创新工场论文入选ACL 2020,中文分词性能刷新五大数据集
Posted AI报道
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了创新工场论文入选ACL 2020,中文分词性能刷新五大数据集相关的知识,希望对你有一定的参考价值。
创新工场大湾区人工智能研究院的两篇论文在自然语言处理领域(NLP)顶级学术会议 ACL 2020上中选。中选文章阐述了中文分组和词性标注这一底层级别的技术应用迎来崭新突破,将该领域近年来广泛使用的各数据集上的性能全部刷至新高,在工业界也有着非常可观的应用前景。
中文分组向前迈进了一小步
人类自然习得的诸多能力对计算机而言,就像魔法一样神奇,让魔法在计算语言世界成为现实有重重困难。对于我们很容易理解的字,在计算机的世界却有极大的谜团,仍需要人类帮助解开。
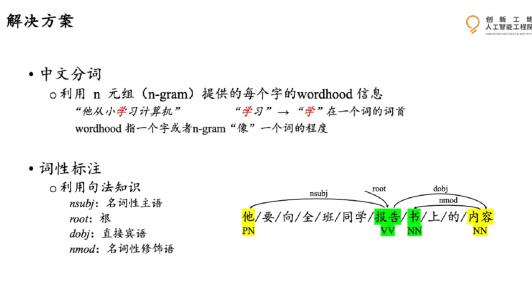
比如:
“部分居民生活水平”,计算机读取的方式会可能是部/分居/民生。
“他从小学电脑技术”,是从/小学,还是从小/学?
“他要向全班同学报告书上的内容”,报告/书上的内容,还是报告书/上的内容?
“他马上功夫很好”,指的是在马背上,还是立即?
从短短几个例句,我们可以感受到中文语言在分词的歧义给中文分组带来的挑战,这意味着,一般的分词工具在切分句子时可能会出错。中文分组的另一大挑战是未登录词问题。未登录词指的是不在词表,或者是模型在训练的过程中没有遇见过的词。例如经济、医疗、科技等科学领域的专业术语或者社交媒体上的新词,或者是人名。这类问题在跨领域分词任务中尤其明显。

中文分词及词性标注是中文自然语言处理的基本任务,尤其是工业界对分词有非常直接的诉求,但当前没有比较好的一体化解决方案。基于此,两篇论文各自提出了“键-值记忆神经网络的中文分词模型”和“基于双通道注意力机制的分词及词性标注模型”,将外部知识(信息)创造性融入分词及词性标注模型,有效剔除了分词“噪音”误导,大幅度提升了分词及词性标注效果。
基于键-值记忆神经网络的中文分词模型:
该模型利用n元组(即一个由连续n个字组成的序列,比如“居民”是一个2元组,“生活水平”是一个4元组)提供的每个字的构词能力,通过加(降)权重实现特定语境下的歧义消解。并通过非监督方法构建词表,实现对特定领域的未标注文本的利用,进而提升对未登录词的识别。
例如,在“部分居民生活水平”这句话中,单字可成词,如“民”;每两个字的组合可能成词,如“居民”;甚至四个字的组合也可能成词,例如“居民生活”。
“民” → 单字词
“居民” → 词尾
“民生”→ 词首
“居民生活” → 词中
根据构词能力,找到所有的成词组合,把这些可能成词的组合全部找到以后,加入到该分词模型中。通过神经网络,学习哪些词对于最后完整表达句意的帮助更大,进而分配不同的权重。像“部分”、“居民”、“生活”、“水平”这些词都会被突出来,但“分居”、“民生”这些词就会被降权处理,从而预测出正确的结果。
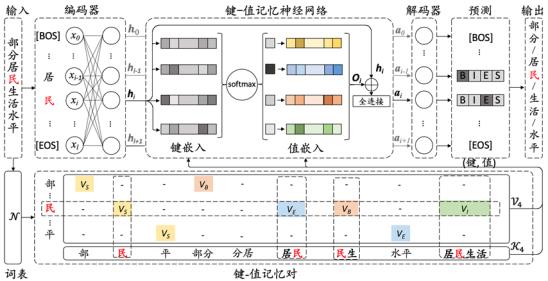
键-值记忆神经网络分词模型
在“他从小学电脑技术” 这句话中,对于有歧义的部分“从小学”(有“从/小学”和“从小/学”两种分法),该模型能够对“从小”和“学”分配更高的权重,而对错误的n元组——“小学”分配较低的权重。
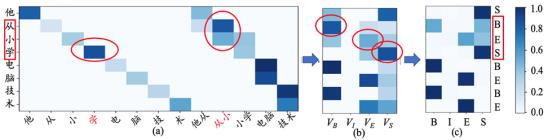
为了检验该模型的分词效果,论文进行了严格的标准实验和跨领域实验。
实验结果显示,该模型在5个数据集(MSR、PKU、AS、CityU、CTB6)上的表现,均达了最好的成绩(F值越高,性能越好)。(注:所选择的五个数据集是中文分词领域目前全世界唯一通用的标准数据集)
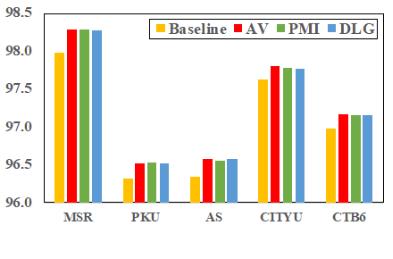
创新工场大湾区人工智能研究院执行院长宋彦表示,与前人的模型进行比较后发现,该模型在所有数据集上的表现均超过了之前的工作,“把中文分词领域广泛使用的标准数据集上的性能全部刷到了新高。”
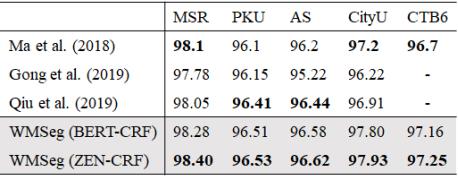
和前人工作的比较
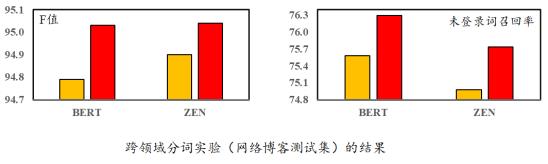
在跨领域实验中,论文使用网络博客数据集(CTB7)测试。实验结果显示,在整体F值以及未登陆词的召回率上都有比较大提升。
基于双通道注意力机制的分词及词性标注模型:
中文分词和词性标注是两个不同的任务。词性标注是在已经切分好的文本中,给每一个词标注其所属的词类,例如动词、名词、代词、形容词。词性标注对后续的句子理解有重要的作用。
句法标注本身需要大量的时间和人力成本。在以往的标注工作中,使用外部自动工具获取句法知识是主流方法。在这种情况下,如果模型不能识别并正确处理带有杂音的句法知识,很可能会被不准确的句法知识误导,做出错误的预测。
例如,在句子“他马上功夫很好”中,“马”和“上”应该分开(正确的标注应为“马_NN/上_NN”)。但按照一般的句法知识,却可能得到不准确的切分及句法关系,如“马上”。

斯坦福大学的自动句法分析工具结果,分成了“马上”
针对这一问题,该论文提出了一个基于双通道注意力机制的分词及词性标注模型。该模型将中文分词和词性标注视作联合任务,可一体化完成。模型分别对自动获取的上下文特征和句法知识加权,预测每个字的分词和词性标签,不同的上下文特征和句法知识在各自所属的注意力通道内进行比较、加权,从而识别特定语境下不同上下文特征和句法知识的贡献。
这样一来,那些不准确的,对模型预测贡献小的上下文特征和句法知识就能被识别出来,并被分配小的权重,从而避免模型被这些有噪音的信息误导。
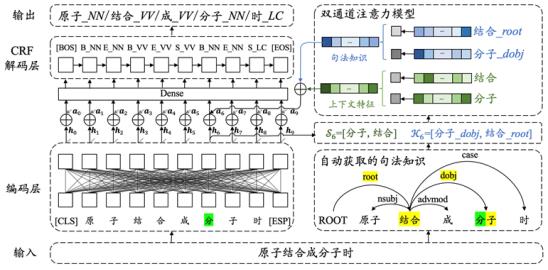
基于“双通道注意力机制”的分词及词性标注
即便在自动获取的句法知识不准确的时候,该模型仍能有效识别并利用这种知识。例如,将前文有歧义、句法知识不准确的句子(“他马上功夫很好”),输入该双通道注意力模型后,便得到了正确的分词和词性标注结果。
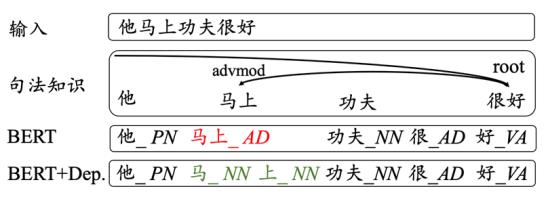
分词及词性标注实例
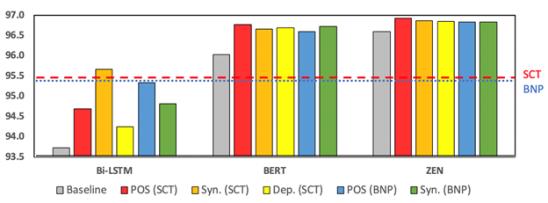
为了测试该模型的性能,论文在一般领域和跨领域分别进行了实验。
一般领域实验结果显示,该模型在5个数据集(CTB5,CTB6,CTB7,CTB9,Universal Dependencies)的表现(F值)均超过前人的工作,也大幅度超过了斯坦福大学的 CoreNLP 工具,和伯克利大学的句法分析器。
即使是在与CTB词性标注规范不同的UD数据集中,该模型依然能吸收不同标注带来的知识,并使用这种知识,得到更好的效果。
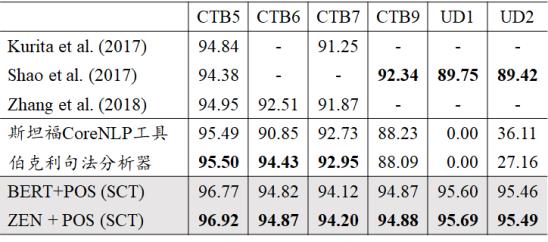
该模型在所有数据集上均超过了之前的工作
CTB5(CTB5是使用最多的中文分词和词性标注的数据集)结果
而在跨领域的实验中,和斯坦福大学的 CoreNLP 工具相比,该模型也有近10个百分点的提升。

跨领域分词实验(对话测试集)的结果
创新工场的这两篇论文沿着近两年学界开始研究的通过加入外部知识和信息来给字加标签的路径,用记忆神经网络的方式记录对分词结果有影响的 n元组,并引入对词性标注有影响的句法知识,将分词结果和自动获得的知识衔接起来,既发挥了神经网络的优势,也把知识的优势用上,实现了分词技术上小而有效的改进和突破。

研究贡献

宋彦表示,从技术创新的角度,我们的贡献主要有两点。
1. 在现有技术的基础上,建立了一个一体化的模型框架,使用非监督方法构建词表,并把知识(信息)融入进来,使用更高层次的句法知识,来帮助词性标注,起到“他山之石,可以攻玉”的效果。
2. 主动吸收和分辨不同的外部知识(信息)。通过键-值记忆神经网络和双通道注意力机制,进行动态权重的分配,能够有效分辨知识,区分哪些是有效的,哪些是无效的。虽然这些知识是自动获取的、不准确的,但“三个臭皮匠,顶个诸葛亮”,经过有效利用,总能凑出一些有用的信息。如何实现模型的主动吸收和分辨,就变得更加重要。
宋彦:不能说分词和词性标注就是自然语言理解
7月8日上午,宋彦针对这两篇入选论文进行了线上的分享解读,有媒体问道:新方法对提升理解的准确性提高了多少,实际应用还可能面临哪些难题?
宋彦表示:自然语言理解其实是一个很大的范畴,我们不能说分词和词性标注就是自然语言理解,因为后续还有很多相关任务一起进行才可能一定程度上进行文本理解。从这个角度出发,我只能说我们的模型提升的性能,仅针对这两个任务本身。因为后续如果有其他任务,即使有好的结果,其他任务本身可能也会带来一些问题,或者说对于有些任务来讲,分词结果的好坏对它们并不是那么敏感。
回到分词这两个任务本身的准确性,我想强调,客观地说,我们在绝对数值上的提升可能没有那么多,但是大家可以看到,因为这两个任务,已经进行了大概超过二十来年的研究,在这样的一个任务上面,实际上这几个标准数据都有了很多年的历史,那么,在这几个标准数据集上面,到今年ACL开会以前为止,实际上有非常非常多的研究人员在这个任务上面已经做了很多工作,他们把这个结果已经提升到一个非常高的程度,而我们在这个非常高的程度之上,再进一步往上提升,其实本身难度是非常大的。
关于应用,中文分词和词性标注是最底层的应用,对于接下来的应用和任务处理非常重要。例如对于文本分类、情感分析,文本摘要、机器翻译等,分词都是不可或缺的基本“元件”。宋彦表示,做此项研究的目的是主要为了拓展其工业场景的应用,正确的分词能够平衡公司应用开发的效率和性能,同时方便人工干预及(预)后处理。
但如果我们要把模型从一个领域应用到另外一个领域去的话,其实领域的这些数据集从哪儿获得,怎么样给数据进行标注,怎么样收集一些最初的标注数据?这可能是一个比较大的难点。同时,怎么样去部署这个模型,在怎么样的生产环境里面使用,在什么场合下面去使用,这可能是在具体业务逻辑单元,需要很多人去针当时的使用情况下进行处理。这也是创新工场人工智能工程院的努力方向之一。
创新工场人工智能工程院成立于2016年9月,宗旨是衔接科技创新和行业赋能,做嫁接科研和产业应用的桥梁,为行业改造业务流程、提升业务效率。工程院下设北京总部、南京研究院和大湾区研究院。大湾区研究院再下设信息感知和理解实验室,专注于对自然语言处理(NLP)领域的研究。执行院长宋彦本人也有超过15年的NLP领域的科研经验。
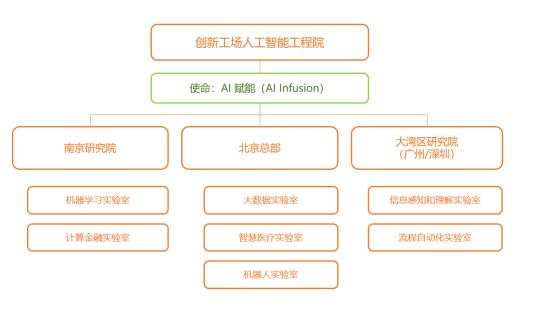
创新工场人工智能工程院架构图
开源福利:
目前,这两篇论文的工具都已经开源,小伙伴请按需自取:
分词工具:https://github.com/SVAIGBA/WMSeg
分词及词性标注工具:https://github.com/SVAIGBA/TwASP
两篇论文也将在北京时间7月9日凌晨1点和5点在ACL会议上进行讲解。
论文作者介绍:华盛顿大学博士研究生、创新工场实习生田元贺、创新工场大湾区人工智能研究院执行院长宋彦、创新工场科研合伙人张潼、创新工场CTO兼人工智能工程院执行院长王咏刚等人。
干货获取方式
以上是关于创新工场论文入选ACL 2020,中文分词性能刷新五大数据集的主要内容,如果未能解决你的问题,请参考以下文章
高精尖中心论文入选国际顶会ACL 2022,进一步拓展长安链隐私计算能力
深度学习下,中文分词是否还有必要?——ACL 2019论文阅读笔记