大数据数仓项目架构
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了大数据数仓项目架构相关的知识,希望对你有一定的参考价值。
参考技术A云上数据仓库解决方案: https://www.aliyun.com/solution/datavexpo/datawarehouse
离线数仓架构
离线数仓特点
基于Serverless的云上数据仓库解决方案
架构特点
实时数仓架构
[图片上传失败...(image-ec3d9a-1629814266849)]
实时数仓架构特点
秒级延迟,实时构建数据仓库,架构简单,传统数仓平滑升级
架构特点
数据仓库的输入数据源和输出系统分别是什么?
输入系统:埋点产生的用户行为数据、JavaEE后台产生的业务数据、个别公司有爬虫数据。
输出系统:报表系统、用户画像系统、推荐系统
1)Apache:运维麻烦,组件间兼容性需要自己调研。(一般大厂使用,技术实力雄厚,有专业的运维人员)
2)CDH:国内使用最多的版本,但 CM不开源,但其实对中、小公司使用来说没有影响(建议使用)10000美金一个节点 CDP
3)HDP:开源,可以进行二次开发,但是没有CDH稳定,国内使用较少
服务器使用物理机还是云主机?
1)机器成本考虑:
(1)物理机:以128G内存,20核物理CPU,40线程,8THDD和2TSSD硬盘,单台报价4W出头,惠普品牌。一般物理机寿命5年左右。
(2)云主机,以阿里云为例,差不多相同配置,每年5W
2)运维成本考虑:
(1)物理机:需要有专业的运维人员(1万*13个月)、电费(商业用户)、安装空调
(2)云主机:很多运维工作都由阿里云已经完成,运维相对较轻松
3)企业选择
(1)金融有钱公司和阿里没有直接冲突的公司选择阿里云(上海)
(2)中小公司、为了融资上市,选择阿里云,拉倒融资后买物理机。
(3)有长期打算,资金比较足,选择物理机。
根据数据规模大家集群
属于 研发部 /技术部/数据部,我们属于 大数据组 ,其他还有后端项目组,前端组、测试组、UI组等。其他的还有产品部、运营部、人事部、财务部、行政部等。
大数据开发工程师=>大数据组组长=》项目经理=>部门经理=》技术总监
职级就分初级,中级,高级。晋升规则不一定,看公司效益和职位空缺。
京东:T1、T2应届生;T3 14k左右 T4 18K左右 T5 24k-28k左右
阿里:p5、p6、p7、p8
小型公司(3人左右):组长1人,剩余组员无明确分工,并且可能兼顾javaEE和前端。
中小型公司(3~6人左右):组长1人,离线2人左右,实时1人左右(离线一般多于实时),组长兼顾和javaEE、前端。
中型公司(5 10人左右):组长1人,离线3 5人左右(离线处理、数仓),实时2人左右,组长和技术大牛兼顾和javaEE、前端。
中大型公司(10 20人左右):组长1人,离线5 10人(离线处理、数仓),实时5人左右,JavaEE1人左右(负责对接JavaEE业务),前端1人(有或者没有人单独负责前端)。(发展比较良好的中大型公司可能大数据部门已经细化拆分,分成多个大数据组,分别负责不同业务)
上面只是参考配置,因为公司之间差异很大,例如ofo大数据部门只有5个人左右,因此根据所选公司规模确定一个合理范围,在面试前必须将这个人员配置考虑清楚,回答时要非常确定。
IOS多少人 安卓多少人 前端多少人 JavaEE多少人 测试多少人
(IOS、安卓) 1-2个人 前端1-3个人; JavaEE一般是大数据的1-1.5倍,测试:有的有,有的没有。1个左右。 产品经理1个、产品助理1-2个,运营1-3个
公司划分:
0-50 小公司
50-500 中等
500-1000 大公司
1000以上 大厂 领军的存在
转自: https://blog.csdn.net/msjhw_com/article/details/116003357
Flink实时数仓项目—项目初了解
Flink实时数仓项目—项目初了解
前言
学习完了Flink1.13,拿个项目练练手。
一、实时数仓分层介绍
1.普通的实时计算与实时数仓比较
普通的实时计算和实时数仓有什么区别?或者说实时数仓为什么要分层?
普通的实时计算首先考虑的是时效性,所以是直接从数据源采集数据,然后直接计算得到结果,这样做时效性更好,但是它有一定的弊端,它的中间计算的结果没有沉淀下来。在需求不断增加的时候,部分重复的计算不能够进行复用,导致开发成本直线上升。

实时数仓是基于一定的数据仓库理念,对数据处理流程进行规划、分层,目的是提高数据的复用性。
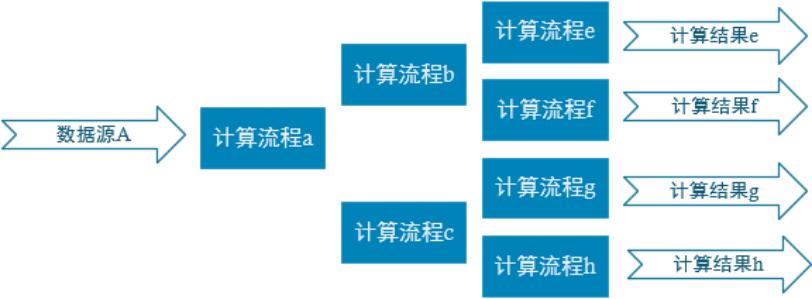
2.实时电商数仓分层规划
1)ODS层
ODS层:存放原始数据,包括日志数据和业务数据。
2)DWD层
DWD层:根据数据对象为单位进行分流,比如订单、页面访问等等。
3)DIM层
DIM层:存放的是维度数据
4)DWM层
DWM层:对于部分数据对象进行进一步加工,比如独立访问、跳出行为,也可以和维度进行关联,形成宽表,依旧是明细数据。
5)DWS层
DWS层:根据某个主题将多个事实数据轻度聚合,形成主题宽表。
6)ADS层
ADS层:把ClickHouse中的数据根据可视化需求进行筛选聚合,得到最终结果。
二、实时数仓需求概览
1.离线计算和实时计算的比较
离线计算:在计算前已知所有的输入数据,输入数据不会产生变化。比如离线数仓,在今天早上一点,把昨天累积的数据进行计算分析,得到所需的结果。它的统计指标、报表繁多,但是对时效性不敏感。这属于批处理的操作,即根据确定范围的数据的一次性计算。
实时计算:输入的数据都是一个个输入并进行处理的,从一开始的时候并不需要知道所有的输入数据。与离线计算相比,运行时间短,计算量级较小。主要侧重对当日数据的实时监控,通常业务逻辑相对离线需求简单,统计指标也相对较少,更注重数据的时效性,这属于流处理的计算。
2.实时需求种类
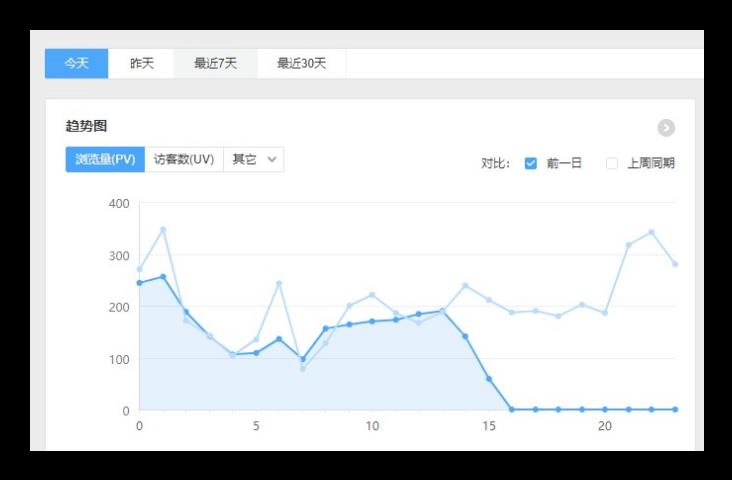
2.1 日常统计报表或分析图中需要包含当日部分
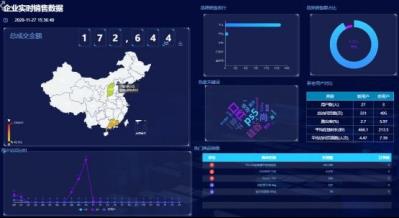
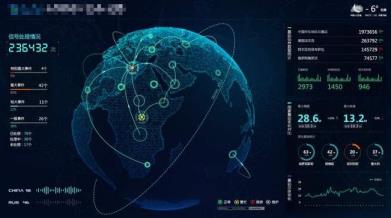
2.2 实时数据大屏监控
2.3 数据预警或提示
经过大数据实时计算得到的一些**风控预警、营销信息提示,**能够快速让风控或营销部分得到信息,以便采取各种应对。
比如,用户在电商、金融平台中正在进行一些非法或欺诈类操作,那么大数据实时计算可以快速的将情况筛选出来发送风控部门进行处理,甚至自动屏蔽。 或者检测到用户的行为对于某些商品具有较强的购买意愿,那么可以把这些“商机”推送给客服部门,让客服进行主动的跟进。
2.4 实时推荐系统
实时推荐就是根据用户的自身属性结合当前的访问行为,经过实时的推荐算法计算,从而将用户可能喜欢的商品、新闻、视频等推送给用户。
这种系统一般是由一个用户画像批处理加一个用户行为分析的流处理组合而成。
三、数仓架构分析
1.离线数仓架构
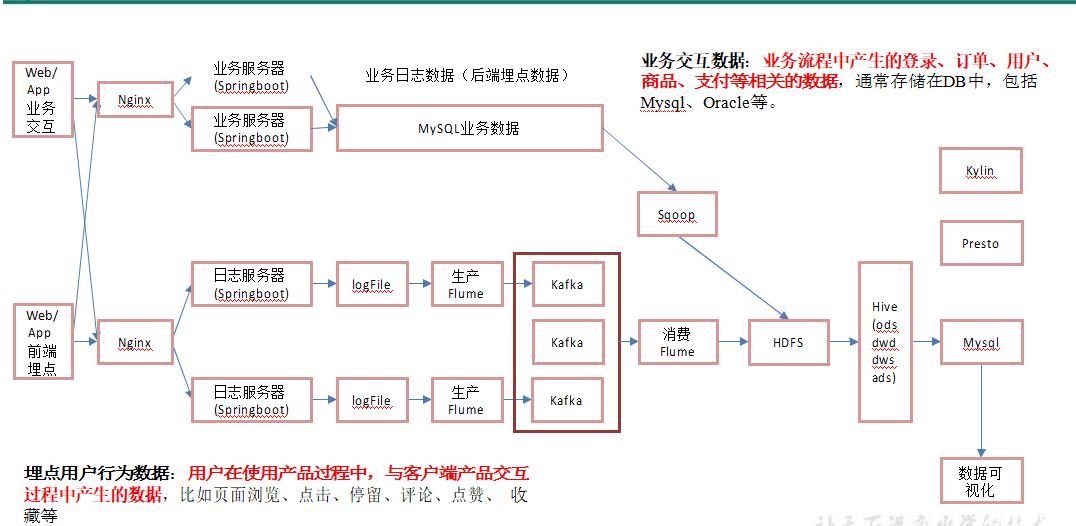
2.实时数仓架构
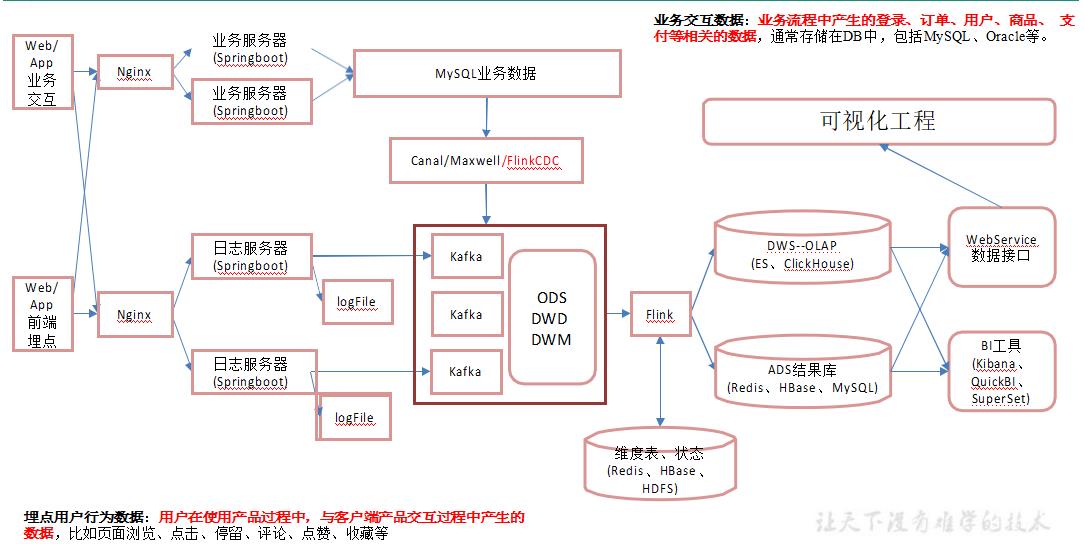
以上是关于大数据数仓项目架构的主要内容,如果未能解决你的问题,请参考以下文章