工程师手记 | 玩转Pentaho+R机器学习
Posted HitachiVantara
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了工程师手记 | 玩转Pentaho+R机器学习相关的知识,希望对你有一定的参考价值。
Hitachi Vantara
资深技术顾问

数据时代,我们需要面对的不是没有数据,而是数据太多。父母那一辈谈个恋爱,一个星期的时间往往只够来回一封信,收信时候的欢愉,思念之苦,情人之间的小心思都跃然纸上,慢慢品味细细琢磨。不过到了现在,熟悉各类通讯工具的年轻人若还是这样的处理速度和效率,估计得打一辈子光棍了。

幻想一下,未来人们最重要的能力之一在于对数据处理的速度和效率,从许多方面我们也都能看出这点。社会的进步也体现在对信息处理的效率上面。在文字发明之前,主要有两类人种,智人和尼安德特人,最终智人能打败尼安德特人,不是因为比尼安德特人更强壮,而是智人更具有群体性,他们能做为一个群体分享信息,分享经验,从而更能够有针对性的制定战术和狩猎。

到了文字被发明以后,人类将经验和信息通过载体记录了下来,流传给了后代,人们获取了从信息中提炼出本质和规则的能力,信息传播的效率更高了。但是只有读书人有这个便利,还有很大一部分不认识字的人,他们无法获得更多的知识,直到广播电视的出现,让一辈子面朝黄土背朝天的农民也拥有了获取信息的能力,信息传播的范围更广并且效率更高。美国大萧条时期,罗斯福对全国6000万广播听众发表了第一次“炉边谈话”,影响力堪比现在的“超级明星”,之后每一次社会的飞速发展都离不开信息传播的效率提升,互联网和移动互联网的出现,更是突破了时间和空间的限制,我们可以随时随地的获取信息,互相交流。
人类的进步更是如此,现代人的高效和快节奏体现在了对信息处理的效率上面,一些人在医学上脑容量更大,意味着他们对信息处理的效率上超出常人,这类人比普通人更能够成为科学家,政治家,成功商人。
也许作为普通人的我们不够聪明,没有爱因斯坦这样高效的大脑来处理各类信息,也没有钢铁侠的Jarvis这样的人工智能助手来帮我们搞定一切,但这个世界是开放的,有很多好的工具能够帮到我们,在繁琐的数据世界里帮我们分析数据、处理信息,而Pentaho是其中的佼佼者。
Pentaho是什么呢?
Pentaho是Hitachi Vantara一款优秀的商业数据处理平台,它帮助数据分析人员处理数据、创建报表、建立分析模型、商业规则和BI流程。在Pentaho内部也集成许多优秀的插件来帮助我们完成数据分析任务,今天我们使用的是Pentaho集成的R script executor来建立一个基于线性回归的预测模型,使用的数据集是R语言ggplot2包自带的diamonds数据集,这个数据集中包含了约54000颗钻石的价格和质量的信息。这组数据涵盖了反映钻石质量的四个“C”——克拉重量(carat)、切工(cut)、颜色(color)和净度(clarity),以及五个物理指标——深度(depth)、钻石宽度(table)、x、y、z。
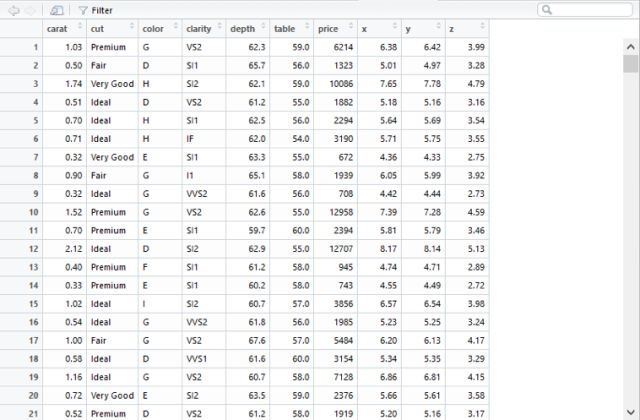
点击图片放大
我们要做的是通过训练数据集来建立一个模型,验证钻石价格的影响因素,并通过测试数据集来验证模型的准确性。
在开始建立分析模型之前我们需要对数据集做一些探索,用于寻找数据变量之间潜在的关系。
1
2
3
4
点击图片放大
数据可视化是了解数据分布、探索数据内在关系必不可少的一环。
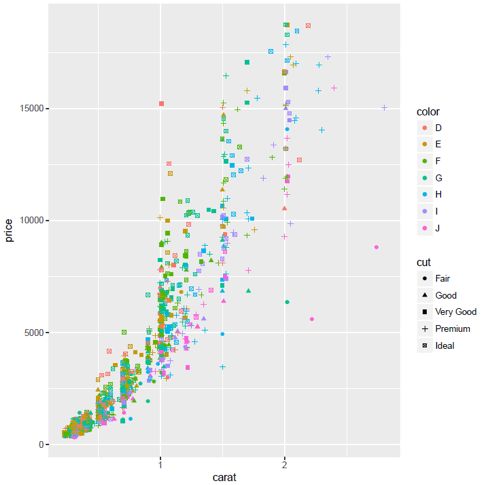
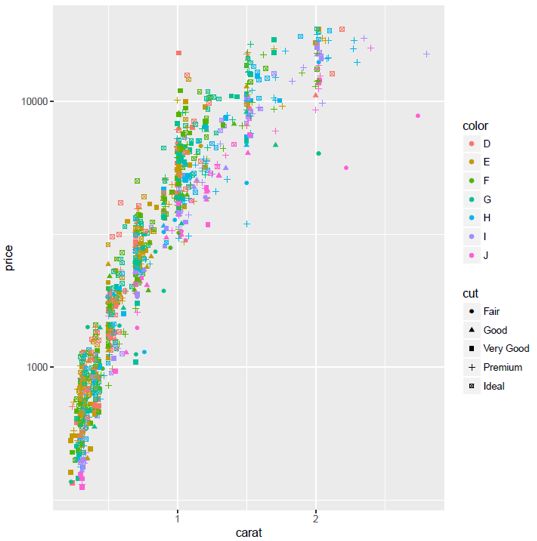
图1我们先根据样本的克拉、价格、颜色和切割四个属性画出样本数据的散点图,观察数据分布似乎存在一定的线性关系,但是越往上走数据分布的越离散。
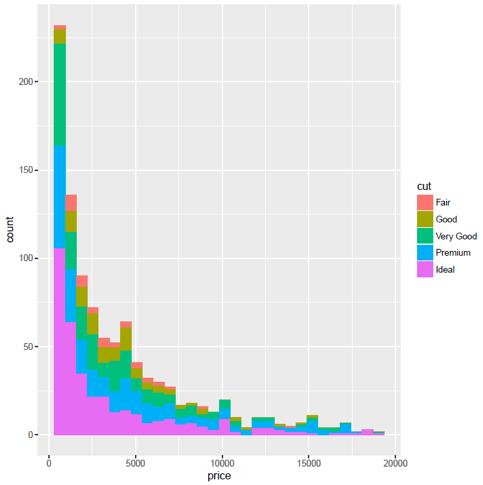
图2直方图显示了钻石的价格和数量的关系,随着价格升高,高品质的切割所占的比率也在逐渐提升。
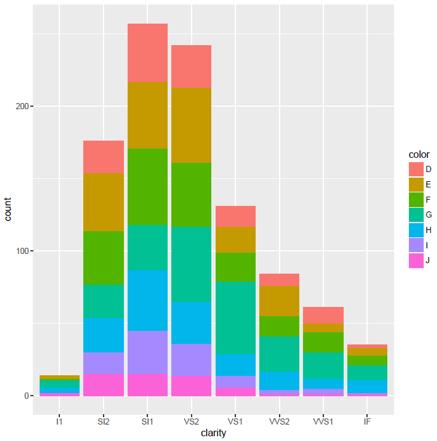
图3纯净度分布图,SI1和VS2纯净度的钻石数量最多,低净度的I1和高净度IF的都比较少,似乎符合一定的正态分布。
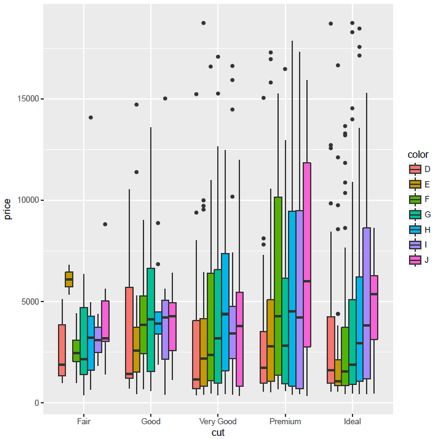
图4根据不同的切割类型画出数据箱线图,其中黑色点是离群点,代表差异较大的样本数据。
当数据分布并没有呈现一定的规律性的时候,我们一般会对它做一些变换,从图1上看,X轴自变量克拉越大,Y轴价格变化越快,我们对价格取对数,把Y轴按比例放大,再画出散点图,这样呈现出一定线性关系。
好了,对样本数据探索差不多了,我们回到Pentaho里试着构建模型吧。
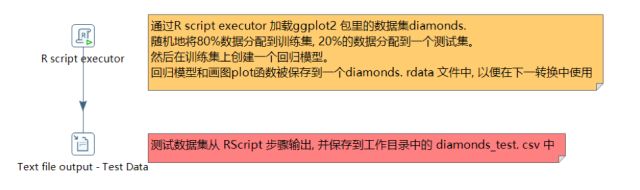
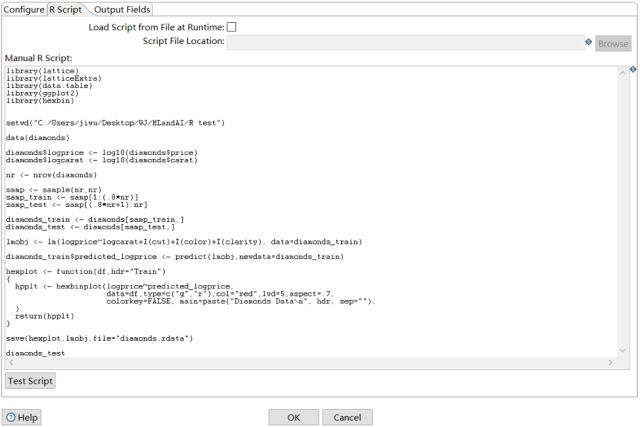
先建立一个新的转换create_model,将样本数据分成训练集和测试集。
点击图片放大
再建立一个test_model的转换,将测试集数据带入模型来分析预测的准确度。

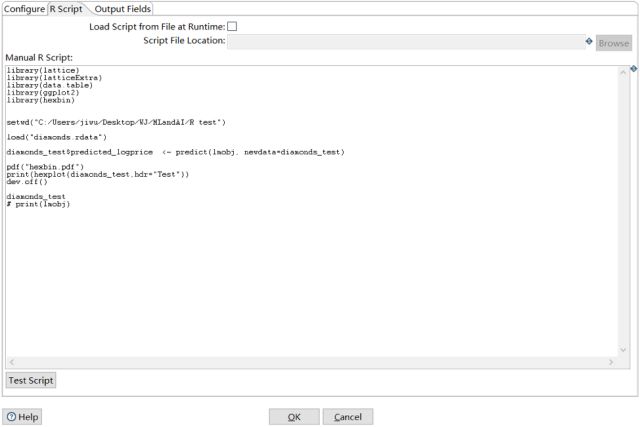
点击图片放大
最后,我们将所有的转换放入一个任务中执行。
执行成功后我们得到了一个线性回归模型,并将它测试后的结果画了出来,其中X轴是预测价格(变换后),Y轴是实际价格(变换后),结论是我们预测出来的价格基本与实际价格相符。
有了这个模型后,就算我们不懂钻石知识也没关系,只要把钻石的参数带入模型里就可以估出钻石的价格区间了,再也不会被奸商骗了。
小伙伴们,你看有了Pentaho后数据分析起来是不是也变的很简单呢?当然Pentaho可不仅仅只有R script executor这一个插件来快速部署分析模型,我们还可以使用Java,Python,Weka等一系列工具呢,还犹豫什么,快来和我们一起玩转数据分析吧,全部示例模型在官网上都能下载哦,你也可以点击阅读原文了解更多。
以上是关于工程师手记 | 玩转Pentaho+R机器学习的主要内容,如果未能解决你的问题,请参考以下文章