大型商业银行基于Hadoop分布式数据仓库建设初探
Posted 星环科技
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了大型商业银行基于Hadoop分布式数据仓库建设初探相关的知识,希望对你有一定的参考价值。
摘 要:商业银行的数据规模随着传统业务扩展和互联网发展水平的不断提高而与日俱增,使得银行对数据的存储、管理和应用要求越来越高。通过搭建基于Hadoop技术的大数据平台,利用分布式文件系统HDFS、SQL分析引擎Inceptor、Nosql数据库工具Hyperbase、流处理工具Stream等架构,探索了大型商业银行Hadoop分布式数据仓库的构建过程,最终实现了由基于集中式存储架构的传统关系型数据仓库向分布式数据仓库的迁移工作。该分布式数据仓库实现了结构化数据和非结构化数据的存储、ETL调度管理、历史数据检索、交互式分析以及流数据处理。应用表match明,相比基于集中式存储架构的传统关系型数据仓库,分布式数据仓库可大幅提高数据存储和数据服务的效率。

引 言
随着银行在业务开展过程中内部数据快速增长以及互联网浪潮下外部数据的采集成本不断降低,传统集中式数据分析平台在数据存储和分析应用上都面临了巨大挑战。如何运用大数据理念及技术,有效整合内外部数据,为银行提供客户分析、精准营销、差异化定价、风险管理等服务,同时做好爆炸式增长数据的存储、管理工作是全行业共同面临的问题。
本文基于Hadoop大数据平台构建了分布式数据仓库,设计了数据采集加工流程、规范以及调度、配置平台,完成了从集中式数据仓库向分布式数据仓库的重点应用迁移和部分新场景的开发工作,大幅提升了数据加工和服务效率。下面,笔者从系统建设背景、应用架构设计、ETL设计、应用成果等方面做重点介绍。
1 传统数据仓库面临的问题
1.1 传统存储技术与大数据快速增长的矛盾
笔者所在银行的传统数据仓库经历了十多年积累,涵盖了较全面的各类业务数据,数据总量增长了近30倍,平均每年增幅接近30%。数据仓库采用了传统关系型数据库,属于集中式存储架构体系,其成本高、扩容困难、故障恢复耗时长等缺陷日益突出,使得在对海量数据进行综合运用时极为困难,无法满足对数据运用的完整性要求。传统数据库还不能有效管理、处理非结构化数据,不能便捷的收集和存储外部数据来源,并与内部数据有效的整合。
1.2 大数据处理缓慢与需求快速响应的矛盾
传统数据库不再适用海量数据的存储,搜索和分析,效率低,业务需求实现周期长。大数据时代快速增长的数据量带来的另外一个问题是,数据处理的时效性要求越来越高。传统数据库的集中式架构决定了其数据处理的能力存在瓶颈,对于TB级数据的处理捉襟见肘。现阶段,各业务单位,特别是一些监管部门的数据需求,不但要求分析查询的时间范围大、处理逻辑复杂,而且往往有比较严格的时间要求,传统数据库已无法满足业务部门的时效性要求。
2 分布式数据仓库架构设计
分布式数据仓库数据平台有效整合现有传统数据分析平台和基于互联网技术的大数据平台,如图1所示,实现数据采集、存储管理、数据管控、数据挖掘分析、实时决策分析等功能。
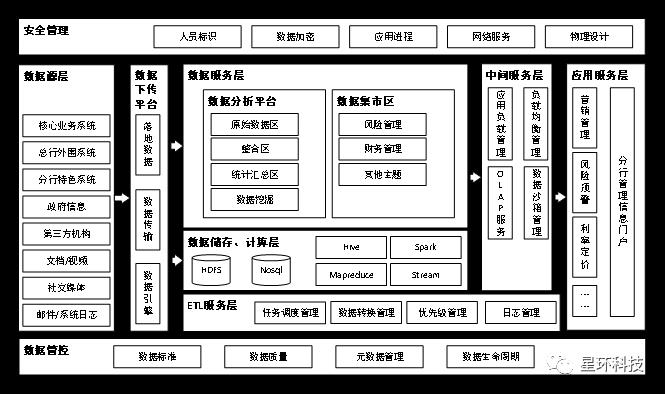
图1分布式数据仓库逻辑架构
2.1 数据源层
从各渠道运用不同方式获取源数据,并进行分析清理,抽取有效数据进行整合处理后供后续分析使用。数据采集支持结构化数据、半结构化和非结构化数据。结构化数据由总行核心系统、外围系统以及分行特色业务系统每天产生的传统业务数据组成,非结构化、半结构化数据由平台系统日志、运营日志、互联网模式下海量文字、音频、视频信息(包括社交网络、法院、人民银行、银联等公开信息)。
2.2 数据储存层
通过构建分布式文件系统(HDFS)以及其上的非关系型数据库,在支持海量异构数据的储存的同时,具备良好的容量扩展能力。针对数据异构集成,一方面,进一步做好银行内部结构化数据的清理梳理,完善和升级各类业务数据要素。另一方面,通过Hadoop大数据技术实现对非结构化和半结构化数据的集成,采用多种组织方式、支持多种类型、多种存储方式的系统结构,实现对大数据量和繁杂数据类型的有效存储,满足大数据的全数据运营需要。
基于Hadoop技术的分布式文件系统(HDFS),突破了集中式数据仓库在容量扩展时影响上层应用运行、扩展能力局限的缺点,在确保集群数据完整性、可靠性的同时,通过直接扩充集群节点的方式,在管控层自动调度下实现文件自动备份、迁移,实现存储容量的线性扩充。
2.3 数据计算层
Hadoop技术的核心计算架构MapReduce利用HDFS分布式存储和自身分布式计算的特点,实现计算单元与文件分块的结合,将计算任务分解并分派至不同计算单元进行运算,再将计算结果聚合,实现更快、吞吐量更大、可线性扩展的数据计算能力,适用于大量数据的离线、批量处理。
Spark技术是基于内存的分布式计算架构,占有更少的硬盘读取资源和网络资源,适合大量数据的实时分析、决策任务。
流处理技术负责实时抓取业务流中产生的数据,计算并挖掘生命周期较短的数据的价值,为部分实时性要求较高的业务场景提供实时决策。
2.4 数据服务层
基于储存层和计算层的海量储存能力和高速计算能力,实现结构化数据、非结构化数据的整合,并通过数据挖掘技术,为客户从不同侧面构建360视图,包括资产负债画像、现金流画像、风险偏好画像、情绪画像等。对于特定业务场景,利用实时决策、机器学习、数据沙箱等技术对源数据进行分析清理,抽取有效信息进行整合、归集,建立对应数据集市,用于支持后续营销、管理和业务场景优化。
2.5 应用发布层
经服务层加工后的拥有较高业务价值的信息,通过多种渠道提供给行内各业务环节,实现多种形式的数据展现,支持各类管理和市场决策需求,包括仪表板、报表/指标、OLAP分析等。同时,为了进一步提高信息自动化的处理水平,在安全可控的情况下将数据直接提供给各类业务系统,实现无需人工干预的自动化的业务决策和处理。
2.6 数据管控层
安全管理上,通过建立统一的数据管控功能,实现数据ETL处理、任务调度管理、元数据管理、数据标准化、数据生命周期管理等数据监控、管理手段,以提升数据质量,便于上层应用分析统计。另一方面,通过建立严格的安全管理手段,从硬件、网络、应用等不同层次实现数据访问的安全可控。
3 ETL架构设计
开发了大数据集成管理平台,如图2所示,提供了包括集成开发环境、代码管理、作业调度、数据ETL等一整套解决方案,降低了大数据开发的技术要求,传统数据库开发人员可以快速转型到大数据平台进行开发。

图2 ETL工具架构
在数据ETL上平台实现了对文本文件的校验、转换以及贴源层、模型层、展现层等多层次数据加工、处理工作,并制定了统一的开发规范和数据规范,保证数据质量。作业调度监控功能对管理平台内发布的任务进行灵活调度配置和监控,支持任务之间的顺序、依赖、互斥等逻辑关系。调度管理精度细化至表级别,实现了每张表的加工状态、执行时间监控,并对异常状态进行报警,保证了每日数据的时效性。此外,管理平台提供了统一的集成开发环境,使用统一的开发界面,实现了大数据开发的代码管理、版本管理和项目发布管理,支持开发、投产、运维工作的分离,满足信息安全工作的要求。
4 表结构设计
在数据从传统数据仓库向分布式数据仓库迁移的过程中,如何选择数据在大数据平台中采用的储存格式和结构是影响后续数据计算性能的关键。因此,需要根据数据的分布特点以及使用场景(逻辑架构如图3所示),结合星环TDH平台各组件的性能特点和优势,设计最合适的储存格式和表结构。
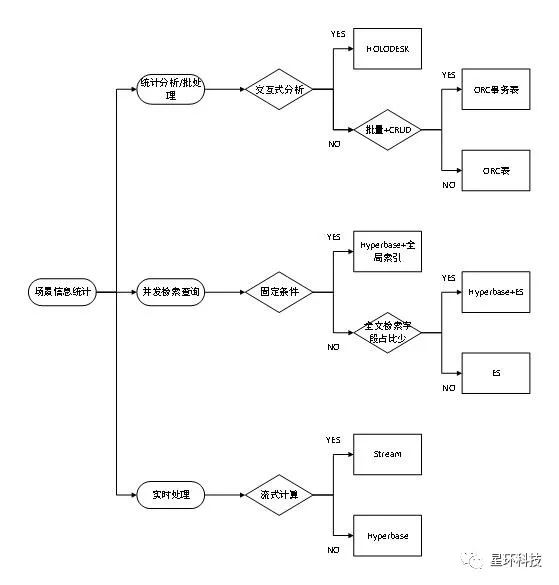
图3大数据平台表结构设计
4.1 统计分析/批处理
数据批处理是数据仓库中最主要的应用场景之一,每日都有大量的业务数据文件以全量或增量形式导入数据仓库,大数据平台需要对这些文件进行批量导入、清洗、加工、展现,并根据不同业务需要进行定制化开发和统计分析。
(1) 贴源层
数据仓库的贴源层以文本表形式储存,文本表具有无压缩、行式储存的特性,实现了对原始文本文件到数据仓库的过渡,同时支持从Sqoop、Flume、Oracle、DB2等不同数据来源获取原始数据。
(2) 模型层
在完成原始数据的文本文件导入数据仓库后,需要对贴源层数据进行批量加工和整合。在此过程中包含大量的Join、Group by操作,同时数据级别经常在100GB以上。ORC表是一种优化的列式存储格式,压缩比高,并支持分区、分桶两种结构优化策略,对大数据量的Join、Group by操作有较大的性能优势,适用于批量数据加工场景。对于有事务性要求的任务,可选用ORC事务表进行储存。ORC事务表在ORC表的基础上满足了事务性要求,支持数据的增、删、改、查以及回滚等操作,满足银行在传统数据仓库中对数据一致性和事务性的需求。
在设计模型层中ORC表的结构时,可根据批处理的SQL语句、表的大小以及主键进行针对性的优化。例如,将常用于Where条件的字段或者日期字段作为ORC表的分区字段,可在批处理和查询操作过程中减少计算引擎对表的扫描文件数,从而大幅提高批处理和查询效率。此外,对于常用的Join字段或者Group by的字段作为分桶字段,可优化分布式计算引擎的执行计划,更均衡地分配计算任务,提高计算效率。
(3) 交互式分析
数据的即席交互式分析和报表实时展现是银行数据的重要使用场景之一,查询统计性能要求较高,且包含多表的Join、Group by操作以及任意字段的灵活组合查询,因此ORC表无法满足要求。Holodesk表是基于SSD和内存的分布式列式存储结构,对group by和多表间的join操作进行了针对性优化,复杂查询请求的返回时间可控制在秒级别,可满足数据交互式分析和自由查询的性能要求。
4.2 并发检索查询
Hyperbase是基于HBase优化的Nosql数据库,适用于非结构化数据的存储和固定条件的历史数据检索;Elastic Search支持对历史数据进行全文检索、关键字检索、范围检索等复杂条件的查询;对于既有固定条件,又包含部分关键字检索需求的使用场景,则通过将历史数据储存于Hyperbase,并在Elastic Search中建立全文索引字段实现。
4.3 实时处理
对于流式数据的实时处理场景,数据以Stream表的格式储存,实现从Kafka、Socket、Stream等不同数据源采集数据,并支持通过SQL对流数据进行简单的逻辑处理和计算,降低了流计算应用的开发成本。对于实时数据服务,基于面向数据服务的架构(DSOA),通过标准数据服务实时采集数据,储存于Hyperbase中,常用于采集外部非结构化数据场景。
5 分布式数据仓库应用成果
目前基于大数据平台的分布式数据仓库已全面上线,负责全辖每日业务数据的批处理加工和实时展现,并提供统一数据管理和大数据应用服务。如图4所示,纵坐标为数据服务耗时的时间取对数。在数据批处理效率上,相比传统数据仓库每日耗时8小时以上,基于大数据平台的批处理耗时达到1小时以内;历史数据检索服务实现海量历史数据的高速查询、搜索,单个业务自主查询速度从原有的半小时提升至秒级别,大幅提高各类渠道数据请求的响应效率;在交互式分析上,基于Holodesk提供客户360视图的实时自由查询服务。客户画像宽表包含500个字段,文件大小约50GB,任意字段组合查询结果返回从20分钟提升到10秒以内,大幅提高自由查询功能模块使用体验。
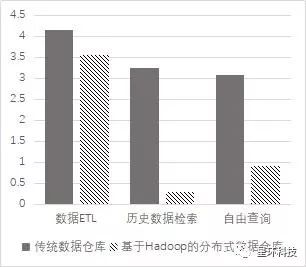
图4分布式数据仓库效率提升对比
6 结 语
本文通过搭建基于Hadoop技术的分布式数据仓库,充分整合了银行数据资源,在信息化建设过程中积累的海量业务数据基础上,扩充了数据采集的范围,积极纳入行外非结构化数据,同时延长了数据保存周期。此外,根据不同的数据应用场景,使用不同的Hadoop技术并进行针对性的优化,从而大幅提高了在数据批处理、历史数据检索和交互式分析等数据使用场景上的服务效率。基于Hadoop技术的分布式数据仓库有效弥补了基于集中式存储架构的传统数据仓库在面对数据快速增长和快速响应分析的挑战时遇到的性能瓶颈,并为业务分析人员提供了更高时效性的数据资源和更强的数据分析能力。进一步发挥分布式数据仓库的存储和性能优势,利用机器学习技术对清洗、整合后的数据进行深层分析、挖掘,更充分地发挥数据资产的价值,是下一步的主要研究、探索方向。
发表于:《计算机应用与软件》 2017.34(8)
点击或回复关键词,查看相关内容
公司
产品
技术
TED视频 | TEDxLujiazui精彩视频:【大数据 大趋势】
白话大数据 | 白话大数据合集
案例
视频监控 | Hadoop大数据在实时视频监控的应用场景
能源 | 厉害了,我的营销大数据!
速记
以上是关于大型商业银行基于Hadoop分布式数据仓库建设初探的主要内容,如果未能解决你的问题,请参考以下文章