Impala的信息仓库:解读TQueryExecRequest结构
Posted CSDN大数据
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Impala的信息仓库:解读TQueryExecRequest结构相关的知识,希望对你有一定的参考价值。
作者简介:查锐,明略数据高级工程师,对开源技术兴趣浓厚,尤其对大规模分布式并行处理技术有深入研究,具备丰富的大数据存储,计算和查询优化方面的项目经验。
责编:仲浩(zhonghao@csdn.net)
本文为《程序员》原创文章,未经允许不得转载,更多精彩文章请订阅2016年程序员
相信很多做海量数据处理和大数据技术研发的朋友对Impala这个基于Hadoop的交互式MPP引擎都不陌生,尤其对 Impala出色的数据处理能力印象深刻。在查询执行的整个生命周期内,Impala主要通过Frontend生成优化的查询计划,Backend执行运 行时代码生成来优化查询效率。在客户端的一个SQL查询下发到ImpalaServer后,Frontend会在生成查询计划的过程中,收集必要的统计信 息,作为Backend分布式执行的依据。这些信息主要包括:表结构、分区统计、SQL语句的表达式集合,以及执行计划分片描述等。这些信息的集合在 Impala中被称为TQueryExecRequest。通过名字可以看出,这是个Thrift结构,由Frontend封装,通过Impala服务开 启的ThriftServer发送到后端的Coordinator。可以说,TQueryExecRequest结构就是Impala执行查询的信息仓 库,熟悉这个结构有助于理解整个Impala的分布式架构实现。
TQueryExecRequest结构组成
TQyeryExecRequest结构中,主要包含如下成员:
TDescriptorTable desc_tbl vector<tplanfragment> fragments vector<int32_t> dest_fragment_idx map<tplannodeid, vector<tscanrangelocations=""> > per_node_scan_ranges TResultSetMetadata result_set_metadata TFinalizeParams finalize_params TQueryCtx query_ctx string query_plan TStmtType::type stmt_type int64_t per_host_mem_req int64_t per_host_vcore vector<tnetworkaddress> host_list string lineage_graph</tnetworkaddress></tplannodeid,></int32_t></tplanfragment>描述符表
描述符表的类型为TDescriptorTable,包含和查询结果相关的table、tuple以及slot描述信息。
这里需要说明的是,无论提交的SQL查询有多复杂,包括数据过滤、聚合、JOIN,都是在对HDFS或HBase(所查询分区内的)全量数据扫描的基础上进行的。数据扫描结果集的每一行都是一个tuple,tuple中的每个字段都是一个slot。描述符表有如下成员:
vector<tslotdescriptor> slotDescriptorsvector<ttupledescriptor> tupleDescriptorsvector<ttabledescriptor> tableDescriptorsTuple描述符
在Impala中,一个查询返回结果集中的每一行叫做一个tuple,对tuple的描述信息存放在tuple描述符结构中。tuple描述符有如下成员:
TTupleId id;
int32_t byteSize;
int32_t numNullBytes;
TTableId tableId;id是表中的tuple id,截止到Impala2.2版本,一个tupleRow中只会有一个tuple,因此id总是0。
byteSize是一个tuple中所有slot大小的和,再加上nullIndicator占用的字节数。
numNullBytes指的是,如果tuple中的一个slot可以为NULL,则需要占用tuple 1个bit大小的空间,numNullBytes等于(N + 7) / 8,N是可能为NULL的slot个数。例如在一个tuple中,可能为NULL的slot数为0,则numNullBytes=0,也就是不需要额外的 空间去存储null indicator的信息;如果可以为NULL的slot数为1-8,则numNullBytes为1。
tableId是tuple所属的table id。
Slot描述符
slot描述信息存放在TSlotDescriptor结构中,主要用来存放所查询表中某个字段的相关信息,成员包括:
TSlotId id
TTupleId parent
TColumnType slotType
vector<int32_t> columnPath
int32_t byteOffset
int32_t nullIndicatorByte
int32_t nullIndicatorBit
int32_t slotIdx
bool isMaterialized</int32_t>id在一个tuple中唯一标识一个slot。
parent代表slot所在的tuple id。
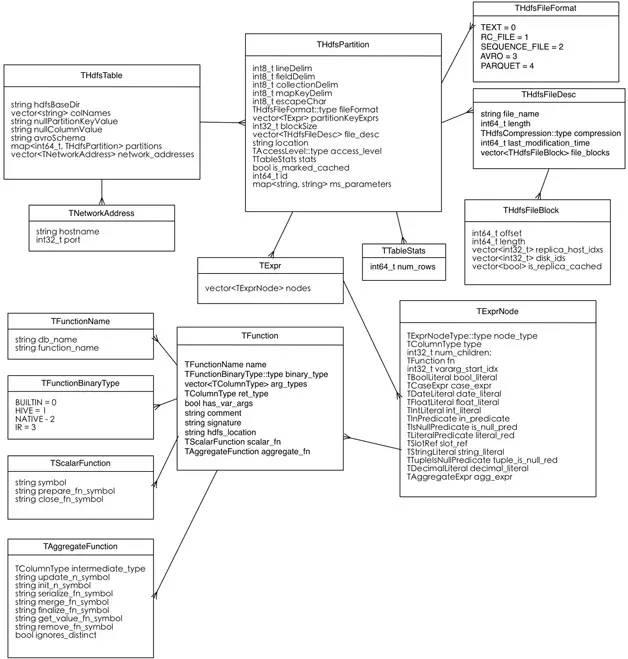
slotType 是slot所在的column类型。对于Parquet嵌套文件格式来说,一个TColumnType可能有多个TTypeNode。例如,一个 STRUCT类型可能包含多个SCALAR类型。一个TTypeNode的类型可能是标量的(确定的内建类型)、数组(ARRAY)、映射(MAP)或者 结构(STRUCT)。目前Impala的2.3版本已经支持ARRAY、MAP和STRUCT这三种复杂类型(仅限Parquet文件格式),这个新特 性应该会使更多的人转向Impala阵营。TColumnType的结构如图1所示。
columnPath是一个整型集合,但是在前端 只会填充一个元素,因为一个slot只对应一个columnPath。columnPath代表一个slot在表中的位置,如create table t (id int, name string),则id的columnPath为0,name的columnPath为1。对于分区表,partition key字段的columnPath会排在前面。如create table t(id int、name string、calling string)partitioned by (date string, phone int),则date的columnPath为0, phone的columnPath为1, id的columnPath为2,name的columnPath为3,calling的columnPath为4。在查询时,columnPath的顺 序是按照column在提交的SQL语句中出现的顺序排列的,如select name from t where date = ‘2016-01-01’ and calling = ‘123’ and phone = abs(fnv_hash(‘123’)) % 10这个SQL,columnPath的顺序为3, 0, 4, 1。
byteOffset是slot在tuple中的偏移,单位为字节。
nullIndicatorByte表明当前slot为NULL时,在tuple的哪个字节中。
nullIndicatorBit表明当前slot为NULL时,在第nullIndicatorByte个字节的哪个bit上。
slotIdx是slot在tuple中的序号。
isMaterialized表明当前slot是否被物化。对于partition key,也就是clustering column来说,isMaterialized为false,也就是partition key不会被物化。
Table描述符
Table描述符包含和查询相关表的信息,包括表字段、类型、分区等信息。成员包括:
TTableId id;
TTableType::type tableType;
int32_t numCols;
int32_t numClusteringCols;vector<string> colNames;
THdfsTable hdfsTable;
THbaseTable hbaseTable;
TDataSourceTable dataSourceTable;string tableName;string dbName;在一个查询中,id字段唯一标识一个表。
tableType表明表的类型,TTableType为枚举类型,包括HDFS_TABLE = 0,HBASE_TABLE = 1,VIEW = 2,DATA_SOURCE_TABLE = 3。
numCols代表table中column的个数。
numClusteringCols代表table中clustering column的个数,也就是parititon的个数。
colNames代表table中所有column的名称的集合。
THdfsTable中的分区信息
THdfsTable结构中包含当前table和HDFS相关的所有信息。关于hdfs table中的partition信息,有如下说明:
partition key的类型只能是标量的,如int、float、string、decimal、timestamp。
不同的partition可以有不同的的文件格式,用户可以在一个表中,增加、删除分区,为分区设置特定的文件格式:
[localhost:21000] > create table census (name string) partitioned by (year smallint);
[localhost:21000] > alter table census add partition (year=2012); -- text format[localhost:21000] > alter table census add partition (year=2013); -- parquet format[localhost:21000] > alter table census partition (year=2013) set fileformat parquet;THdfsTable结构中的partitions类型为map,这个字段不能为空,即使没有为表指定分区,也会有一个默认的partition。
partitions 的Size为表中partition的总数。例如,一个表按month、day以及postcode分区,有12个month,每个month中30个 day,每个day中100个postcode,则partition数为12 * 30 * 100=36000(如上面的例子一个表按month、day以及postcode分区,month为string类型,day为int类 型,postcode为bigint类型,则partitionKeyExprs中的三个成员(TExpr)中的nodes的唯一一个元素 (TExprNode)的node_type分别为STRING_LITERAL(11)、INT_LITERAL(4)和 INT_LITERAL(4))。
THdfsPartition结构中的partitionKeyExprs类型为TExpr的集合,每个 parititon key的信息由一个TExpr描述。这里的TExpr的类型是标量类型(partition key只能是标量类型)的字面值,基类为LiteralExpr,根据不同的partition key类型,可能是StringLiteral、IntLiteral等。
TExpr的成员类型是TExprNode的集合,由于partition key的类型为LiteralExpr,所以这里的TExprNode集合中只会有一个成员,因为在Expr树中,LiteralExpr节点不会再有孩子Expr。
THdfsPartition 结构中的file_desc成员类型为THdfsFileDesc的集合,这表明一个分区下可能会有多个文件。THdfsFileDesc结构中的 file_blocks成员类型为THdfsFileBlock的集合,这表明一个文件可能由多个block组成,在THdfsFileBlock中指定 了block的大小、在文件中的偏移量等。
THdfsTable结构如图2所示。
执行计划分片
一个查询请求提交给 ImpalaServer之后,会在后端调用JNI初始化一个前端的Frontend实例,由这个实例对提交的SQL语句做语法分析,找出和查询相关的 table、scanList以及expr信息,通过这些信息构造执行节点(如HdfsScanNode、AggreagtionNode、 HashJoinNode),根据节点类型评估节点为分布式执行还是本地执行,执行节点组成执行计划分片,最终构造出整个执行计划。
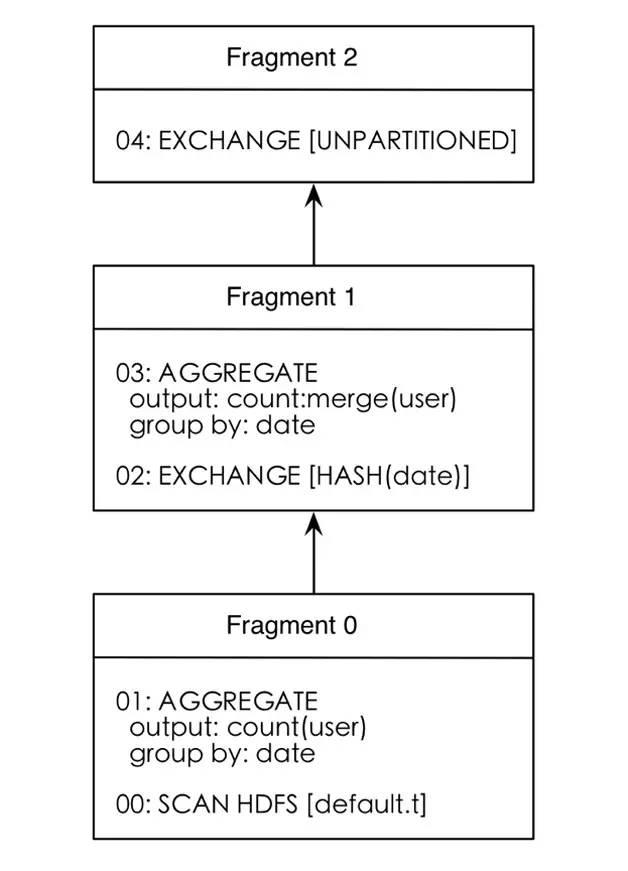
例如,客户端提交了一个SQL请求select date, count(user) from t group by date,通过前端语法分析,可以得到如下信息:
scanList由date和user字段组成。
groupingExpr是一个SLOT_REF类型的表达式(date字段)。
aggregateExpr是一个AGGREGATE_EXPR类型的表达式(count(STRING)),它的孩子是一个SLOT_REF类型的表达式(user字段)。
根据这些信息可以得到如图3所示的执行计划。
下面分析TQueryExecRequest中 的执行计划分片(fragments)结构。fragments是一个TPlanFragment类型的集合,一个TPlanFragment中包含和一 个执行计划分片相关的所有信息。TPlanFragment结构的成员如下:
string display_name
TPlan planvector<texpr> output_exprs
TDataSink output_sink
TDataPartition partition执行计划分片中的执行节点信息
TPlanFragment结构中的plan成员的类型为TPlan,包含一个执行分片中的节点及其相关的表达式信息。TPlan结构如图4所示。
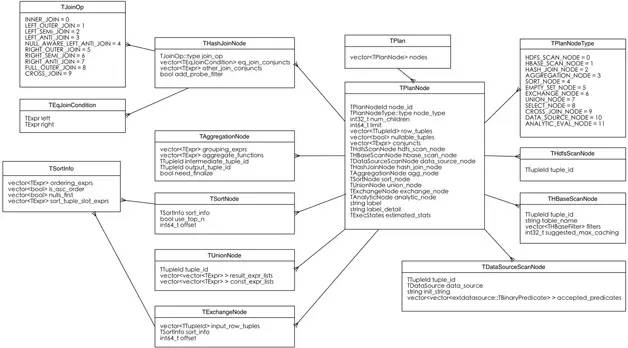
需要说明的是,TPlan的成员是TPlanNode的集合,每个TPlanNode包含一个执行节点的信息。
全局conjuncts
TPlanNode 结构中的conjuncts成员包含where子句的过滤条件,是TExpr类型的集合,而TExpr的成员又是TExprNode类型的集合。也就是 说,conjuncts包含了至少一棵表达式树,表达式树的信息由TExpr描述,树中的每个节点的信息由TExprNode描述。表达式树的叶子节点的 表达式类型一般是SLOT_REF或者LITERAL,非叶子节点的表达式类型一般是FUNCTION_CALL或者PREDICATE。 FUNCTION_CALL可能是内建的,也可能是Hive或者Impala的UDF;PREDICATE可能是COMPOUND_PRED(and和 or)、LIKE_PRED(a like ‘%b%’)或者IN_PRED(a in (1, 2, 3))等。例如,where子句中的过滤条件为phone = ‘123’ OR imsi IS NOT NULL,则这个conjuncts树如图5所示。

聚合操作节点TAggregationNode
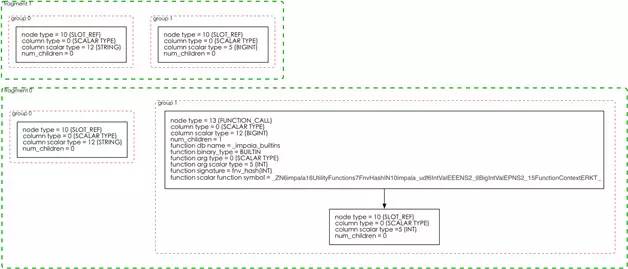
如 果TPlanNode是一个TAggregationNode,那么在TAggregationNode这个结构中有两个比较重要的字段,一个是 grouping_exprs,另一个是aggregate_functions。grouping_exprs的类型是一个TExpr集合,存储了至少 一棵TExpr树。grouping_exprs中的每棵TExpr树描述了一个分组(group),例如group by fnv_hash(date)分组中的fnv_hash(phone)就是在grouping_exprs的一棵TExpr树中描述的,树的叶子节点的表 达式类型为SLOT_REF,父节点为FUNCTION_CALL。和grouping_exprs类似的是,aggregate_functions也 是一个TExpr集合,只不过它描述的是聚合函数的信息,例如聚合函数count(user)在aggregate_functions的一棵TExpr 数中描述,叶子节点的表达式类型为SLOT_REF,父节点表达式类型为AGGREGATE_EXPR。
对于一个聚合操作来说,执行计划的 最底层两个分片都会包含AggregationNode,但是这两个AggregationNode的grouping_exprs和 aggregate_functions中的TExprNode节点类型以及节点的字面值(scalar_type)类型不尽相同。第0个分片中的聚合操 作是UNPARTITIONED的,也就是说当前聚合操作的结果要广播给下一个分片,分片1中的AggregationNode收到所有分片0的多个实例 广播的本地聚合后的数据集,做最后的数据merge。这就比较好理解这两个分片中的AggregationNode的grouping_exprs和 aggregate_functions中的TExprNode节点类型为何不同了。例如,group by a, fnv_hash(b)这个分组,分片0的TAggregationNode中的grouping_exprs中的第二个TExpr树描述了 fnv_hash(b)操作,由两个TExprNode组成,根节点类型为FUNCTION_CALL;而分片1中TAggregationNode中的 grouping_exprs中的第二个TExpr树只有一个TExprNode,类型为SLOT_REF。如图6所示。
join操作节点THashJoinNode
如 果TPlanNode是一个THashJoinNode,则有两个比较重要的字段,一个是eq_join_conjuncts,另一个是 other_join_conjuncts。eq_join_conjuncts的类型是 TEqJoinCondition,TEqJoinCondition的成员是名为left和right的两个TExpr。这个比较好理解,left和 right分别代表join子句中等号两边的表达式。例如t1 join t2 on t1.a=t2.a,那么left这个TExpr中只有一个TExprNode,表达式类型为SLOT_REF,right这个TExpr中也只有一个 TExprNode,表达式类型同为SLOT_REF。这里需要重点说一下other_join_conjuncts这个结构。大家可以看一下 Impala前端的HashJoinNode代码,其中对other_join_conjuncts的解释是:join conjuncts from the JOIN clause that aren’t equi-join predicates,单看起来似乎说的很明确,就是在join子句中出现非equi-join的条件时会设置 other_join_conjuncts。但其实这里有个前提,就是只有在outer join和semi join这两种操作中,other_join_conjuncts才会被设置,inner join的情况并不会设置other_join_conjuncts。这里通过一个例子来说明会比较容易理解。比如我有两张表,左表t1中的数据如下:

右表t2中的数据如下:

对于这两张表,我们先来找出两张表姓名相同,性别不同的记录的交集,这里我们使用inner join,SQL语句如下:
select t1.name, t1.gender, t2.gender from t1 inner join t2 on t1.name = t2.name and t1.gender != t2.gender在这里,impala会自动将t1.gender != t2.gender转化为全局的conjuncts,转换后的SQL语句为:
select t1.name, t1.gender, t2.gender from t1 inner join t2 on t1.name = t2.name where t1.gender != t2.gender返回的结果集如下:

这种变换是很容易理解的,先找出名字相同的记录,再全局过滤掉join返回的结果集中性别相同的记录。现在考虑另外一种情况,返回左表的所有记录,并以姓名相同,性别不同的条件join右表,这里我们使用left outer join,SQL语句如下:
select t1.name, t1.gender, t2.gender from t1 left outer join t2 on t1.name = t2.name and t1.gender != t2.gender返回的结果集如下
可 以看到left outer join返回了左表的所有记录,但是由于两张表中姓名为a的记录的性别相同,不符合left outer join子句中的“姓名相同但性别不同”的约束条件,因此对应的记录中t2.gender的值为NULL。那么考虑一下,可否像inner join那样,把outer join中的non equiv-conjuncts转化为全局的conjuncts呢?答案是否定的。先来看一下left outer join转化后的SQL语句和对应的结果。转化后的SQL语句如下:
select t1.name, t1.gender, t2.gender from t1 left outer join t2 on t1.name = t2.name where t1.gender != t2.gender返回的结果集如下:
可以看到outer join子句中的non equiv-conjuncts转化为全局conjuncts之后,结果集中姓名b对应的记录被过滤掉了,这当然不是我们想要的结果。
之所以不能将outer join子句中的non equiv-conjuncts转化为全局conjunts,是因为无论join子句中是否存在non equiv-conjuncts,最终的结果集都应该包含左表(left outer join)或者右表(right outer join)的全部记录。因此en_join_conjuncts和other_join_conjuncts两部分信息能够决定带有non equiv-conjuncts的outer join或semi join的正确性,将non equiv-conjuncts转换成全局conjuncts并不是正确的做法。
和查询结果列相关的表达式信息
我们提交 的查询结果集中的每一列都是一个表达式,在TPlanFragment结构中由output_exprs字段表示。output_exprs的类型为 TExpr的集合。集合中每个TExpr都是一棵TExprNode树,包含了查询输出一列的表达式信息。例如,select abs(fnv_hash(a)), count(b) from t group by a查询的输出有两列,第一列的TExprNode树的根节点为表达式类型为FUNCTION_CALL(abs(BIGINT)),其孩子节点类型也是 FUNCTION_CALL(fnv_hash(STRING)),叶子节点类型为SLOT_REF。
Output Sink
Output Sink,即数据流输出的目的地。这个目的地要么是下一个查询计划分片(select),要么是一个表(insert select或者 create table as select)。在TPlanFragment结构中的otput_sink字段的类型是TDataSink,TDataSink类型的成员如下:
TDataSinkType::type typeTDataStreamSink stream_sinkTTableSink table_sinkTDataSinkType
根 据数据流输出目的地的不同,date sink有两种类型,一种是DATA_STREAM_SINK,位于data stream sender下游查询计划分片中;一种是TABLE_SINK,位于coordinator下游,是数据查询结果集和待插入的新表之间的媒介。
TDataStreamSink
TDataStreamSink 结构中有两个成员,一个是dest_node_id,即目的节点的id。例如一个select a, count(b) from t group by a的聚合查询,执行计划最底层分片的AggregationNode是一个data stream sender,它的id为1;它所在分片的下游分片中的exchangeNode是一个data stream receiver,它的id为2,那么TDataStreamSink变量总的dest_node_id为2。
TDataStreamSink 的另一个成员是TDataPartition类型的变量output_partition。从名字上来看,很容易让人误以为和是和表分区相关,然而并不 是。TDataPartition结构描述了数据流的分发方式,有四种分发方式,UNPARTITIONED、RANDOM、 HASH_PARTITIONED以及RANGE_PARTITIONED。截止到Impala2.2版本还不支持RANGE PARTITION的方式。那下面我们就对UNPARTITIONED、RANDOM和HASH_PARTITIONED做一下解释。
1. UNPARTITIONED——顾名思义,就是“不分片”,也就是所有数据位于同一个impalad节点。
2. RANDOM——数据并不按照某一列分片,而是随机分布在多个节点上。例如HdfsScanNode的数据分片就是RANDOM的。
3. HASH_PARTITIONED——数据按照某一列分片,不同分片的数据位于不同的impalad节点。
TTableSink
TTableSink结构中的结构相对简单,主要包括目的表id、tableSink类型(HDFS或HBASE)、hdfsTableSink的partition key表达式,以及是否覆盖原有数据(insert overwrite)等信息。
Impalad节点上的数据扫描范围
TQueryExecRequest 结构中的per_node_scan_ranges成员定义了和查询相关的数据扫描范围,类型是map >,为Impalad节点到TScanRangeLocation集合的映射。这个结构主要描述了需要扫描的数据在集群上的分布,包括数据位于哪些 节点、每个节点上数据所在block在文件中的偏移和大小,以及block的备份信息。这个结构的作用也很明显,就是根据 TScanRangeLocations在每个Impalad节点上的数量(这里可以认为TScanRangeLocations的数量就是一个节点上需 要扫描的block数),来决定在在一个ScanNode实例中,会有多少个并发的Scanner。对于text文件来说,每个Scanner负责扫描一 个block;对于parquet文件来说,每个Scanner负责扫描一个文件。TScanRangeLocations的成员如下:
TScanRange scan_range
vector<tscanrangelocation> locations</tscanrangelocation>TScanRange
TScanRange 顾名思义,定义了一个数据分片的扫描范围。这个数据范围对于HDFS来说是一个block,对于HBASE则是一个key range。TScanRange中有两个成员,一个是THdfsFileSplit类型的hdfs_file_split变量,在 THdfsFileSplit这个结构中,定义了一个Scanner所需的block的全部信息,包括block所在的文件名、block在文件中的偏 移、block的大小、block所在的partition id(还记得在描述符表的Table描述符中THdfsTable中定义的partitions成员吗?类型为map,Scanner会从这里找到 partition id对应的partition信息)、文件长度以及采用的压缩算法。另一个TScanRange的成员是THBaseKeyRange类型的 hbase_key_range变量,在THBseKeyRange这个结构中,存储了当前需要扫描的数据分片的起始rowKey和结束rowKey。
TScanRangeLocation
数 据分片(对HDFS来说是block)的replication信息保存在TScanRangeLocations中。众所周知。HDFS的数据默认是3 备份,那么在locations这个集合中就存储了3个TScanRangeLocation,每个TScanRangeLocation都保存了其中一 个备份的相关信息,包括这个replication所在的主机id、数据所在的volumn id以及数据是否被hdfs缓存。
Impala的查询上下文
和用户提交的查询相关的上下文信息保存在TQueryExecRequest的query_ctx成员中,类型为TQueryCtx。TQueryCtx的成员如下:
TClientRequest request
TUniqueId query_id
TSessionState sessionstring now_string
int32_t pid
TNetworkAddress coord_addressvector< ::impala::TTableName> tables_missing_statsbool disable_spilling
TUniqueId parent_query_idxTClientRequest
TClientRequest 结构中保存了客户端提交的SQL语句以及Impala的启动参数,包括计算节点数、scanner一次扫描的batch大小、最大scanner线程数、 最大io缓冲区大小、mem_limit、parquet文件大小,以及是否启用运行时代码生成等信息。
TSessionState
TSessionState结构中保存了客户端连接信息,包括客户端连接的方式(BEESWAX或者HIVESERVER2)、连接的数据库、用户名、以及提交查询所在节点的主机名和端口。
TNetworkAddress
TNetworkAddress结构中保存了coordinator的主机名和端口。
总结
通过对TQueryExecRequest结构的分析,我们不仅能够了解Impala在一个查询的生命周期内收集了哪些有用的信息,更加重要的是,对照这些 信息,能够帮助我们更好的理解Impala的查询执行逻辑,使得对Impala代码的理解更加深刻,在实际的使用场景中,根据不同的查询需求和数据量级, 做出更有针对性的查询优化调整。
以上是关于Impala的信息仓库:解读TQueryExecRequest结构的主要内容,如果未能解决你的问题,请参考以下文章
深度分析 || 消息指嘉能可购Impala Platinum铬业务(大宗e讯独家解读)
基于hadoop生态圈的数据仓库实践 —— OLAP与数据可视化
《英国金属导报》:Henry Bath重启(前)Impala在上海自贸区的保税仓库