转载Spark Streaming中流式计算的困境与解决之道
Posted Qunar技术沙龙
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了转载Spark Streaming中流式计算的困境与解决之道相关的知识,希望对你有一定的参考价值。
Spark streaming 在各种流程处理框架生态中占着举足轻重的位置, 但是不可避免地也会面对网络波动带来的数据延迟的问题,所以必须要进行增量数据的累加。 在更新Spark 应用的时候或者其他不可避免的异常宕机的时候,增量累加会带来重复消费的问题,在一些需要严格保证 exact once 的场景下, 这个时候我们就需要进行离线修复,从而保证exact once 语义, 本文将针对这个问题,提供一些常见的解决方案和处理方式。
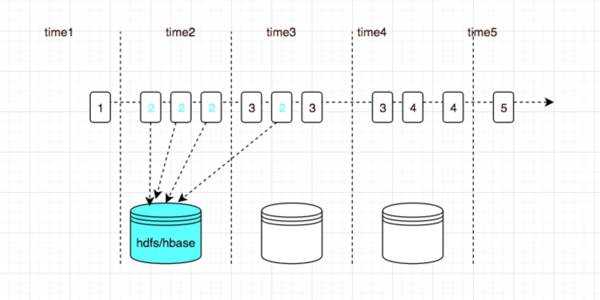
下图中展示了数据延迟的一个场景:
在讨论解决消息乱序问题之前,需先定义时间和顺序。在流处理中,时间的概念有两个:
Event time :Event time是事件发生的时间,经常以时间戳表示,并和数据一起发送。带时间戳的数据流有,Web服务日志、监控agent的日志、移动端日志等;
Processing time :Processing time是处理事件数据的服务器时间,一般是运行流处理应用的服务器时钟。
上图中 time1,time2, time3等是我们Spark straming 拿到消息将要处理的时间, 图中方块中的数字代表这个event 产生的时间, 有可能因为网络抖动导致部分机器上的日志收集产生了延迟, 在time3的batch中包含event time 为2的日志, 特别说明一下, kafka 中的不同分区的消息也是没有顺序的。
在实时处理过程中也就产生了两个问题:
Spark streaming 从Kafka 中拉取到的一批数据,我们可能认为里面包含多个时间区间的数据
同一个时间的数据可能出现在多个 batch 中
但是对于第二个问题,就很麻烦, 图中举例, 时间区间中 2 出现在了 time2 和time3, 我们需要在两个batch中计算出2 的指标, 然后进行累计, 这个累计的过程, 你可以在内存中保存状态, 使用Spark streaming 中的 UpdateStateByKey等算子, 但是不推荐这样使用, 这样就在你的应用中引入了状态和Checkpoint机制, 还有一个方法, 就是把这个状态放在持久化存储中, 比如每次都在 Redis, 或者Hbase 中进行累计,Spark 从 Kafka 拉取日志是可以做到 至少消费一次,但是这种模式 很难保证 exact once 。
假如有下面一种情形,
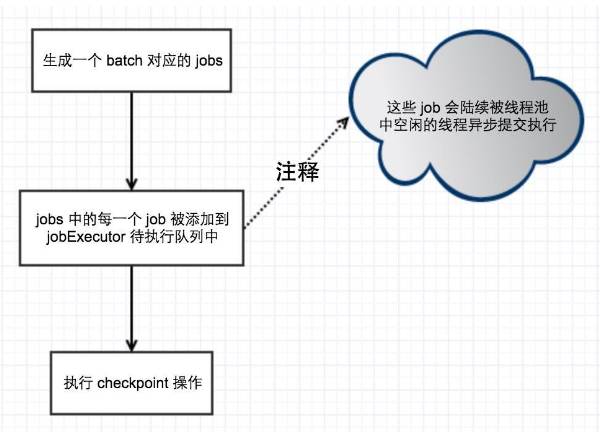
就会存在这种情况, 我们对 job1 执行 Checkpoint 操作, 然后 job1 被调度执行, 从Kafka 拉取数据处理, 然后结果保存在HBase 中, 保存了一半, 机器挂了, 如果重启,recover, 这时候 job1 就会被重复执行, Kafka 中的数据就会被重复消费, HBase中的部分指标也就多加了一份,虽然我们可以使用 Spark 或者 Flink 中提供的 Watermark 功能。
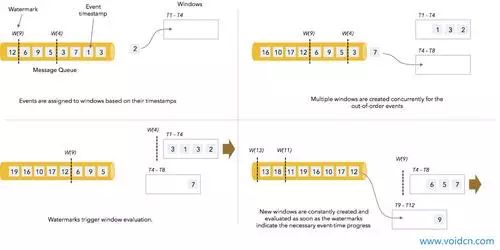
也就是维护一个窗口, 然后设置一个最大等待时间, T1 ~T4 中的数据到了最大等待时间后就会触发计算,但是这样也会有问题, 如果部分数据的延迟超过了最大等待时间, 这部分数据也就永远的丢失了。
当然如果业务可以容忍, 那么使用这个功能也是可以的,每次都使用 全量覆盖操作。
以上我们面临的问题是 Spark streaming + Kafka 组合可以保证at lease once ,但是很难保证 exact once, 也就是会重复消费, 我们得想办法做到去重, 计算结果 落地存储会有两种模式:
append 增量的模式, 也就是每次都做累加
complete的模式, 也即是保证幂等性, 每次都是覆盖, 保证没有副作用
因为同一个时间的数据可能出现在多个 batch 中,所以我们在准实时计算中, 只能是append 模式, 上文我们已经论证过了,这种模式会出现重复消费的问题。
由于机器挂了的现象是偶发的, 所以我们可以在挂掉后, 对数据进行离线修复, 也就是我们要保证有一份全量的离线数据。
这份数据我们要保证是不漏不多, 而且是按照event time 时间区间分开的, 这样我们就可以针对出问题的时间区间, 加载这个时间区间的离线数据, 算出结果, 然后进行覆盖。这样就保证了数据的准确性。
我们落地的数据的特点是:
全量的,不漏不多
按照定义的时间区间分片
因为从Kafka 中拉取存储能保证不丢, 这里我们考虑如何去重, 首先我们要对消息能有一个唯一 ID, 我们使用Kafka的partition加offset作为这个消息的唯一ID, 如果存储到HBase, 这样的话在生成一个消息的时候,我们的ID就不会重复,即使你重跑很多次,HBase会自动把它去重。
如果存储到 hdfs, 我们可以每行数据前面都用 ID 作为头字段, 离线处理的时候根据这个字段先进行去重处理,这样也能保证了 exact once 语义。
我们看下 Spark streaming 存储到HDFS或者HBase 都会调用 saveAsHadoopDataset。
val writer = new SparkHadoopWriter(hadoopConf)
writer.open()
Utils.tryWithSafeFinallyAndFailureCallbacks {
while (iter.hasNext) {
val record = iter.next()
writer.write(record._1.asInstanceOf[AnyRef], record._2.asInstanceOf[AnyRef])
}
}(finallyBlock = writer.close())
writer.commit()这里根据你传入的 OutFormat 调用 getwriter。
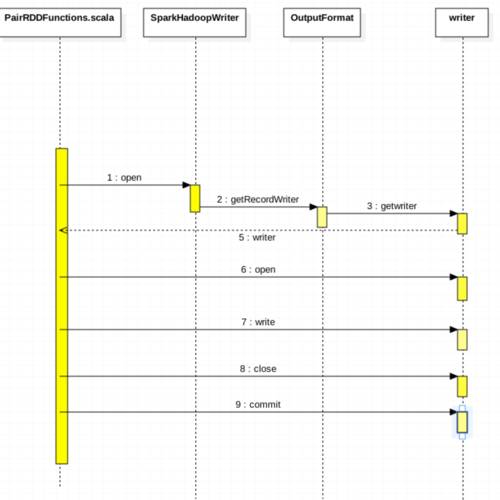
然后再 writer上调用 open write close commit 方法。
这里如果是 HBase 就是调用 HBase client 的写入方法:
用户提交put请求后,HBase客户端会将put请求添加到本地buffer中,符合一定条件就会通过AsyncProcess异步批量提交。HBase默认设置autoflush=true,表示put请求直接会提交给服务器进行处理;用户可以设置autoflush=false,这样的话put请求会首先放到本地buffer,等到本地buffer大小超过一定阈值(默认为2M,可以通过配置文件配置)之后才会提交。很显然,后者采用group commit机制提交请求,可以极大地提升写入性能,但是因为没有保护机制,如果客户端崩溃的话会导致提交的请求丢失。
在提交之前,HBase会在元数据表.meta.中根据rowkey找到它们归属的region server,这个定位的过程是通过HConnection的locateRegion方法获得的。如果是批量请求的话还会把这些rowkey按照HRegionLocation分组,每个分组可以对应一次RPC请求。
HBase会为每个HRegionLocation构造一个远程RPC请求MultiServerCallable
,然后通过rpcCallerFactory.
newCaller()执行调用,忽略掉失败重新提交和错误处理,客户端的提交操作到此结束。
这里如果是 HDFS 文件写入:
首先根据 TaskAttemptID构造出来一个临时写入路径,构造一个文件流
写入临时写入路径
commit 的时候调用
commitTask根据目标路径是否存在, 如果已经存在就删除临时文件,报错, 如果不存在就直接 rename, 把临时文件名, 改为目标文件名, 这里主要是防止多个分区写入同一个目标文件,导致的冲突。
如果有一个需求,需要把数据根据不同的key输出到不同的文件中, 上文中,我们先根据 batch 进行分组, 然后不同分组的文件输出到不同的文件,这时候就需要用到MultipleOutputFormat
TreeMap<String, RecordWriter<K, V>> recordWriters = new TreeMap<String, RecordWriter<K, V>>();
K actualKey = generateActualKey(key, value);
V actualValue = generateActualValue(key, value);
RecordWriter<K, V> rw = this.recordWriters.get(finalPath);
if (rw == null) {
rw = getBaseRecordWriter(myFS, myJob, finalPath, myProgressable);
this.recordWriters.put(finalPath, rw);
}
rw.write(actualKey, actualValue);这里就是维护了一个TreeMap, 里面每个不同的key, 构造一个 writer, 这个writer 是getBaseRecordWriter -> theTextOutputFormat.getRecordWriter根据临时路径构造出一个输出流, 包装为一个 LineRecordWriter 最终的 writer就是在这个 DataOutputStream 上进行输出,
上层多文件输出根据不同的key, 从treeMap上获取到不同的文件输出流, 然后进行多文件输出。
这里会存在一个问题, 同一个时间的数据可能出现在多个 batch 中, 就是会产生很多小文件,HDFS 对小文件支持很差,我们需要合并小文件,但是我们也可以直接在输出的时候进行 append 操作,就直接避免了产生小文件。
这里就需要改源码了。
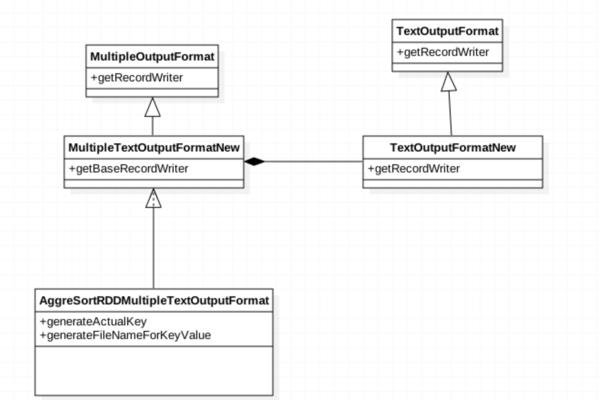
上面的类图可以清楚的显示类图的关系, MultipleOutputFormat 的writer 会调用子类的 getBaseRecordWriter, 我们可以在这里改写一下, 使用我们自己的 TextOutputFormatNew 的 getRecordWriterNew 方法, 在方法里面构造输出流的时候, 如果文件已经存在,就进行 append 操作。
val fileOut: FSDataOutputStream = if (HDFSFileService.existsPath(file)) {
println("appendfile")
fs.append(file)
} else {
println("createfile")
fs.create(file, progress)
} def getTaskOutputPath(job: JobConf, iname: String): Path = {
val name: String = job.get(org.apache.hadoop.mapreduce.lib.output.FileOutputFormat.OUTDIR)
val completePath = name + "/" + iname
val path = new Path(completePath)
path
}把构造临时路径的方法也修改了, 强制不产生临时路径, 每次都往同一个文件中进行 append, 这样就达到了目的。
本文提供的解决方案, 在不修改Spark 源码本身的前提下, 进行了一些必要的扩展, 其实本质上来讲, 就是我们假定异常状况是经常发生的, 我们就要面对它,就是要对输入流 kafka 中的原始数据进行唯一标识,保证可以去重,然后持久化。 对发生异常的时间区间, 进行数据重放,就像数据中用 redo 日志进行重放一样。
以上是关于转载Spark Streaming中流式计算的困境与解决之道的主要内容,如果未能解决你的问题,请参考以下文章