Impala,Presto和Hive在MR3上的性能评估
Posted 黄耀的大数据笔记
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Impala,Presto和Hive在MR3上的性能评估相关的知识,希望对你有一定的参考价值。
Impala,Presto和Hive在MR3上的性能评估
2019年3月22日•成宇公园
MR3现在由DataMonad发布。
介绍
在,我们使用TPC-DS基准来比较五个SQL-on-Hadoop系统的性能:Hive-LLAP,Presto,SparkSQL,Hive on Tez和Hive on MR3。由于它在三个不同的群集中同时使用顺序测试和并发测试,因此我们认为性能评估是足够全面的,足以紧密反映Hadoop上SQL的当前状态。我们的主要发现是:
总体而言,基于Hive的系统比Presto和SparkSQL更快,更稳定。尤其是,仍然被认为比Hive快得多的SparkSQL(尤其是在学术界)要快得多,但在竞争中却远远落后。
在顺序测试中,MR3上的Hive与Hive-LLAP一样快。
就并发因子而言,MR3上的Hive在并发测试中表现出最佳性能。
但是,先前的性能评估不完整,因为它缺少SQL-on-Hadoop领域的关键角色– Impala。
随着MR3 0.6的发布,我们使用TPC-DS基准对Impala的主要游乐场Cloudera CDH中的MR3上的Impala和Hive进行了正面对比。由于Impala仅在每个节点上都有足够的内存时才达到最佳性能,因此我们建立了一个新群集,其中每个节点具有256GB内存(比最小建议内存大两倍)。此外,我们在比较中包括了Presto的最新版本。
实验中使用的集群
我们在一个名为Blue的13节点群集中运行该实验,该群集由1个主节点和12个从属节点组成。蓝色集群中的所有计算机都运行Cloudera CDH 5.15.2,并共享以下属性:
2个Intel(R)Xeon(R)E5-2640 v4 @ 2.40GHz
256GB记忆体
1个300GB硬盘,6个1TB固态硬盘
10千兆网络连接
从属节点的内存总量为12 * 256GB = 3072GB。我们使用HDFS复制因子3。
TPC-DS基准的比例因子为10TB。对于Impala,我们在Parquet中生成数据集。对于MR3上的Presto和Hive,我们在ORC中生成数据集。
我们使用的是相同的一组未修改的TPC-DS查询,而不是使用针对各个系统量身定制的TPC-DS查询。对于使用稍微不同的SQL语法的Presto,我们使用另一组查询,这些查询与MR3上的Impala和Hive的查询等效,直到常量级别。
SQL-on-Hadoop系统进行比较
我们比较以下SQL-on-Hadoop系统。
Cloudera CDH 5.15.2中的Impala 2.12.0 + cdh5.15.2 + 0
普雷斯托0.217
MR3 0.6上的Hive 3.1.1
对于Impala,我们使用CDH设置的默认配置,并分配90%的群集资源。
对于Presto,我们将194GB用于JVM -Xmx和以下配置(在性能调整后选择):
query.initial-hash-partitions=12
memory.heap-headroom-per-node=58GB
query.max-total-memory-per-node=120GB
query.max-total-memory=1440GB
query.max-memory-per-node=100GB
query.max-memory=1200GB
sink.max-buffer-size=256MB
task.writer-count=4
node-scheduler.min-candidates=12
node-scheduler.network-topology=flat
optimizer.optimize-metadata-queries=true
join-distribution-type=AUTOMATIC
optimizer.join-reordering-strategy=AUTOMATIC
对于MR3上的Hive,我们将90%的群集资源分配给Yarn。我们使用包含在MR3版本0.6(配置hive5/hive-site.xml,mr3/mr3-site.xml,tez/tez-site.xml下conf/tpcds/)。ContainerWorker使用36GB的内存,每个ContainerWorker中最多可以同时运行三个任务。
顺序测试结果
在顺序测试中,我们提交了来自TPC-DS基准测试的99个查询。如果查询失败,我们将计算失败时间并继续进行下一个查询。我们测量每个查询的运行时间,并计算成功返回答案的查询数。
为了方便读者阅读,我们附上了包含实验原始数据的表格。0秒的运行时间表示查询不会编译(仅在Impala中发生)。负的运行时间(例如-639.367)意味着查询将在639.367秒内失败。这里是[ Google文档 ] 的链接。
结果1.在MR3上的Impala vs Hive
我们总结在MR3上运行Impala和Hive的结果如下:
Impala成功完成了59个查询,但未能编译40个查询。
Hive on MR3成功完成了所有99个查询。
Impala需要7026秒才能执行59个查询。
MR3上的Hive需要12249秒才能执行所有99个查询。
对于MR3上的Impala和Hive成功完成的59个查询集:
Impala需要7026秒,而MR3上的Hive需要6247秒。
在36个查询上,Impala的运行速度比Hive在MR3上快。
在23个查询中,MR3上的Hive比Impala运行得更快。
下图显示了MR3上的Impala和Hive成功完成的59个查询的分布。每个点对应一个查询,其x坐标表示Impala的运行时间,而其y坐标表示Hive在MR3上的运行时间。因此,对角线上方的所有点对应于Impala比MR3上的Hive完成速度更快的那些查询,而对角线下方的所有点对应于MR3上的Hive比Impala完成速度更快的那些查询。
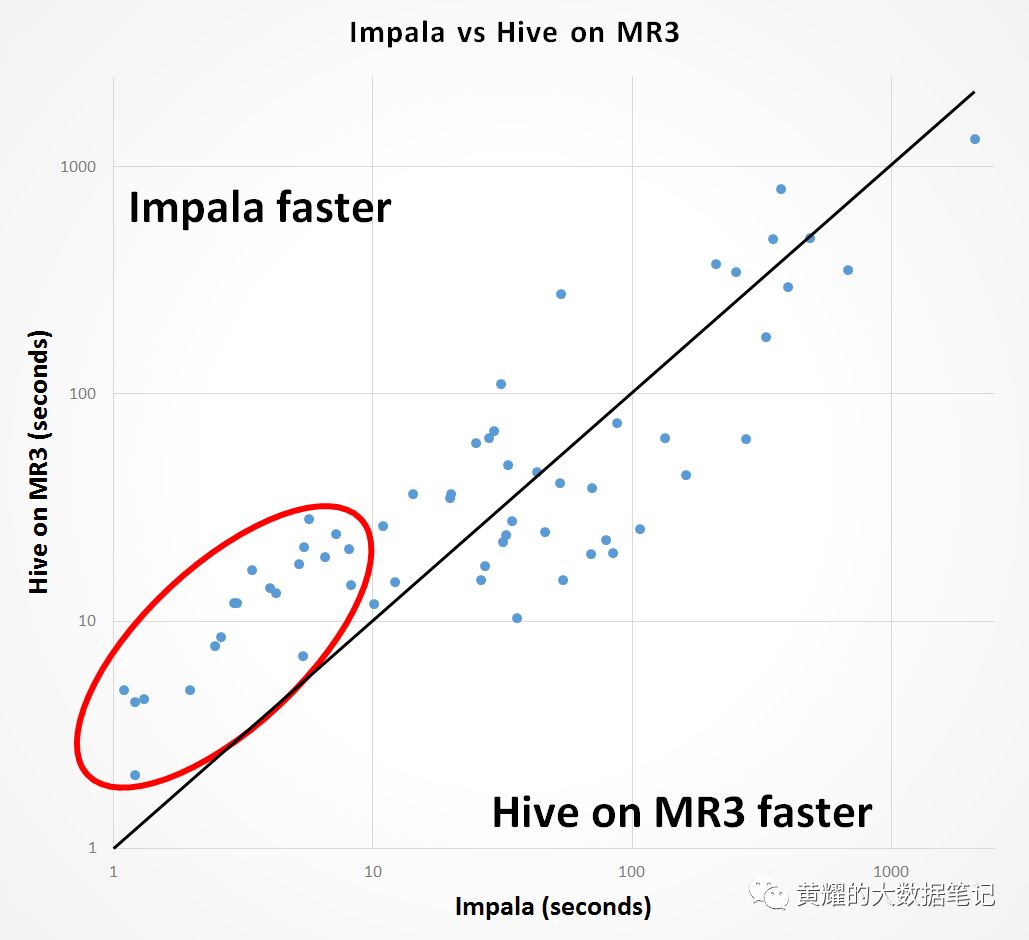
我们发现,在不到10秒的时间内,这20条查询的Impala运行速度始终比Hive在MR3上更快(显示在红色圆圈内)。但是,对于此类查询,在MR3上使用Hive的用户体验在实践中不应大幅改变,因为即使在最坏的情况下,在MR3上使用Hive所花费的时间也不到30秒。对于剩余的39个查询时间超过10秒的时间,MR3上的Hive平均比Impala快15%(Impala的6944.55秒和MR3的Hive 5995.94秒)。
根据实验,我们得出以下结论:
在少于10秒的短时间查询中,Impala的运行速度比Hive在MR3上快。
对于长时间运行的查询,Hive on MR3的运行速度比Impala快。
总体而言,MR3上的Hive比Impala更成熟,因为它可以处理更多范围的查询。
结果2. MR3上的Presto与Hive
我们总结在MR3上运行Presto和Hive的结果如下:
Presto成功完成95个查询,但未能完成4个查询。
Hive on MR3成功完成了所有99个查询。
Presto需要24467秒来执行所有99个查询。
MR3上的Hive需要12249秒才能执行所有99个查询。
对于MR3上的Presto和Hive成功完成的95个查询集:
Presto需要23707秒,而MR3上的Hive需要10489秒。
在14个查询上,Presto的运行速度比Hive在MR3上快。
在MR3上运行Hive比在81个查询上运行Presto快。
与上面的图类似,下图显示了MR3上的Presto和Hive成功完成的95个查询的分布。从许多点到对角线的距离相对较长,这表明MR3上的Hive在其对应的查询上比Presto运行得快得多。我们看到,对于11个查询,MR3上的Hive比Presto快一个数量级。
对于实验,我们得出以下结论:
对于大多数查询,Hive on MR3的运行速度比Presto快,有时要快一个数量级。
总体而言,Hive on MR3和Presto在成熟度上可以媲美。
结论
Impera于2012年10月由Cloudera首次发布为SQL-on-Hadoop系统,而Presto在2012年被Facebook构想为Hive的替代产品。在Hive诞生之时,Hive通常被视为运行的事实标准。SQL在Hadoop上进行查询,但由于使用MapReduce作为执行引擎而使其速度缓慢,因此也臭名昭著。仅仅几年后,Impala和Presto似乎接管了Hive世界(至少在速度方面)。由于其所谓的内存中处理(与基于磁盘的MapReduce处理形成鲜明对比),SparkSQL很快也赶上了潮流。
快进到2019年,我们可以看到Hive在所有方面(速度,稳定性,成熟度)上都是SQL-on-Hadoop领域中最强大的参与者,而它仍然被视为在Hadoop上运行SQL查询的事实标准。。而且,它的Metastore已经发展到几乎每个SQL-on-Hadoop系统都必不可少的地步。毕竟,有充分的理由说明为什么Hive在流行的数据库排名中比Impala,Presto和SparkSQL高得多。
从大数据到云计算,由于技术变革的速度令人眼花speed乱,因此很难准确预测Hive的未来。(谁能想到在2012年,Hive的运行将比Presto快得多,而Presto是为了克服Hive发明公司的速度而发明的。)但是,我们看到Hive在未来几年中无法忽视的不可抗拒的趋势:云计算中对容器和Kubernetes的引力。 实际上,Hive-LLAP在Kubernetes上运行 显然已经在Hortonworks(现在是Cloudera的一部分)中进行开发。就MR3上的Hive而言,它已经在Kubernetes上运行。我们认为MR3上的Hive比Hive-LLAP更适合Kubernetes,因为它的体系结构原理是利用临时容器,而Hive-LLAP的执行围绕持久性守护进程进行。从MR3的下一个版本开始,我们将专注于合并对Kubernetes和云计算特别有用的新功能。
以上是关于Impala,Presto和Hive在MR3上的性能评估的主要内容,如果未能解决你的问题,请参考以下文章