Impala 介绍及部署优化
Posted fanrui
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Impala 介绍及部署优化相关的知识,希望对你有一定的参考价值。
通过本文,你能get 到以下知识:
Impala 架构及各角色的功能
Impala 查询执行流程
Impala 该如何合理地部署
一、 Impala 介绍
Impala 是 Cloudera 公司推出,可以使用 SQL 对 HDFS、HBase 数据进行高性能、低延迟交互式查询。Impala 是分布式的大规模并行计算(MPP)数据库计算引擎。Impala 与 Apache Hive 使用相同的元数据、SQL语法(Hive SQL)、ODBC驱动程序和用户界面(Hue),为批处理或实时查询提供了一个熟悉且统一的平台,Hive用户可以低成本地开销使用 Impala。
Impala 架构
Impala 角色图如下所示:
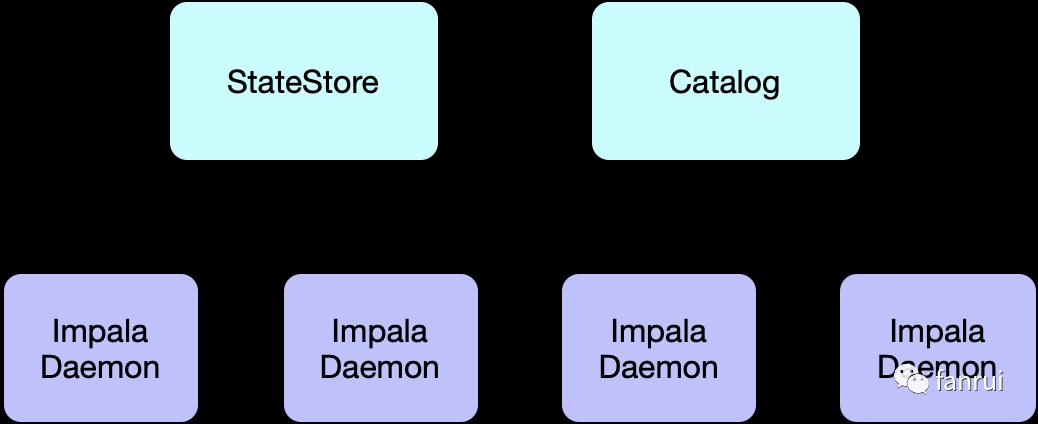
Impala 中包含三种角色,分别是 Impala Daemon、Statestore 和 Catalog Service。Impala集群包含一个 Catalog Server (Catalogd)、一个 Statestore Server (Statestored) 和若干个 Impala Daemon (Impalad)。下面介绍三个角色的功能:
Catalogd 主要负责元数据的获取和 DDL 的执行
Statestored 主要负责消息/元数据的广播
Impalad 主要负责查询的接收和执行
更加详细的功能请参考官网 Components of the Impala Server[1]。
Impalad 内部包含多个组件,如下图所示:
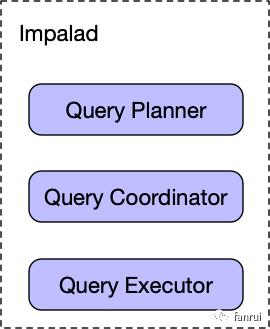
Impalad 中包含 Query Planner、Coordinator 和 Executor。
Query Planner 进行 sql 解析,规划执行计划
Query Coordinator 管理元数据缓存,负责查询的调度、将任务分配给 Executor
Query Executor 负责数据的读取和计算(即:真正干活的角色)
二、Impala 查询执行流程
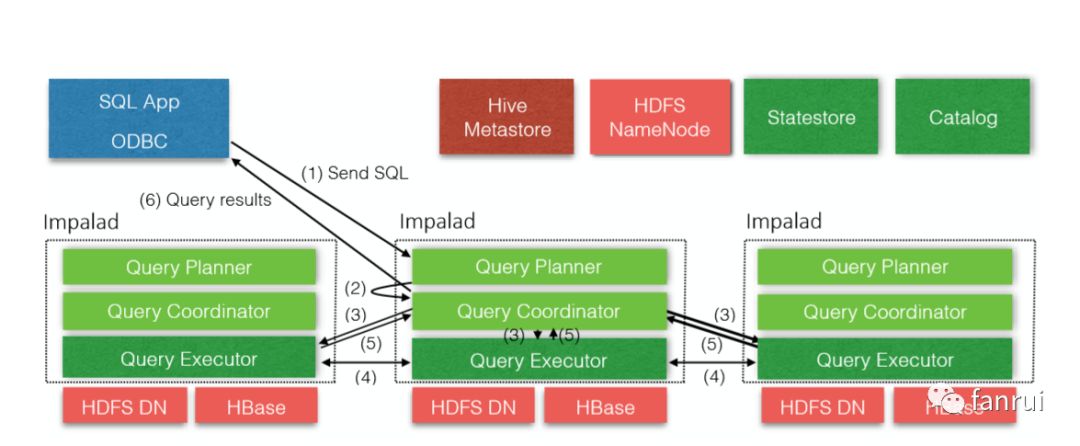
如上图所示是 Impala 的查询执行流程。
客户端发送 SQL 查询请求到任其中一台 Impalad 的Query Planner
由 Query Planner 解析 SQL,规划执行计划,将任务发给 Query Coordinator
由 Query Coordinator 来调度分配任务到相应的 Impalad 节点
各 Impalad 节点的 Query Executor 进行执行 SQL工作
各 Impalad 节点执行SQL结束以后,将结果返回给 Query Coordinator,Coordinator进行结果汇总
Query Coordinator 将结果返回给Client
三、 合理的部署 Impala 各角色
如下图所示,是 Impala 官网的架构图。
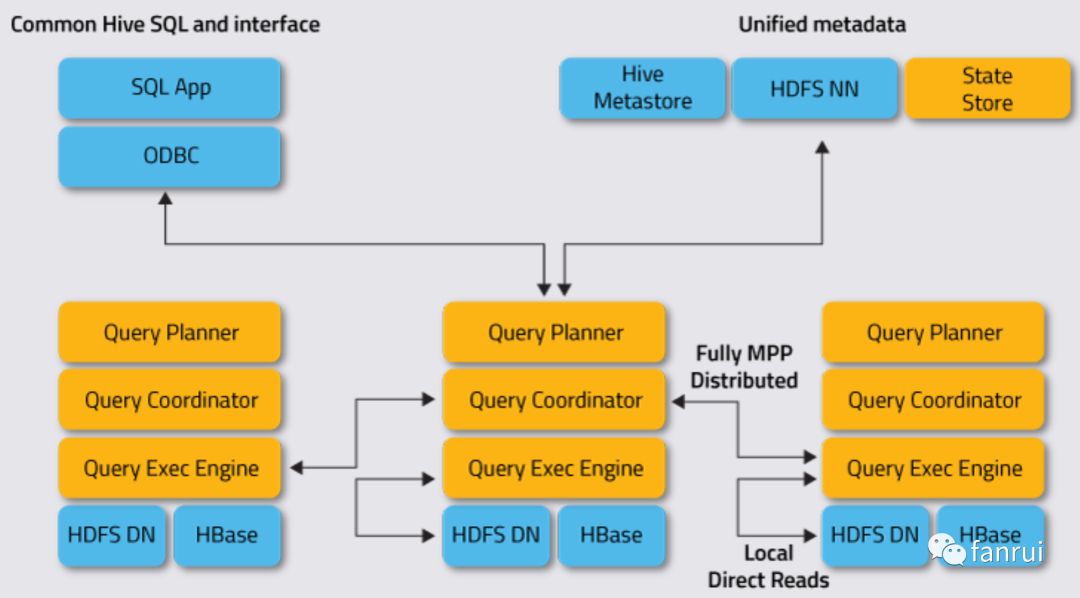
提出几点部署的优化:
Impalad 与 DataNode 混合部署
Impala 常用于统计 HDFS 上的数据,因此强烈建议将 Impalad 和 DataNode 部署到同一台机器。这样可以保证 Impala 任务运行时可以直接从服务器本地读取数据,减少数据的网络传输。
如果 Impalad 与 DataNode 分开部署,那么每次进行统计时,都需要先将数据从 DataNode 拉取到 Impalad,再由 Impalad 的 Executor 进行计算,大数据计算中网络 IO 很容易成为瓶颈。
具体的操作比较简单,这里不赘述。
Impalad 的 Coordinator 与 Executor 独立部署
Impalad 支持的部署模式
Impala 2.9 及以上版本,Impalad 可配置为 Coordinator only、 Executor only 或 Coordinator and Executor(默认)三种模式。默认情况下,每个 Impalad 都包含了 Coordinator 和 Executor。
如果 Impalad 配置为 Coordinator only,说明该 Impalad 仅用于协调,不用于真正的计算
如果 Impalad 配置为 Executor only,说明该 Impalad 仅用于计算,不用于协调
如果 Impalad 配置为 Coordinator and Executor,说明该 Impalad 既用于计算,也用于协调
Coordinator 缓存元数据的问题
Impala 的元数据缓存在catalogd和各个 Coordinator 角色的Impalad中。Catalogd 中的缓存是最新的,各个Coordinator都缓存的是Catalogd内元数据的一个复本。元数据由Catalogd向外部系统获取,并通过 Statestored 传播给各个 Coordinator。
如果集群中所有的 Impalad 都包含 Coordinator 角色,那么每个 Impalad 节点都需要缓存一份元数据,则每个 Coordinator 节点都需要消耗一定的内存空间。Impala 通过 Statestored 将元数据传播给各个 Coordinator,同步元数据就会消耗特别大的网络带宽,Statestored 的网络 IO 可能成为瓶颈。
笔者运维的 Impala 集群包含 200 个 Impalad 节点,且 Impala 中维护的数据表比较多,Impalad 配置为 Coordinator and Executor 模式,发现 Statestored 的网络 IO 能达到 1GB/s 左右,真是太恐怖了。
由于集群中表比较大,元数据比较多,每个 Coordinator 需要占用 20G 左右的内存资源,而且属于 7*24 小时常驻内存。200 个 Impalad 节点,因此 Coordinator 占用了 4T 的内存资源(太可怕了,如果一台服务器100G,相当于 40 台服务器被浪费了)。
集群中应该提供更多的资源给 Executor 去干活,应该部署少量的 Coordinator,少量的 Coordinator 即可满足集群的工作负载。并不需要每个 Impalad 都部署 Coordinator,强烈建议生产环境 Coordinator 与 Executor 独立部署,即:选择一些节点单独部署 Executor,再选择一些节点单独部署 Coordinator。
问题来了,到底分别部署多少个 Executor 和 Coordinator 呢?Impala 官方建议每 50 个 Executor 对应一个 Coordinator。当然这只是一个经验值,具体可以参考角色负载情况进行调整。详细信息请参考 Impala 官网 How to Configure Impala with Dedicated Coordinators[2],该链接详细讲述了为什么要配置专属的 Coordinator,即为什么要独立部署?且讲述了该如何来控制 Executor 和 Coordinator 的比例。
如何配置 Impalad 的模式(实操)
在 Impalad 启动时,指定 is_executor=false 或 is_coordinator=false。Impalad 默认配置为 Coordinator and Executor 模式。
如果想部署独立的 Coordinator Impalad,只需要设置 is_executor=false 关闭 Executor 即可。
如果想部署独立的 Executor Impalad,只需要设置 is_coordinator=false 关闭 Coordinator 即可。
如果使用 Cloudera Manager 部署 Impala,如下图所示强烈建议将 Impalad 节点进行分组,分成 3 组:
默认组表示独立部署 Executor
coordinator 组表示独立部署 Coordinator
coordinator-and-executor 组表示混合部署 Coordinator 和 Executor
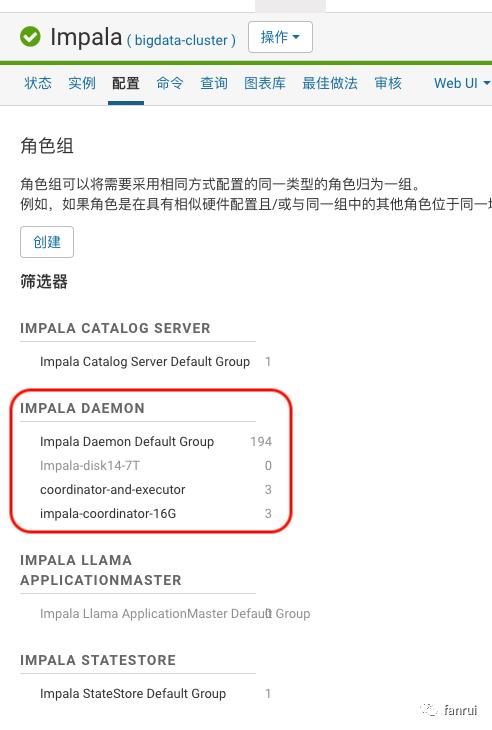
如下图所示,在 Impala 配置页面按照角色组进行配置,默认组关闭 Coordinator,coordinator 组关闭 Executor 即可。
引用:
[1] Impala 官网 -- Components of the Impala Server http://impala.apache.org/docs/build/html/topics/impala_components.html
[2] Impala 官网 -- How to Configure Impala with Dedicated Coordinators https://impala.apache.org/docs/build/html/topics/impala_dedicated_coordinator.html
[3]
以上是关于Impala 介绍及部署优化的主要内容,如果未能解决你的问题,请参考以下文章