工程师手记 | 数据科学专题第二篇:Pentaho数据集成(PDI)与数据科学笔记本集成
Posted HitachiVantara
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了工程师手记 | 数据科学专题第二篇:Pentaho数据集成(PDI)与数据科学笔记本集成相关的知识,希望对你有一定的参考价值。
输
高级产品营销经理
1. 同时使用PDI、数据科学笔记本和Python
数据科学家们非常擅长开发分析模型,以获得特定的业务结果。但是,在生产环境中部署模型要求与数据探索和模型开发截然不同的技能组合,因此往往徒费人力。数据科学家花费了大量时间设计数据,而这些数据经常会被您的数据工程师重新编写,以适用于生产部署。
那么,何不让数据科学家和数据工程师各展所长?借助Pentaho PDI的拖放式图形用户界面(GUI),数据工程师可以妥善准备和策划数据,以便无缝进入数据科学家的笔记本,即:Jupyter(这是本博文的重点)。基于Pentaho,数据科学家可以利用Python编程语言和相关机器学习,以及具有净化数据的深入学习框架来探索分析模型。结果如何?这些模型只需极少的成本就可以用于生产环境,并且只需少量时间就可完成交付。
2. 为什么要同时使用PDI和Jupyter Notebook开发Python中的模型?
Pentaho可协助数据科学家将时间投入数据科学模型,而非数据准备,并且能让数据科学家和数据工程师更轻松地共享Python脚本。通过选择Pentaho实施数据科学,各企业机构可达成以下目标:
1) 充分利用图形化拖放式开发环境,通过一个与众多数据源相关联的连接器工具箱,可轻松配置数据工程,避免了重新编码,这些工具能融合来自多个数据源的数据,以及清理和规范数据的转换步骤
2) 仅须极少更改即可将数据迁移至生产环境。
3) 无缝扩展以满足不断增长的生产数据量。
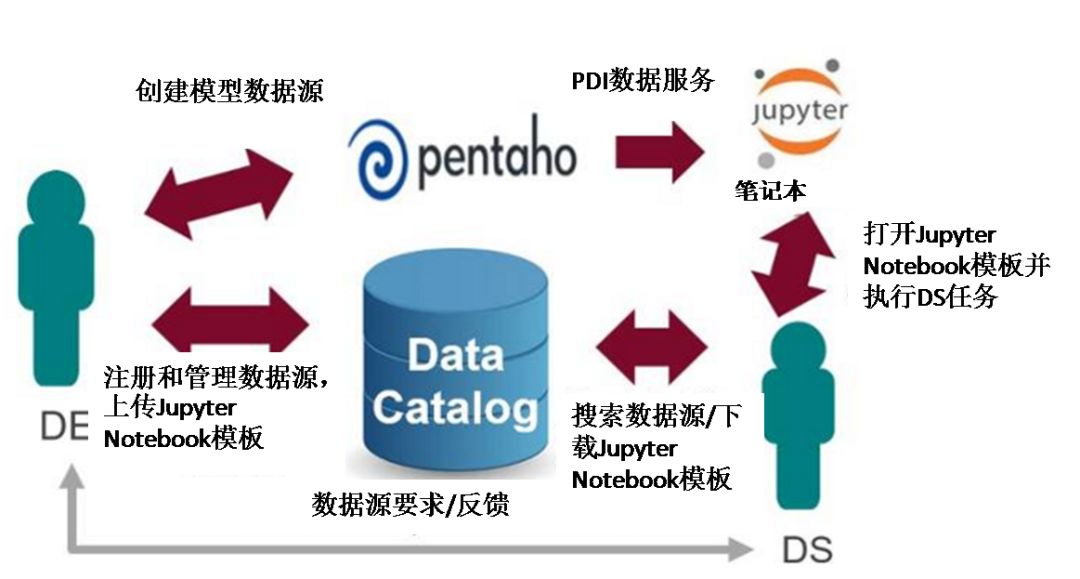
4) 在数据工程师和数据科学家之间共享生产质量数据集和Python脚本,两种角色间的协作工作流如下图所示:
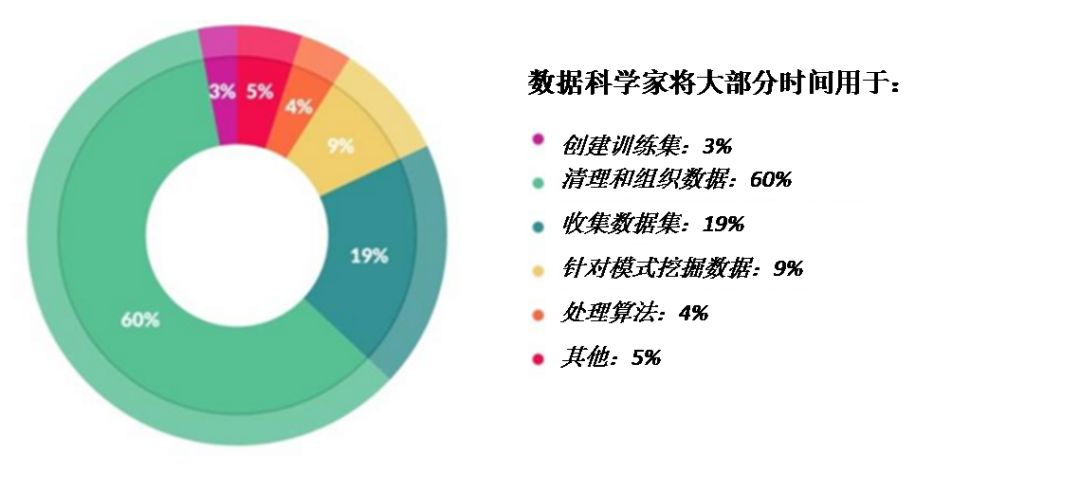
https://whatsthebigdata.com/2016/05/01/data-scientists-spend-most-of-their-time-cleaning-data/
3. 如何使用PDI和Jupyter Notebook开发Python模型?
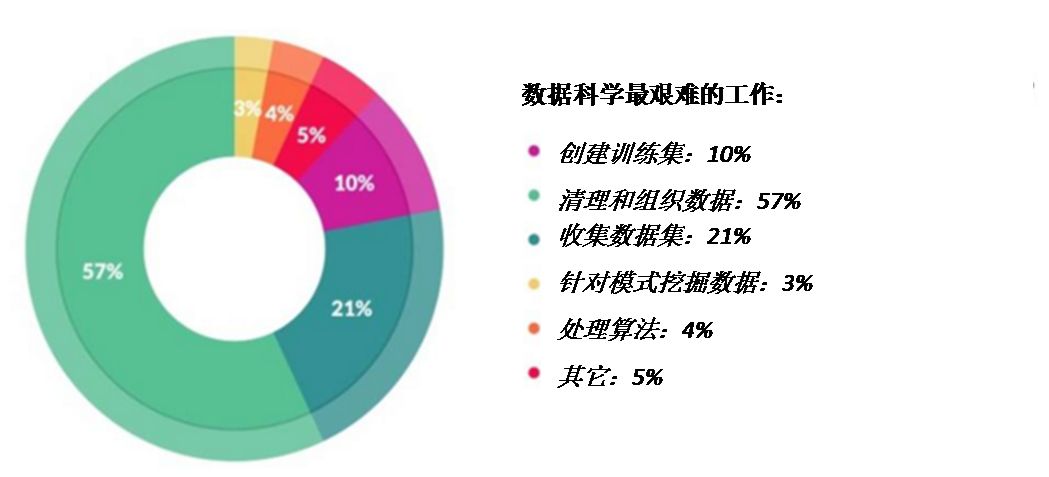
利用下列工具进行测试的依赖项和组件:
适用于8.1/8.2的Pentaho版本
Python.org 2.7.x或Python 3.5.x
Jupyter Notebook 5.6.0
Python JDBC包依赖项,即JayDeBeApi和jpype
Pentaho PDI数据服务在线帮助链接包括相关配置、安装、客户端压缩文件等,详情请访问(或点击阅读原文进入链接):
https://help.pentaho.com/Documentation/8.2/Products/Data_Integration/Data_Services
基本操作步骤
1
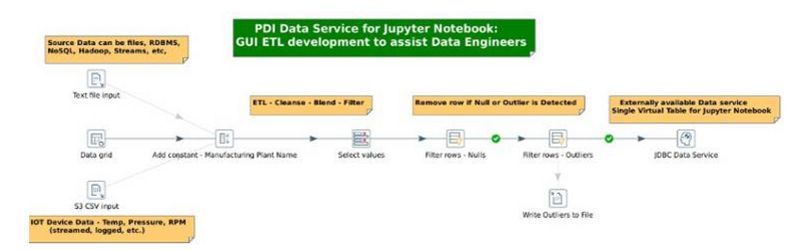
在PDI中,创建一个连接到Pentaho Server(Pentaho服务器)存储库的新转换。实施您的所有数据连接、融合、过滤、清洗等,如下图所示:
2
利用PDI的Data Service(数据服务)功能从PDI转换中导出行(稍后将在Jupyter Notebook中使用)。右键单击转换的最后一步,创建一个 New Data Service(新的数据服务)。在图形用户界面中测试该Data Service(数据服务),并选择将Save Transformation As(另存转换为)将数据服务保存到Pentaho Server(Pentaho服务器)。
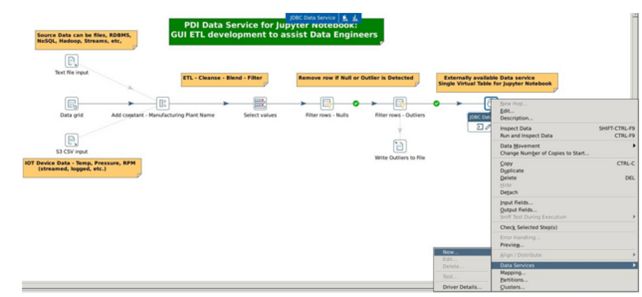
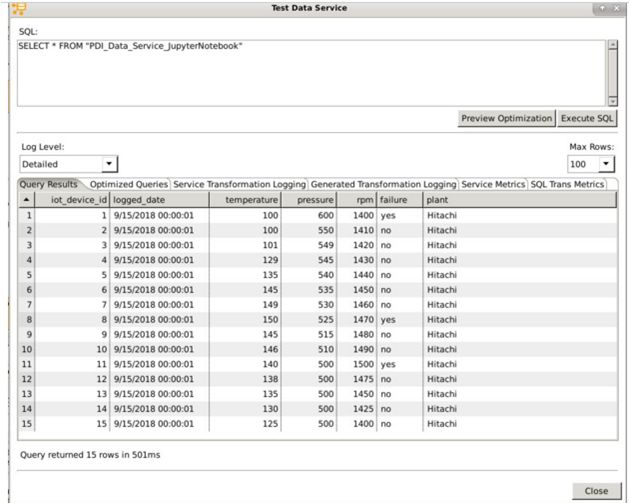
3
在数据科学家能够在Jupyter Notebook中工作之前,利用Data Grid Step(数据网格步骤)检查Data Grid Fields(数据网格字段) 和Data Values(数据值)。这些输入变量将进入Python Executor Step(Python执行器步骤)。注意,对于新的PDI Data Services(PDI数据服务),数据工程师可以轻松地更改这些变量。

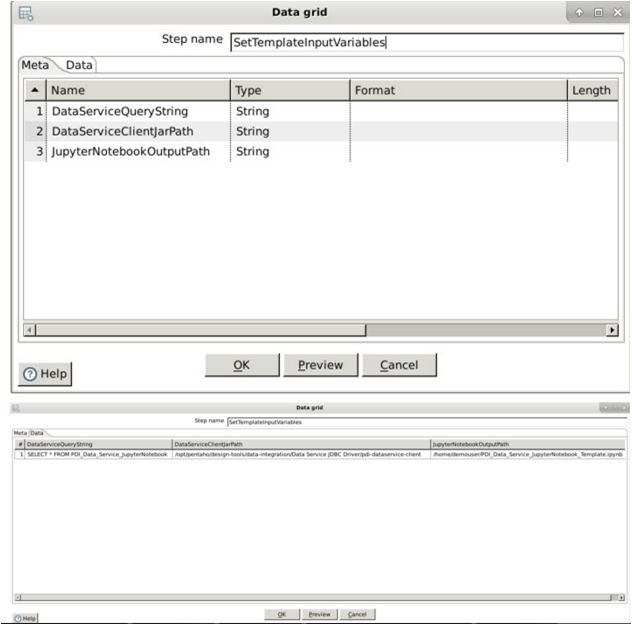
4
Python Executor ——创建Jupyter Notebook——Python API包含 Python Script、Input和Output引用等。数据工程师可借此创建JupyterNotebook,以供数据科学家使用。
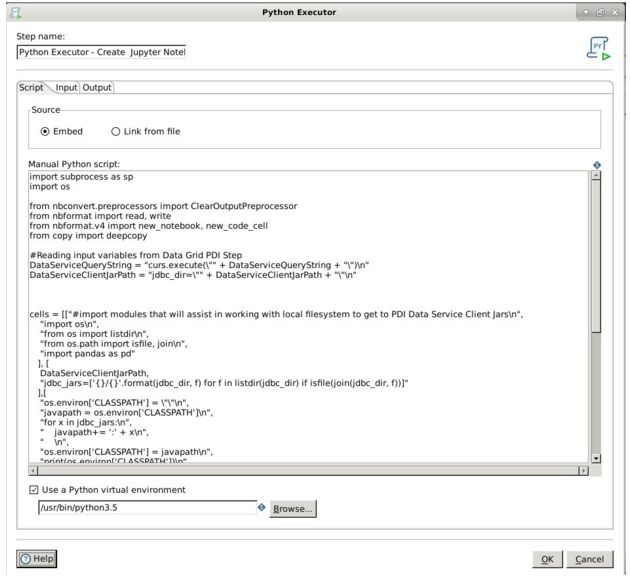
5
Python Executor——创建Jupyter Notebook——Python API步骤将自动使用转换中的净化和编排数据填充Jupyter Notebook(如下图所示)。数据科学家可直接连接到数据工程师先前创建的 PDI Data Service。
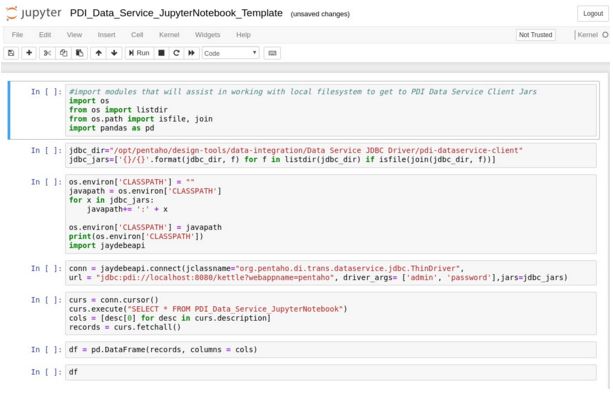
6
数据科学家将检索由数据工程师和PDI创建的Jupyter Notebook文件,即Enterprise Data Catalog(企业数据目录)、File Share(文件共享)等。数据科学家将确认最后一个单元中名为df的Python Pandas Data Frame(PythonPandas数据框架)的输出。
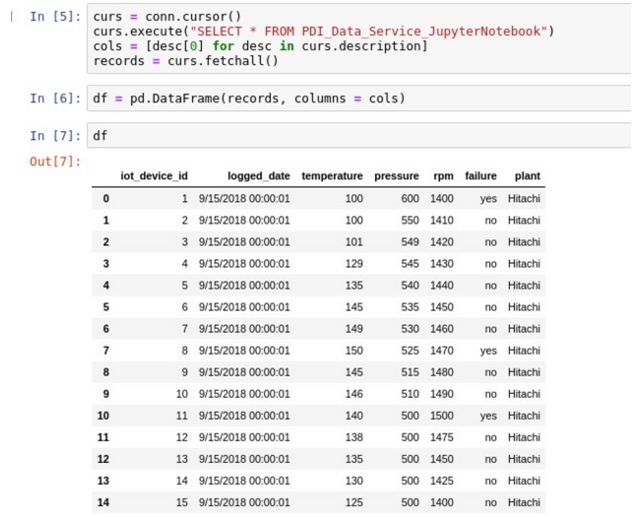
7
在这一步骤中,数据科学家可以利用名为df的Pandas Data Frame(Pandas数据框架)开始构建、评估、处理和保存机器学习和深度学习模型。下面是一个使用Machine Learning Decision Tree Classifier(机器学习决策树分类器)的示例。
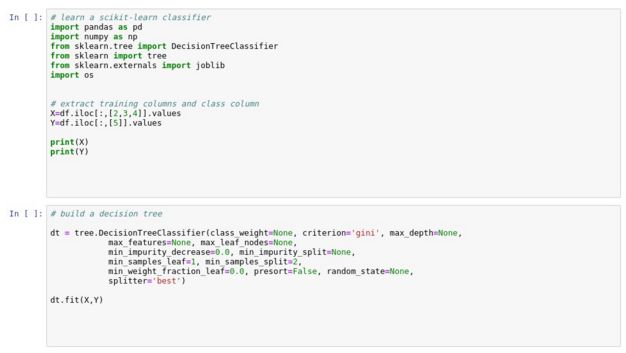
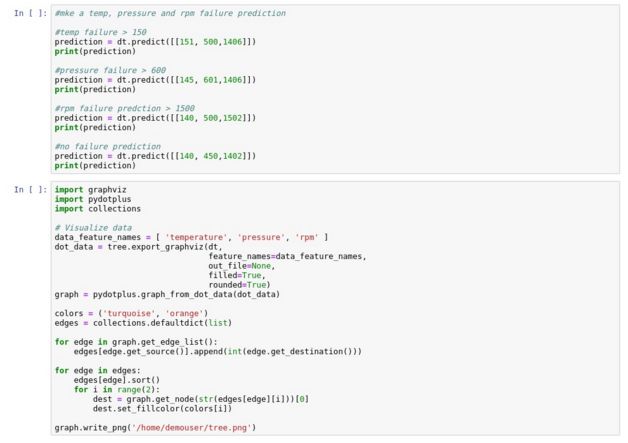
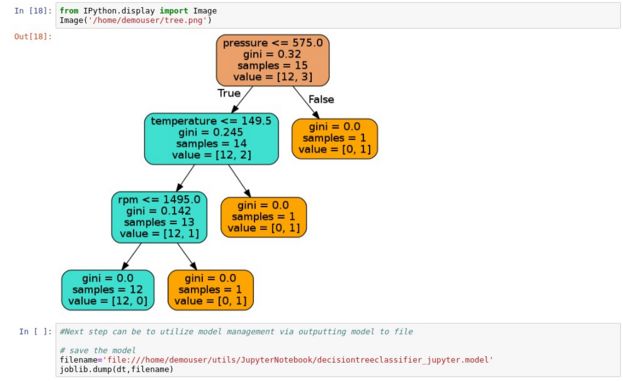
4. 使用Python的数据工程师和数据科学家应如何更好地与PDI和Jupyter Notebooks协作?
1)PDI的图形开发环境使数据工程变得更容易。
2)数据工程师只需进行极少的更改就能将PDI应用程序迁移到生产环境中。
3)数据工程师可以扩展PDI应用程序以满足生产数据量。
4)数据工程师可以通过PDI数据服务快速响应数据科学家的数据集请求。
5)数据科学家可以轻松访问连接到PDI数据服务的Jupyter Notebook模板。
6)数据科学家可以根据需要快速从数据服务中提取数据,并专注于最擅长的领域!

《工程师手记》数据科学专题第三篇
Pentaho数据集成(PDI)与Python和模型管理
敬请期待!
点“阅读原文”进入
Pentaho PDI 数据服务在线帮助
以上是关于工程师手记 | 数据科学专题第二篇:Pentaho数据集成(PDI)与数据科学笔记本集成的主要内容,如果未能解决你的问题,请参考以下文章
asp.net signalR 专题—— 第二篇 对PersistentConnection持久连接的快速讲解