流式计算引擎之SparkStreaming(上)
Posted 实时个性化推荐
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了流式计算引擎之SparkStreaming(上)相关的知识,希望对你有一定的参考价值。
0.前言
当用户在电商网站上点击了某个商品时,用不了多久就会在首页看到客户可能感兴趣的其他商品。这源于网站在后台实时分析了用户的浏览内容,并快速建立用户画像,返回推荐结果。Spark Streaming是Spark提供的对实时数据进行流式计算的组件。在构建数据仓库时,Spark Streaming还可以实时备份数据,或实时对流入的数据进行转换,将转换的结果输出到另外一套系统之中。在大多数实时处理流式数据的场景中,Spark Streaming都可以胜任。
1.Spark Streaming简介
Spark Streaming的数据处理流程如图1-1所示。先接收实时流的数据,并根据一定的时间间隔拆分成一批批的数据,这些批次数据在Spark内核对应一个RDD实例,因此,流数据的DStream可以看成是一组RDDs,然后通过调用Spark核心的作业处理这些批数据,最终得到处理后的一批批结果数据。通俗点理解的话,在流数据分成一批一批后,通过一个先进先出的队列,然后Spark核心的作业从该队列中依次取出一个个批数据,把批数据封装成一个RDD,然后进行批处理。
图1-1 Spark Streaming数据处理流程
2.案例1:实时词频统计
//1.导入相关依赖import org.apache.spark.streaming.{Seconds, StreamingContext}import org.apache.spark.{SparkConf, SparkContext}object StreamingWordCount {def main(args: Array[String]): Unit = {val conf = new SparkConf().setAppName("Spark Streaming WordCount").setMaster("local[*]")val sc = new SparkContext(conf)//2.初始化StreamingContext,设定5秒统计这一批次出现额单次个数val ssc = new StreamingContext(sc, Seconds(5))val res = ssc//3.设置读取本地机器9999端口中的数据流。//4.当程序运行时,每隔5秒就会将这一批次流入的数据汇总为一个RDD,并存放在DStream中。.socketTextStream("localhost",9999).flatMap(_.split(" "))//5.通过map操作将单词映射为(单词,1)的元组对形式.map((_, 1))//6.通过reduceByKey操作按单词进行聚合统计.reduceByKey(_ + _)//7.打印这一批次额统计结果.print()//8.开始SparkStreaming任务ssc.start()//9.awaitTermination方法会阻塞当前线程,直到手动调用ssc.stopssc.awaitTermination()}}
3.相关术语解释
3.1 DStream
DStream是一个抽象类,最主要的功能是为每一个批次的数据生成RDD实例。在DStream抽象类中定义了一个HashMap类型的变量,用来保存持续产生的数据流,如下所示:
private[streaming] var generatedRDDs = new HashMap[Time, RDD[T]]()Spark Streaming在读取持续流入的数据时,会将其按时间划分成不同的批次,每一个批次的数据都会生成一个RDD。随着时间的推移会产生多个批次的数据,也就会生成多个RDD,犹如滔滔江水连绵不绝。这些RDD都将被保存到一个名为generatedRDDs的HashMap实例中。HashMap实例中的键为Time类型,记录了每个批次数据的时间,如图3-1所示。在图3-1中,Time0-Time1是一个时间间隔,也就是说其中的数据是一个批次的。
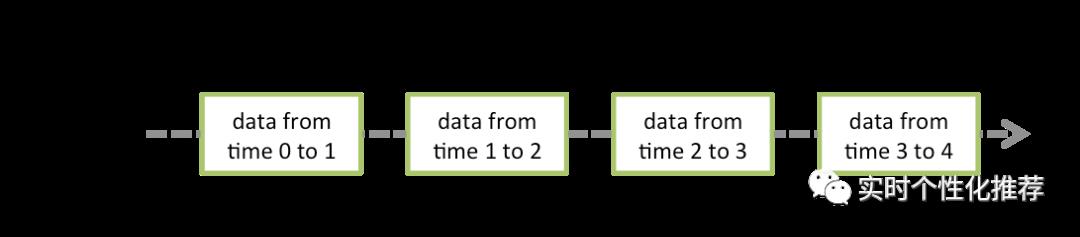
图3-1 DStream中保存数据流的方式
在实时统计词频的案例中,对DStream执行了若干转换操作。以flatMap操作为例,其转换过程如图3-2所示。对DStream执行的大多数操作,其本质都是对RDD执行操作,每个RDD执行完flatMap操作后,会生成新的RDD,这些新RDD会被保存在FlatMappredDStream中,所以DStream与DStream之间也存在着依赖关系。
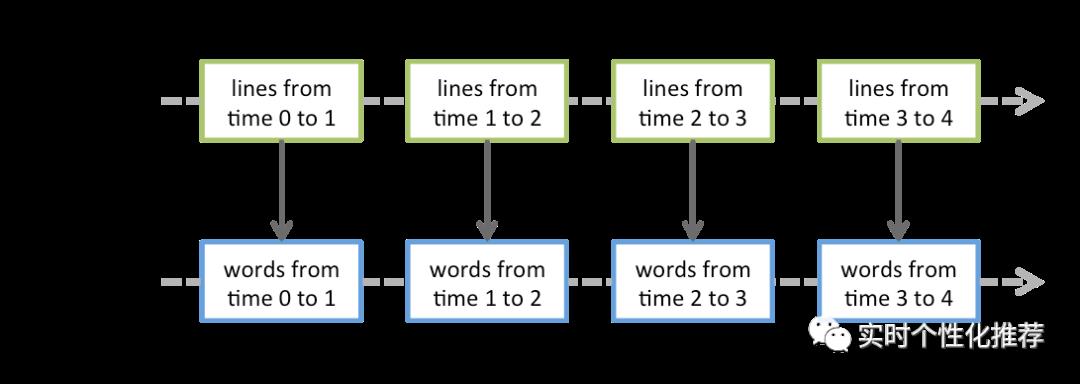
图3-2 DStream执行flatMap操作
3.2 DStreamGraph
在Spark核心中,作业是由一系列具有依赖关系的RDD及作用于这些RDD上的函数所组成的操作链,在遇到行动操作时触发运行,向DAGScheduler提交并运行作业。Spark Streaming作业的生成与Spark核心类似,对DStream执行各种操作让它们之间构建起依赖关系。当遇到DStream使用输出操作时,这些依赖关系以及它们之间的操作会被记录到名为DStreamGraph的对象中表示一个作业。这些作业注册到DStreamGraph并不会立即运行,而是等到Spark Streaming启动后,到达批处理时间时,才根据DStreamGraph生成作业处理该批处理时间内接收的数据。DStream之间的依赖关系保存在DStreamGraph中。当对数据进行print时,DStreamGraph会根据它所包含的DStream之间的依赖关系,生成打印作业输出结果。
除此之外,DStreamGraph还负责生成每个批次作业所对应的Job。只有在DStreamGraph生成了DStream的完整依赖链后,才可以通过generateJobs方法生成Job。在DStreamGraph类中,该方法的源码如下:
def generateJobs(time: Time): Seq[Job] = {logDebug("Generating jobs for time " + time)val jobs = this.synchronized {outputStreams.flatMap { outputStream =>val jobOption = outputStream.generateJob(time)jobOption.foreach(_.setCallSite(outputStream.creationSite))jobOption}}logDebug("Generated " + jobs.length + " jobs for time " + time)jobs}
从上述代码可知,当outputStreams中没有DStream时,是不会生成任何Job的。也就是说如果DStream没有执行任何输出操作,则不会有Job生成。
3.3 批处理间隔
Spark Streaming把持续流入的数据按批处理时间分割成一段一段的,每一段数据会被合并为一个RDD,并将该RDD添加到DStream的HashMap中进行维护。其中每一段数据跨越的时间长度就是批处理间隔(Batch Duration)。即,Spark Streaming持续不断地读取数据,每隔一个批处理间隔就产生一个RDD,该RDD就是这段时间内的数据。
在Scala中设置批处理设置批处理间隔的方式如下:
val ssc = new StreamingContext(sc, Seconds(10)) 其中,Seconds(10)意为设置批处理间隔为10s。Spark Streaming也允许以ms、min为单位设置批处理间隔。
3.4 窗口时间宽度和滑动时间宽度
Spark Streaming将数据按照时间分成了若干批次存储在DStream中,每一个批次都是一个RDD。如果想对局部的多个批次(多个RDD)进行聚合操作,则需要指定起始批次与结束批次对应的时间,这个时间区间就是窗口时间宽度(Window Duration)。
Spark Streaming开始工作后,会随着时间的推进,按照指定的批处理间隔不停地划分出新的RDD。如果只是指定窗口时间宽度,则不能动态持续地对数据进行局部聚合。而Spark Streaming可以设置滑动时间宽度(Slide Duration),使窗口随着时间的推移,持续按照指定的宽度进行移动。它指的是经过多长时间窗口滑动一次形成新的窗口。窗口时间宽度和滑动时间宽度的大小一定得设置为批处理间隔的整数倍。
如图3-3所示,批处理间隔是一个时间单位,窗口时间宽度是3个时间单位,滑动时间间隔是两个时间单位。对应初始的窗口time1~time3,只有窗口时间间隔满足了才会触发作业的处理。同时每两个时间单位窗口向后滑动一次,会有新的数据流入窗口,这时窗口会移去最早的两个时间单位的数据,而与最新的两个时间单位的数据进行汇总形成新的窗口(time3~time5)。
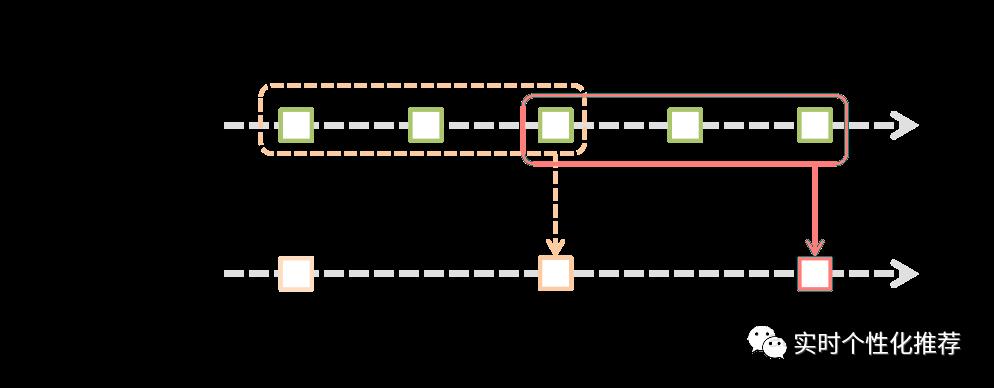
图3-3 批处理间隔示意图
4.Spark Streaming编程模型
4.1 DStream数据源
如图4-1所示,Spark Streaming支持多种数据来源,既可以从文件端口获取数据流,也可以从Flume、Kafka等其他框架获取数据流,然后进行后续的数据转换处理操作,最后将处理结果存储到外部存储系统,如mysql、HBase等。

图4-1 Spark Streaming数据处理流程
4.2 DStream的操作
(1)普通的转换操作
普通的转换操作如表4-1所示。
表 4-1 普通的转换操作
| 转换 |
描述 |
| count() |
对源DStream内部所含有的RDD的元素数据量进行计数,返回一个内部的RDD只包含一个元素的DStream |
reduce(func) |
使用函数func(有两个参数并返回一个结果)将源DStream中每个RDD的元素进行聚合操作,返回一个内部所包含的RDD只有一个元素的新DStream |
| countByValue() |
计算DStream中每个RDD内的元素出现的频次并返回新的DStream[(K,Long)],其中K是RDD中元素的类型,Long是元素出现的频次 |
reduceByKey(func, [numTasks]) |
当一个类型为(K,V)键值对的DStream被调用的时候,返回类型为(K,V)键值对的新DStream,其中每个键的值V都是使用聚合函数func汇总。注意:默认情况下,使用Spark的默认并行度提交任务(本地模式下并行度为2,集群模式下为8) |
join(otherStream, [numTasks]) |
当被调用的类型分别为(K,V)和(K,W)键值对的两个DStream时,返回类型为(K,(V,W))键值对的新DStream |
cogroup(otherStream, [numTasks]) |
当被调用的两个DStream分别含有(K,V)和(K,W)键值对时,返回一个(K,Seq[V],Seq[W])类型的新DStream |
| transform(func) |
通过对源DStream的每个RDD应用RDD-to-RDD函数返回一个新的DStream,这可以用来在DStream做任意RDD操作。 |
| updateStateByKey(func) |
返回一个新状态的DStream,其中每个键的状态是根据键的前一个状态和键的新值应用给定函数func后的更新。这个方法可以被用来维持每个键的任何状态数据。 |
(2)窗口转换操作
窗口转换操作允许通过滑动窗口对数据进行转换,窗口转换操作如表4-2所示。
4-2 窗口转换操作
| 转换 |
描述 |
window(windowLength, slideInterval) |
返回一个基于源DStream的窗口批次计算后得到的DStream |
countByWindow(windowLength, slideInterval) |
返回基于滑动窗口的DStream中的元素的数量 |
reduceByWindow(func, windowLength,slideInterval) |
基于滑动窗口对源DStream中的元素进行聚合操作,得到一个新的DStream |
reduceByKeyAndWindow(func, windowLength,slideInterval, [numTasks]) |
基于滑动窗口对(K,V)键值对类型的DStream中的值按K使用聚合函数func进行聚合操作,得到一个新的DStream |
reduceByKeyAndWindow(func, invFunc,windowLength,slideInterval, [numTasks]) |
一个更高效的实现版本,先对滑动窗口中新的时间间隔内数据增量聚合并移除最早的与新增数据量的时间间隔内的数据统计量。例如,计算t+4秒时刻过去5秒窗口的WordCount,那么可以将t+3时刻过去5秒的统计量加上[t+3,t+4]的统计量,再减去[t-2,t-1]的统计量,这种方法可以复用中间3秒的统计量,提高统计的效率 |
countByValueAndWindow( windowLength, slideInterval, [numTasks]) |
基于滑动窗口计算源DStream中每个RDD内的每个元素出现的频次并返回DStream[(K,Long)],其中K是RDD中元素的类型,Long是元素的频次 |
(3)输出操作
Spark Streaming允许DStream的数据输出到外部系统,如MySQL、Hbase、kudu等,输出的数据可以被外部系统所使用,该操作类似于RDD中的输出操作。表4-3列出了目前主要的输出操作。
表4-3 输出操作
| 转换 |
描述 |
| print() |
在Driver中打印DStream中数据的前10个元素 |
| saveAsTextFiles(prefix,[suffix]) |
将DStream中的内容以文本的形式保存为文本文件,其中每次批处理间隔内产生的文件以prefix-TIME_IN_MS[.suffix]的方式命名 |
| saveAsObjectFiles(prefix,[suffix]) |
将DStream中的内容按对象序列化并且以SequenceFile的格式保存,其中每次批处理间隔内产生的文件以prefix-TIME_IN_MS[.suffix]的方式命名 |
| saveAsHadoopFiles(prefix,[suffix]) | 将DStream中的内容以文本的形式保存为Hadoop文件,其中每次批处理间隔内产生的文件以prefix-TIME_IN_MS[.suffix]的方式命名 |
| foreachRDD(func) |
最基本的输出操作,将func函数应用于DStream中的RDD上,这个操作会输出数据到外部系统,比如保存RDD到文件或MySQL中。func函数是运行在该streaming应用的Driver进程里执行的。 |
(4)DStream中的转换分类
DStream中的转换操作又可以细分为无状态转换和有状态转换两种类别,接下来介绍一下这两种转换操作。
无状态转换,强调对每一个批次的数据转换都是独立的。在处理当前批次数据时。既不会依赖之前的数据,也不会影响后续的数据。例如在单词计数实例中,当前批次统计出的词频并不会与上一个批次的统计结果进行累加。所以无状态转换操作不能对Spark Streaming运行过程中的全部数据进行实时地全局聚合。
在对数据进行有状态转换时,每个批次的数据都可以利用上一个批次的结果。上一个批次的结果,被称为上一个批次的状态。该状态会通过有状态转换操作传入下一个批次中,然后按照定义的操作,将上一个批次和当前批次的数据进行累加,这个过程称为更新状态,如此反复即可实现数据的全局聚合。
5.案例2:Spark Streaming与Kafka的整合
采用Spark Streaming流式处理Kafka中的数据,首先需要把数据从Kafka中接收过来,然后转为SparkStreaming中的DStream。接收数据的方式一共有两种:利用接收器Receiver的方式接收数据和直接从Kafka中读取数据。
Receiver方式通过KafkaUtils.createStream()方法来创建一个DStream对象,它不关注消费位移的处理,Receiver方式的结构如图5-1所示。但这种方式在Spark任务执行异常时会导致数据丢失,如果要保证数据的可靠性,则需要开启预写式日志,简称WAL(Write Ahead Logs),只有收到的数据被持久化到WAL之后才会更新Kafka中的消费位移。收到的数据和WAL存储位置信息被可靠地存储,如果期间出现故障,那么这些信息被用来从错误中恢复,并继续处理数据。
图5-1 Receiver方式的结构
Direct方式是从Spark1.3开始引入的,它通过KafkaUtils.createDirectStream()方法创建一个DStream对象,Direct方式的结构如图5-2所示。该方式中Kafka的一个分区与SparkRDD对应,通过定期扫描所订阅的Kafka每个主题的每个分区的最新的偏移量以确定当前批处理数据偏移范围。与Receiver方式相比,Direct方式不需要维护一份WAL数据,由Spark Streaming程序自己控制位移的处理,通常通过检查点机制处理消费位移,这样可以保证Kafka中的数据只会被Spark拉取一次。
图5-2 Direct方式的结构
在Spark官网中,关于Spark Streaming与Kafka集成给出了两个依赖版本,一个是基于Kafka0.8之后的版本(spark-streaming-kafka-0-8),另一个是基于Kafka0.10及其之后的版本(spark-streaming-kafka-0-10)。spark-streaming-kafka-0-8版本的Kafka与Spark Streaming集成有Receiver和Direct两种接收数据的方式,不过spark-streaming-kafka-0-8从Spark2.3.0开始被标注为弃用。而spark-streaming-kafka-0-10版本只提供Direct方式,同时底层使用的是新消费者客户端KafkaConsumer而不是之前的旧消费者客户端。
下面基于spark-streaming-kafka-0-10版本从kafka中读取数据。
案例描述:用kafka持续收集用户行为数据,数据内容为用户ID、商品ID、时间戳及用户行为(1点击2收藏3购买)。同时用Spark Streaming读取Kafka中的数据,过滤得到点击数据然后在控制台输出。
// 1.导入相关依赖import org.apache.kafka.clients.consumer.ConsumerConfigimport org.apache.kafka.common.serialization.StringDeserializerimport org.apache.spark.SparkConfimport org.apache.spark.streaming.kafka010.ConsumerStrategies._import org.apache.spark.streaming.kafka010.KafkaUtilsimport org.apache.spark.streaming.kafka010.LocationStrategies._import org.apache.spark.streaming.{Seconds, StreamingContext}Object StreamingWithKafka {private val brokers = "localhost:9092"private val topic = "topic-spark"private val group = "group-spark"private val checkpointDir = "checkpoint"def main(args:Array[String]): Unit = {val conf = new SparkConf().setMaster("local[*]").setAppName("StreamingWithKafka")val ssc = new StreamingContext(conf, Seconds(2))ssc.checkpoint(checkpointDir)val kafkaParams = Map[String, Object](ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG -> brokers,ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG -> classOf[StringDeserializer],ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG -> classOf[StringDeserializer],ConsumerConfig.GROUP_ID_CONFIG -> group,ConsumerConfig.AUTO_OFFSET_RESET_CONFIG -> "latest",ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG -> (false: java.lang.Boolean))val stream = KafkaUtils.createDirectStream[String, String](ssc, PreferConsistent,Subscribe[String, String](List(topic), kafkaParams))val result = stream.map(_.value().split(",")).filter(arr => {if (arr.length == 4) {Try(arr(3).toInt) match {case Success(_) if arr(3).toInt == 1 => truecase _ => false}} else {false}}).map(_.mkString(",")).foreachRDD(rdd => {// 在Driver上执行rdd.foreachPartition(p => {// 在excutor上执行p.foreach(record => {// 在excutor上执行println(result)})})})ssc.start()ssc.awaitTermination}}
KafkaUtils.createDirectStream()方法的第一个参数是StreamingContext实例,第二个参数是LocationStrategies类型的,用来指定spark执行器节点上KafkaConsumer的分区分配策略。LocationStrategies类型提供了三种策略:PreferBrokers策略,必须保证执行器节点和Kafka Broker在相同的机器上,这样可以根据分区副本的leader节点来进行分区分配;PreferConsistent策略,该策略将订阅主题的分区均匀地分配给所有可用的执行器,在大多数情况下都使用这种策略。第三个参数是ConsumerStrategies类型的,用来指定Spark执行器节点的消费策略。有三种消费策略,Subscribe、SubscribePattern和Assign,分别代表通过指定集合、通过正则表达式和通过指定分区的方式进行订阅。
使用SubscribePattern策略消费Kafka中数据:
val stream = KafkaUtils.createDirectStream[Stirng, String](ssc, PreferConsistent,SubscribePattern[String, String](Pattern.compile("topic-.*"), kafkaParams))
使用Assign通过指定分区的方式消费Kafka中的数据:
val partitions = List(new TopicPartition(topic, 0),new TopicPartition(topic, 1),new TopicPartition(topic, 2),new TopicPartition(topic, 3))val stream = KafkaUtils.createDirectStream[String, String](ssc, PreferConsistent,Assign[String, String](partitions, kafkaParams))
从指定的位置处处理数据,示例中的fromOffsets变量指定了每个分区的起始处理位置为5000:
val partitions = List(new TopicPartition(topic, 0),new TopicPartition(topic, 1),new TopicPartition(topic, 2),new TopicPartition(topic, 3))val fromOffsets = partitions.map(partition => {partition -> 5000L}).toMapval stream = KafkaUtils.createDirectStream[String, String](ssc, PreferConsistent,Subscribe[String, String](List(topic), kafkaParams, fromOffsets))
6.小结
推荐系统必须能够快速的捕获到用户的行为事件数据,然后实时更新模型,学习新的知识,最后将推荐结果实时的反馈的用户。整个实时推荐是建在流计算平台上的,Spark Streaming是Spark核心API的一个扩展,具有吞吐量高、容错能力强的实时流数据处理系统。本文首先介绍了Spark Streaming中的一些基本概念术语,然后总结了DStream常用的操作算子,最后通过一个案例演示了Spark Streaming从Kafka中读取数据并进行实时统计。下一篇中将重点介绍Spark Streaming的原型原理和运行架构。
以上是关于流式计算引擎之SparkStreaming(上)的主要内容,如果未能解决你的问题,请参考以下文章