixel((i, j))
# 将像素值写入空白图像
goal_image.putpixel((fill_w + i - char_start_w, fill_h + j - char_start_h), pix)
# 将标准化后的字符放入结果列表
goal_char_list.append(goal_image)
return goal_char_list
3.4 完整切割示例图如下:
| 原图 | 灰度化去噪后图片 |
|---|---|
|
|
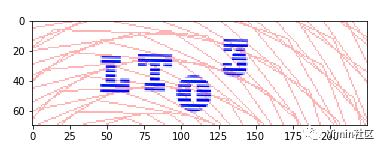
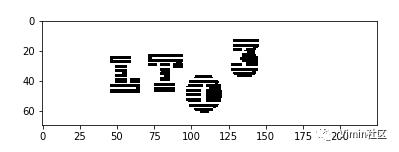
| x轴切割后 | y轴切割标准化后 |
|---|---|
四、切割图像存储
思路:
1、读取所有验证码图片,图片名称即为图片内的正确字符;
2、将图片逐一切割标准化;
3、将真实字符相同的图片放于同一个文件夹下,命名为字符,如:./a/ 、./b/;
4、对输出的字符图像命名,格式:原图字符_字符在原图中的位置_时间戳.jpg
代码:
# 创建数据文件夹
# 0-9
for i in range(10):
path = './nubia_data/%s' % i
if not os.path.exists(path):
os.makedirs(path)
# a-z
for j in range(97,123):
j = chr(j)
path = './nubia_data/%s' % j
if not os.path.exists(path):
os.makedirs(path)
# 将切割的字符保存为图片文件
def char2file(char_list, labels):
i = 0
for char,label in zip(char_list,labels):
i += 1
t = int(time.time()*1000)
#命名格式:字符/原图片字符_字符在原图片字符中的位置_时间戳.jpg
char.save('./nubia_data/%s/%s_%s_%s.jpg'%(label,labels,i,t),'jpeg')
五、模型训练
思路:
1、读取字符文件,像素值作为特征值;
2、特征值对应的结果为字符,即0-9a-z;
3、使用scikit-learn机器学习库训练逻辑回归模型;
代码:
# 加载字符图片提取特征数据与目标值
# 特征数据
images = []
# 目标值
labels = []
# 0-9字符
number = [str(i) for i in range(10)]
# a-z字符
letters = [chr(j) for j in range(97,123)]
# 结果字符列表
key = number + letters
# 特征数据维度
line_shape = 32 * 28
for i in key:
path = './nubia_data/%s/' % i
if os.path.exists(path):
file_list = os.listdir(path)
for file in file_list:
im = Image.open(path + file) # 打开图片
image = np.array(im)
# 每个字符对应一个训练用例
image = image.reshape(1,line_shape)
label = i
images.extend(image) # 特征数据
labels.append(label) # 目标值
# 导入训练数据切分函数
from sklearn.cross_validation import train_test_split
# 导入逻辑回归分类模型
from sklearn.linear_model import LogisticRegression
# 导入模型持久化方法(保存模型)
from sklearn.externals import joblib
# 记录分值最好的模型
best_model = None
# 记录模型测试分值
best_sc = 0.0
# 进行10次训练
for _ in range(10):
# 将特征数据切分,80%训练数据, 20%测试数据
X_train,X_test, y_train, y_test = train_test_split(images,labels, test_size=0.2)
logistic = LogisticRegression()
model = logistic.fit(X_train,y_train) # 数据训练
sc_ = model.score(X_test,y_test) # 数据测试,输出测试分值
print(sc_)
# 记录分值最好的模型
if sc_ > best_sc:
best_model = model
best_sc = sc_
# 将训练模型本地保存,避免重复训练
joblib.dump(model2, "./nubia_logistic_verify_code_model.m")
六、模型测试与调优
测试数据测试结果
from sklearn.externals import joblib
# 加载训练模型
model = joblib.load('./nubia_logistic_verify_code_model.m')
# 计算测试数据分数
sc_ = model.score(X_test,y_test)
print(sc_)
# 0.9910714285714286
# 由于一张验证码为4-5个字符,所以验证码的识别通过率为:pass_rate
pass_rate= sc_ ** 4.5
print(pass_rate)
# 0.9604445633178521
生产环境数据测试
生产环境中,获取验证码图片以及唯一标识,然后将模型测试结果和唯一标识向后端请求,通过内部响应码判别是否验证成功;
模型调优
调优建议:
1、使用不同的训练模型进行训练测试;
2、将生产环境中的响应结果和验证码图片保存,对测试错误的图片进行机器标注,人工修改后加入训练数据,增加某些字符的识别率;
3、本例模型的输出目标值为0-9a-z, 所以共36个训练样本,训练样本之间的数量不平衡也会影响模型的识别率;
以上是关于scikit-learn训练验证码识别模型的主要内容,如果未能解决你的问题,请参考以下文章