数据仓库的基本架构及架构图介绍
Posted 单片机及C语言学习
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了数据仓库的基本架构及架构图介绍相关的知识,希望对你有一定的参考价值。
数据仓库简介
数据仓库,英文名称为DataWarehouse,可简写为DW或DWH。数据仓库,是为企业所有级别的决策制定过程,提供所有类型数据支持的战略集合。它是单个数据存储,出于分析性报告和决策支持目的而创建。为需要业务智能的企业,提供指导业务流程改进、监视时间、成本、质量以及控制。
数据仓库的用途
1.整合公司所有业务数据,建立统一的数据中心
2.产生业务报表,用于作出决策
3.为网站运营提供运营上的数据支持
4.可以作为各个业务的数据源,形成业务数据互相反馈的良性循环
5.分析用户行为数据,通过数据挖掘来降低投入成本,提高投入效果
6.开发数据产品,直接或间接地为公司盈利
数据仓库分层的原因
1通过数据预处理提高效率,因为预处理,所以会存在冗余数据
2如果不分层而业务系统的业务规则发生变化,就会影响整个数据清洗过程,工作量巨大
3通过分层管理来实现分步完成工作,这样每一层的处理逻辑就简单了
标准的数据仓库分层:ods(临时存储层),pdw(数据仓库层),mid(数据集市层),app(应用层)
ods:历史存储层,它和源系统数据是同构的,而且这一层数据粒度是最细的,这层的表分为两种,一种是存储当前需要加载的数据,一种是用于存储处理完后的数据。
pdw:数据仓库层,它的数据是干净的数据,是一致的准确的,也就是清洗后的数据,它的数据一般都遵循数据库第三范式,数据粒度和ods的粒度相同,它会保存bi系统中所有历史数据
mid:数据集市层,它是面向主题组织数据的,通常是星状和雪花状数据,从数据粒度将,它是轻度汇总级别的数据,已经不存在明细的数据了,从广度来说,它包含了所有业务数量。从分析角度讲,大概就是近几年
app:应用层,数据粒度高度汇总,倒不一定涵盖所有业务数据,只是mid层数据的一个子集。
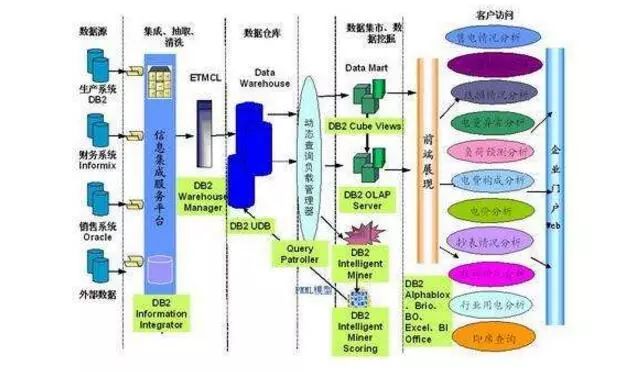
数据仓库的架构图介绍
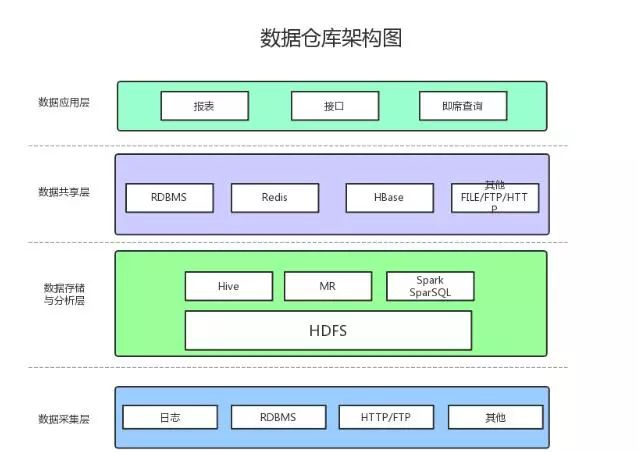
1、数据采集
数据采集层的任务就是把数据从各种数据源中采集和存储到数据存储上,期间有可能会做一些ETL操作。
数据源种类可以有多种:
日志:所占份额最大,存储在备份服务器上
业务数据库:如mysql、Oracle
来自HTTP/FTP的数据:合作伙伴提供的接口
其他数据源:如Excel等需要手工录入的数据
2、数据存储与分析
HDFS是大数据环境下数据仓库/数据平台最完美的数据存储解决方案。
离线数据分析与计算,也就是对实时性要求不高的部分,Hive是不错的选择。
使用Hadoop框架自然而然也提供了MapReduce接口,如果真的很乐意开发Java,或者对SQL不熟,那么也可以使用MapReduce来做分析与计算。
Spark性能比MapReduce好很多,同时使用SparkSQL操作Hive。
3、数据共享
前面使用Hive、MR、Spark、SparkSQL分析和计算的结果,还是在HDFS上,但大多业务和应用不可能直接从HDFS上获取数据,那么就需要一个数据共享的地方,使得各业务和产品能方便的获取数据。
这里的数据共享,其实指的是前面数据分析与计算后的结果存放的地方,其实就是关系型数据库和NOSQL数据库。
4、数据应用
报表:报表所使用的数据,一般也是已经统计汇总好的,存放于数据共享层。
接口:接口的数据都是直接查询数据共享层即可得到。
即席查询:即席查询通常是现有的报表和数据共享层的数据并不能满足需求,需要从数据存储层直接查询。一般都是通过直接操作SQL得到。
理想的数据仓库架构
增加了以下内容:
数据采集:采用Flume收集日志,采用Sqoop将RDBMS以及NoSQL中的数据同步到HDFS上
消息系统:可以加入Kafka防止数据丢失
实时计算:实时计算使用SparkStreaming消费Kafka中收集的日志数据,实时计算结果大多保存在Redis中
机器学习:使用了SparkMLlib提供的机器学习算法
多维分析OLAP:使用Kylin作为OLAP引擎
数据可视化:提供可视化前端页面,方便运营等非开发人员直接查询
文章来自:电子发烧友 网络整理
以上是关于数据仓库的基本架构及架构图介绍的主要内容,如果未能解决你的问题,请参考以下文章