Impala高性能探秘之Runtime Filter
Posted 数据管理
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Impala高性能探秘之Runtime Filter相关的知识,希望对你有一定的参考价值。
前言
如果说HDFS的数据访问层各个BigData SQL Engine做的都大同小异的话,那么Runtime Filter(下文简称RF)则是Impala比较独特的"黑科技"了,在深入学习Impala之前对于这个名词比较陌生,但它绝对是Impala性能提升的一大法宝,我们将试图围绕着如下几个问题展开以详细介绍Runtime Filter的细节:
什么是Runtime Filter
Runtime Filter在Impala中有什么作用
Runtime Filter实现原理
什么是Runtime Filter
在日常使用SQL进行查询的时候,一个SQL往往包括如下几个部分:SELECT/JOIN/WHERE/GROUP BY/ORDER BY,这几个常用的算子分别对应着SQL执行计划中的project、join、filter、aggregation和sort。本文我们主要关注join和filter这两种算子,为了回答什么是Runtime Filter,首先看一个例子:
SELECT A.NAME, B.CLASS_NAME FROM PEOPLE A JOIN CLASS B ON A.CLASS_ID = B.ID WHERE A.AGE > 10 AND B.GRADE = 4; A表中保存100000条学生记录,通过AGE > 10可以过滤掉其中的40000,B表中保存1000个班级信息,通过GRADE = 4可以过滤掉900条,JOIN之后产生30000条记录。
从这个SQL的表名和字段名中不难分析出我们想得到什么结果。如果一个比较笨的执行引擎会首先将PEOPLE表和CLASS表从存储引擎中读出来,然后将它们按照CLASS_ID和ID进行比较和JOIN,之后根据JOIN的结果中AGE和GRADE列进行过滤,最后读取NAME列和CLASS_NAME列返回给用户, 这种执行计划完全按照SQL看上去执行的顺序,但是性能往往是最差的,这种引擎我们称之为傻瓜SQL引擎。
比较聪明的执行引擎会把filter和project下推到数据扫描节点,正如我们上文介绍的那样,首先从存储引擎中读取数据,如果存储引擎有提供传入谓词的接口那就最好不过了,例如Kudu和Parquet都具有这样的功能,没有该功能的引擎则根据读上来的数据进行过滤,选取需要的列交给JOIN节点处理,本例中需要从PEOPLE中选取CLASS_ID、NAME、AGE列,从CLASS表中选取CLASS_NAME、ID和GRADE列,JOIN节点再根据CLASS_ID和ID列进行内连接,完成之后输出NAME和CLASS_NAME。此类的映射和谓词下推现在也 是SQL引擎优化的基本手段了,此类引擎可以称之为普通SQL引擎。
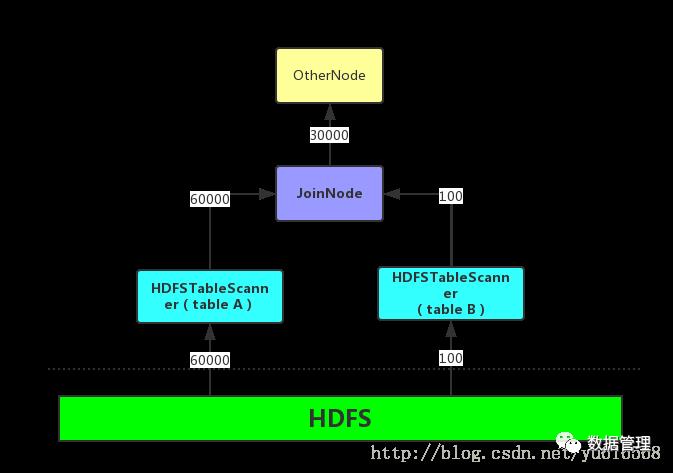
当然,我们还有一种文艺SQL引擎,Impala便是其中一个成员,它使用了Runtime Filter技术在普通SQL引擎的基础上进一步优化,那么优化点在哪里呢?根据字面意思它是一种“运行时过滤条件”,说白了也就是一种过滤条件,但它不是在SQL中写明的,而是在运行时隐式生成的,在介绍它的Where、When、How之前,先看一下Impala中使用RF的一个前提:JOIN中使用的两个表往往是一个大表一个小表,例如通常进行JOIN时候会选取事实表和多个维度表,也诸如星型结构和雪花型结构的查询,因此这个假设在大多数情况下是可以成立的。通常情况下对小表扫描的(HdfsScanNode)执行速度要快于大表(毕竟数据量小很多),这样可以先对小表执行扫描操作,将输出的记录交给JOIN节点,而大表则会主动等待一段时间(默认是1s),JOIN节点会根据小表输出的记录计算出一个过滤条件,这个条件就是RF。
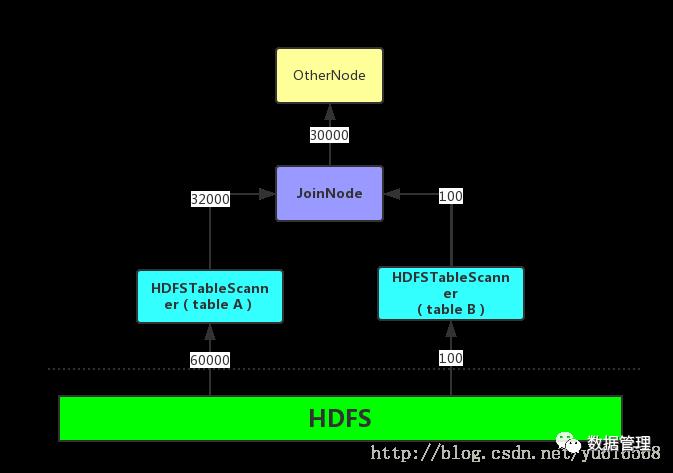
这是一个什么样的过滤条件呢?JOIN节点会依赖于小表返回的每一条记录的等值ON条件中使用的列(上例中的CLASS_ID列)生成一个Bloom Filter信息,如果不熟悉Bloom Filter可以暂时的把它当做是小表中该列的所有值(如上例中则是一个包含所有CLASS_ID的集合),然后将Bloom Filter和大表中的等值ON条件使用的列(ID列)生成一个过滤条件,这个条件就是。因为对于大表只有满足这个条件的记录才有必要输入到JOIN节点进行计算,毕竟如果这些不满足该条件的记录输入到JOIN节点中也会被JOIN规则给过滤掉。
通过上面的介绍,读者应该可以对RF的机制有一定的了解了,总结一下RF的三个W:
Where:RF在JOIN节点上生成,在ScanNode上应用;
When:在有等值ON条件的JOIN操作并且在大表中预过滤不影响查询结果的前提下会生成,例如在LEFT OUTER JOIN则不可以使用RF(假设大表在左边);
How:通过计算小表的JOIN条件中的等值过滤列生成Bloom Filter信息,将这部分信息交给大表完成过滤。
Runtime Filter在Impala中的作用
回答完了第一个问题,下面简要说明一下RF对于Impala有什么作用,当然这也仅仅是笔者在学习和使用过程中的一点点感悟罢了。
谈及RF的作用,要先来聊一下Filter的作用,毕竟它本质上也只是表扫描的一个Filter,大家讨论优化时也总是会说到谓词下推,但是谓词下推一方面意味着读取更少的数据,也意味着输出更少的数据,例如对于Parquet,我们可以通过读取文件的Footer数据判断是否可以skip一个RowGroup,这对于有索引的文件格式和存储引擎(Parquet、ORC、Kudu等),将需要读取的数据量降到了最低,少读数据意味着少一些磁盘I/O,意味着ScanNode可以少处理一些数据,性能自然也就更好了。而输出更少的数据意味着向父节点(可能是JOIN)传递更少的数据,此时数据都已经在内存中了,传递更少的数据意味着更少的内存拷贝,更少的网络通信,因此为此下推的优势是非常明显的。
但是RF是Impala独有的一种Filter格式,目前的文件格式和Kudu存储引擎都不支持直接基于这种过滤规则(这个是可以扩展的,最后再说),因此需要从存储引擎中先读取数据,然后再进行Filter过滤,正如TEXT格式读取那样。总的来看RF的作用和普通Filter还是有一些差别的,毕竟它目前只能减少输出的记录数,而不能直接应用到存储引擎上降低读取的数据量。
Runtime Filter在Impala中的实现
通过前面对于RF的介绍,读者应该对于RF的实现流程有了一个大致的思路,但是Impala的实现并不那么简单,毕竟它是一个分布式执行引擎,如何判断哪些场景需要生成RF,如何生成分布式的RF,如何下发RF到各个节点,大表扫描的时候如果没有等到RF怎么办?这一系列的问题将在本节进行解答,当然,为了更好的解释说明,首先介绍一下Bloom Filter和Impala中的两种JOIN方式。
Bloom Filter算法
Bloom Filter是大数据处理中常用的一种算法,它可以在有限内存的情况下一个成员是否属于一个集合中,类似于Java中Set类中的contains方法,Set结构由于保存了全部成员列表,可以通过哈希表或者排序二叉树查找输入的参数是否存在,但是保存全部的成员将会占据非常大的内存,例如一千万个32字节的成员就会占据320M的内存,这还没有将数据结构本身的内存消耗统计在内,除了占据大量内存之外,直接使用Set还有一些其他问题:插入的时候时间复杂度为O(log N); 序列化和反序列化难度大(这对于需要网络传输是不可避免的)。那么如何解决这些问题呢?当然所有问题都需要在适合的场景下使用,在RF的场景下,这个contains函数不需要做到100%的可靠,结果中可以漏掉一些不满足条件的,但是一定不能排除满足条件的,说白了就是contains应该返回false的判断成了true是可以接受的,但是本应返回true的被判断为false是不可以接受的。Bloom Filter就是实现了这样功能的一种算法,它具有如下特点:
占用固定的内存,输入数据量为N的情况下,可以根据错误率计算出内存占用情况;
插入元素的时间复杂度为O(1);
方便序列化和反序列化,几乎不需要额外的操作;
有一定的错误率,这个错误率就是false被错误地判断为true的概率。幸运的是错误率可以根据内存空间大小、输入数据量等参数通过统计方法计算出来(当然不是绝对的)。
它的原理如下图:
如果简单点理解就是假设位图大小为n,将输入的元素(图中的x,y,z,w)计算出k个哈希值(图中k=3),分别映射到位图中的k位,将这几个位的bit标记为1,这些值就作为这个成员的标识,contains执行判断的时候根据输入按照同样的哈希函数计算出多个哈希值,如果这些位置上的bit都是1则判断它为true,有一个bit部位0则判断它为false。由此也就明白了为什么它只会把false判断为true,毕竟哈希总是会有冲突的。
Impala的JOIN算法
在一文中,详细的介绍了常用的JOIN算法。但是Impala并没有提供这么丰富的JOIN实现,只实现了其中的两种:HASH JOIN和NESTED LOOP JOIN,后者针对于一些比较特殊的场景,例如复杂数据结构的查询和非等值join,本文对此不做探讨(毕竟RF目前只针对等值join的场景),而HASH JOIN的实现又分为两种:SHUFFLE JOIN和BROADCAST JOIN,前者针对大表和大表之间的JOIN,后者针对大表和小表之间的JOIN,JOIN算法的选择不是本文的介绍要点,这里只关心大体上这两种JOIN是如何实现的,SHUFFLE JOIN是通过将两个输入表分别进行SHUFFLE(打散),SHUFFLE的规则通常是基于哈希,相同分区的数据具有相同的哈希结果,这样保证了整个JOIN被分割成多个完全不重叠的任务并行执行,进行JOIN计算之后输出到父节点,但是数据存储并不是按照哈希散列的,因此两个表的每一个扫描节点都需要根据输出记录的哈希值传递到不同的JOIN节点运算。
BROADCAST JOIN主要针对于JOIN的两个表有明显的大小之分(或者说两个表都很小),实现是通过将小表广播的方式进行的,大表的数据扫描不需要网络传输直接交给JOIN节点,小表在扫描的同时将数据传输到每一个JOIN执行的节点以实现数据广播,这样每一个JOIN节点并行的处理整个小表和部分大表的JOIN,输出的结果交给上层节点继续处理。
无论是哪种JOIN算法,在实现过程中全都是基于HashTable实现的,JOIN节点会首先根据小表(在Impala中表现为右表)的输入构建一个HashTable,key是join键,value是记录,这个阶段称之为build阶段,然后对于大表的每一条输入进行probe已生成一条或者多条输出记录,这个阶段称之为probe阶段。
Runtime Filter的执行过程
根据不同JOIN算法的实现,RF也被分为两类:LOCAL和GLOBAL。
这种划分是为了让用户更方便控制使用的RF级别,LOCAL表示生成的RF不需要通过网络传输就可以直接应用,典型的情况时BROADCAST HASH JOIN的时候,JOIN和左表的HDFSTableScan是在一个Fragment中实现的(在一个线程中),由于每一个节点上运行的JOIN都会获取到所有的右表数据,因此都能够build出完整的基于右表数据的RF信息,然后直接将这个信息交给左表的Scan算子,不需要经过任何的网络传输。
GLOBAL是指需要全局的,例如在执行SHUFFLE JOIN的时候,每一个分区都只读取部分数据交给JOIN节点聚合,而每一个JOIN节点都只处理全局数据的一部分,因此也只能生成一个部分RF,它需要将这个局部的RF交给Coordinator节点进行合并,然后再由Coordinator推送到每一个大表Scan节点上,完成RF的分发,整个RF的执行流程如下图所示:
按照图中表出的顺序,一个带有RF优化的JOIN(假设是SHUFFLE JOIN)按照如下的顺序执行:
同时下发两个表的SCAN操作左边是大表,右边是小表(相对而言,也有可能是同等级别的),但是左表会等待一段时间(默认是1s),因此右表的SCAN会先执行;
右表的扫描的结果根据join键哈希传递扫不同的Join节点,由Join节点执行哈希表的构建和RF的构建;
Join节点读取完全部的右表输入之后也完成了RF的构建,它会将RF交给Coordinator节点(如果是Broadcast Join则会直接交给左表的Scan节点);
Coordinator节点将不同的RF进行merge,也就是把Bloom Filter进行merge,merge之后的Bloom Filter就是一个GLOBAL RF,它将这个RF分发给每一个左表Scan;
左表会等待一段时间(默认1s)再开启数据扫描,为了是尽可能的等待RF的到达,但是无论RF什么时候到达,RF都会在到达那一刻之后被应用;
左表使用RF完成扫描之后同样以哈希的方式交给Join节点,由Join节点进行apply操作,以完成整个JOIN过程。
总结
本文详细介绍Impala是如何使用Runtime Filter技术来提升Join的查询性能,当然这一种优化是十分有效的,目前RF只被应用到Parquet文件格式,笔者经过测试可以简单的将其应用到TEXT或者其他文件格式,目前KUDU尚未实现Runtime Flter的支持,但是RF并不是总是有效地,如果JOIN两边的表并不能过滤到很多数据,例如左表和右表中Join键的差集并不大,这种情况下反而浪费了资源计算RF和应用RF。
以上是关于Impala高性能探秘之Runtime Filter的主要内容,如果未能解决你的问题,请参考以下文章