流式计算优化:时效性
Posted DataFunTalk
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了流式计算优化:时效性相关的知识,希望对你有一定的参考价值。
本文中所有图片仅用作交流学习
编辑整理:Hoh Xil
内容来源:算法学习@知乎专栏
出品社区:DataFun
注:欢迎转载,转载请注明出处。
▌什么是流式计算
在传统的数据处理流程中,总是先收集数据,然后将数据放到数据库中,当人们需要的时候通过查询对应的数据进行处理。这样看起来没什么大问题,但是当我们遇到以下场景的时候就有问题了。比如:金融风控,双十一抢购,推荐系统等,这类系统有一个共同的特点,就是对时效性要求非常高。
所谓“时光一逝不复返,往事只能回味“。我们举一个简单的例子,当前你的余额宝账户有3000块,你去商场消费了2000。这时候触发支付宝结算,假设支付宝处理这笔数据需要10秒,而10秒之内,你接着又消费了2000,这时候应该提示你余额不足了,但由于结算程序还在处理,实际上余额还有3000,那么你这2000又结结实实可以消费了。10秒后支付宝反应过来了,这时候钱已经扣了,找谁还钱去啊,这样引发了很大的金融风险。
其实还有一个简单的办法,支付宝在结账的时候(10秒钟之内)禁止消费,又带来的问题是交易量下跌,这样的损失更加接受不了,所以这就对数据的实时处理要求非常高,这1秒的数据这1秒就要处理完,下一秒的数据可能又是其它的情况了。数据就像流水一样不断变化,我们需要实时的处理数据。
那么如何才能够提高流式计算的速度呢?
▌流式计算优化之拓扑排序
1. 流式计算
流式计算就是实时查询并且对数据进行计算,假设我们遇到了如下计算场景:
A = D + B;
B = C + E;
C = D + E。
我们需要计算得到 A 的值,如何才能最快的计算出结果呢?我们从以下几个方面来分析问题:
2. 单线程
如果是单线程的情况,我们只能线性的去执行任务,最开始计算 a = d + b,先计算 d,然后计算 b,而 b = c + e,只能再去计算 c,而 c = d + e。先计算出 d 和 e 相加得出 c,然后计算 c 加 e 得出 b,最后计算 d 加 b 得出 a。最后我们统计计算 a,一共做了多少次计算:
d 2次
e 2次
c 1次
b 1次
a 1次
这里显而易见,我们做了2次重复计算。有2种方法去解决这个问题:一种是加缓存,一种是拓扑排序。
3. 缓存
增加缓存的方法如下,计算 a 的时候先计算 d 和 b,计算 d 之后把 d 先缓存,然后计算 b,由于 b=c+e,那么需要先计算 c,而 c=d+e,最后需要计算 d+e,而 d 已经缓存了直接从内存取出,再接着计算 e,放入缓存,这样计算 b=c+e 的时候只需要计算 c,e 直接从内存取出。缓存虽然可以解决上面的问题,但也有缺点,首先缓存需要占用内存空间,其次缓存都有淘汰机制,下面介绍一种更优的方法。
4. 拓扑排序
我们可以根据上述的关系,得到如下的依赖图:
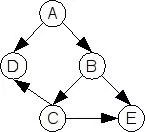
Dependency Graph
实际上我们得到了一个 DAG 的图,可以看出如果要计算 a,我们需要先计算 d 和 b,而计算 b 需要计算 c 和 e,而计算 c 又需要计算 d 和 e,即一件事情依赖另外的一件。这样的例子在生活中有很多,比如早晨起来,你必须先穿袜子才能穿鞋子,而穿鞋子之前你必须得先穿上裤子。这些问题都可以用拓扑排序来解决,思路就是深度优先遍历,优先找出最底层的节点,然后找出次底层的,依次得出结果。最后我们会得到如下的顺序:d e c b a,即按照如下顺序计算,每个节点只需要计算一次,在不产生顺序冲突的同时,得出最短的计算时间。
5. 多线程
上面是单线程的情况,如果是多线程的情况,当然只要我们有足够的资源,多线程肯定是理论上计算时间最短的。但导致的一个问题就是重复计算,浪费计算资源,下面是多线程执行流程图:
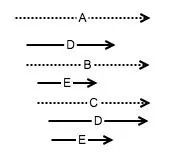
即如果开启6个线程执行,那么最终执行的时间可能是 (这里假定 d 的执行时间比 e 长) d c b a,我们把 e 的计算时间给节省掉了,多线程的情况对缓存来说可以说是灾难性的后果,比如计算 a 开始的时候就开始计算 d 了,而计算 c 的时候 d 如果没有计算完,c 也取不到 d 的缓存,导致缓存可以说是没有太大用处。如果缓存可以取到,才可以节省计算资源。
如果我们按照如下思路,还可以进一步节省计算资源,在上面拓扑排序的基础上,加入层级的概念,比如:
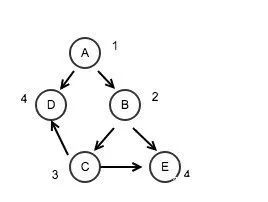
加入层级之后,比如 d 和 e 的层数都是4,那么 d 和 e 可以并行计算,而 c,b,a 的层级分别是3,2,1,进行串行计算。这里很明显,如果层数相同的则进行并行计算,层数不同则串行计算,带来的好处一是节省计算资源,二是节省了计算时间,这才是最优解。
▌流式计算优化之 IO 合并
流式计算还有一种优化是对内存操作和 IO 操作做区分,并进行优化,比如上述情况,如果 d 和 e 开启并行计算,c,b,a 线性计算,从计算的角度来看待,确实是最优的计算方式。但是考虑到计算分为内存计算和 IO 计算,而且 IO 计算的延时比内存计算高几倍到十几倍,因此我们主要的策略就是对 IO 计算做优化,一个比较好的优化思路就是对 IO 做合并,或者对 IO 计算做缓存,下面主要讲述对 IO 计算合并。
还是用下面的例子,我们需要计算如下情况:
A = D + B;
B = C + E;
C = D + E。
根据依赖关系,我们可以得出如下 DAG 的节点图:
即 d,e,c,b,a,我们计算的顺序可以按照如下方式进行,我们先从简单点的情况,然后扩展到复杂的情况。
1. IO 合并
首先我们假设 d 和 e 都是 IO 计算,如果按照之前介绍的拓扑排序然后再并发的思路,那么我们会同时启动2个线程,分别计算 d 和 e。虽然多线程不会增加时间,但是多了一次 IO 操作,带来的影响就是 IO 是有瓶颈的,如果系统的 IO 操作变多,会导致系统抖动和延时,假如我们可以把 d 和 e 做 IO 合并,即一次就可以把 d 和 e 都读取出来,那么系统 IO 的容量就可以提高1倍(实际不到1倍的提升)。
2. IO 不能合并
有2种情况:
1. 如果 d 和 e 是访问的不同的数据库,那么我们的 IO 不能做合并,我们就只能读取2次。
2. 接着我们增加下 IO 合并的复杂程度,比如现在有 d,e,c 这3个节点是 IO 计算,d 和 e 可以做 IO 合并,而 c 需要等待 d 和 e 做 join 操作之后,才能确定读取哪些 IO,这样我们做 IO 合并的时候只能先把 d 和 e 做合并,而不能把 c 做合并,因为在 d 和 e 做 join 操作之后,我们才知道 c 要去查什么数据,因此也做不了合并。
不过上述问题也是可以优化的,这一部分的优化可以通过分支预测和预取操作来解决。
2个数据做 join 操作就是找到2个数据集的合集部分,比如一个数据集是数学成绩,一个数据集是地理成绩,下面我们需要找出数学成绩大于60分,而且地理成绩大于90的学生,那么我们就是找到2个数据集的交集部分,即2个数据集做 join 操作。
▌流式计算优化之分支预测
1. 假设我们有如下计算场景:
if ( isWeekend) {readIO(A);} else {readIO(B);}
可以看到,如果今天是周末,则读取 A,如果今天不是周末,则读取 B。由于 A 和 B 都是 IO 操作,比较耗时,如果 A 和 B 能够合并读取,那么我们当然很开心,我们只需要读取一次就可以了。假如 A 和 B 不能够做 IO 合并,那么遇到的问题是,我们需要先判断是否是周末才能够明白到底去读取哪个 IO,假如我们引入分支预测机制。
2. 分支预测
上述条件,假设进入 A 条件的概率是80%,而进入 B 条件的概率是20%,如果采用分支预测,我们会直接跳过判断,直接去读取 A,然后再去计算判断条件,如果条件判断错误,再回过头去读取 B,这样带来的好处是如果判断正确,那么节省了大量的判断时间,如果判断错误,那么就会重新读取 B,时间反而变长了。前提是预测的足够准确,会提高计算的效率。
3. 预取缓存
对应的计算还有预取操作。还是上面的例子,要计算上面的语句,可以根据统计学来判断,哪些数据有很大的概率需要去取的,优先把这些数据放进缓存,下次计算直接去内存取数据,而不需要从 IO 取数据,这一部分就是热点数据,很多时候会把这部分热点数据保存在分布式的缓存中,能够很大的提高效率。当然预取的机制,缓存的一致性和缓存淘汰的机制对数据命中的效率影响非常大,另外在机器重新启动后,缓存没有建立起来之前,系统面临着没有缓存的情况,导致在启动阶段会有大量延时的情况,这些都是需要考虑的问题。
▌参考资料
1. Dependency Resolving Algorithm
https://www.electricmonk.nl/docs/dependency_resolving_algorithm/dependency_resolving_algorithm.html
2. Topological sorting
https://en.wikipedia.org/wiki/Topological_sorting
▌嘉宾介绍
王方浩,前蚂蚁金服高级软件工程师。一直从事软件相关工作,是操作系统、大数据、自动驾驶相关技术的爱好者。
对作者感兴趣的小伙伴,欢迎点击文末阅读原文,与作者交流。
——END——
文章推荐:
关于 DataFun:
DataFun 定位于最实用的数据智能平台,主要形式为线下的深度沙龙、线上的内容整理。希望将工业界专家在各自场景下的实践经验,通过 DataFun 的平台传播和扩散,对即将或已经开始相关尝试的同学有启发和借鉴。
DataFun 的愿景是:为大数据、人工智能从业者和爱好者打造一个分享、交流、学习、成长的平台,让数据科学领域的知识和经验更好的传播和落地产生价值。
DataFun 成立至今,已经成功在全国范围内举办数十场线下技术沙龙,有超过三百位的业内专家参与分享,聚集了数万大数据、算法相关领域从业者。
点下「在看」,给文章盖个戳吧! 以上是关于流式计算优化:时效性的主要内容,如果未能解决你的问题,请参考以下文章