关于双11——离线数据仓库架构升级
Posted 京东大数据
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了关于双11——离线数据仓库架构升级相关的知识,希望对你有一定的参考价值。
随着京东业务的快速增加,对于离线数据仓库,每天几百T的数据增长量和日吞吐量达到PB级别的数据计算量,无论HDFS存储还是计算,都是一个很大的考验。离线数据仓库的稳定性很大程度上关乎着后续各集市的报表、各应用指标数据能否满足用户的完整性和时效性。而即将到来的双十一,流量、订单的更是数十倍于平日的数据量,无疑给仓库的计算压力也带来新的挑战,每年离线数据仓库的架构都要做针对性的升级,随着业务复杂度和的不断提高,升级工作也不再像以往只是简单进行扩展那么简单。
众所周知,离线数据仓库的数据源可谓是异常丰富,从关系型数据库(SqlServer、mysql、Oracle等)到NoSQL(MongoDB、PG、LOG等),多样性的数据源给数据仓库带来的是呈PB级数据量的增长。数据仓库计算量的增多,带来的是集群压力的增大,文件数、块数的增多,尤其是小文件数,对Namenodede 的压力也是空前的。结合仓库的任务类型,大多是HQL的MR任务,我们采取了一系列的方案保证集群的稳定性:
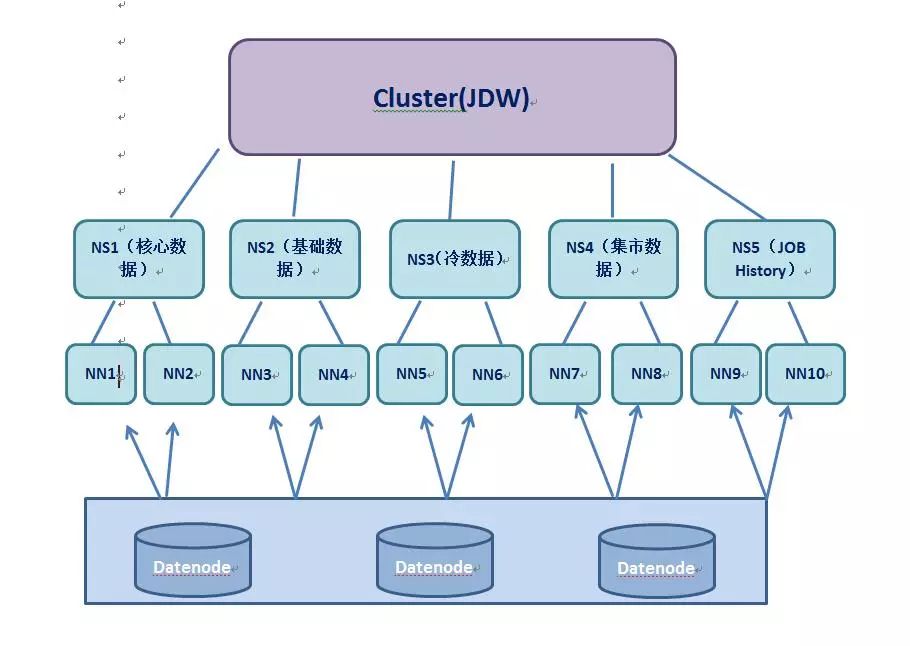
拆分多Namespace。拆分前数据仓库的HDFS数据主要分布在NS1,随着业务量的增加,客户端、DN与NN间的元数据的频繁传输导致NameNode节点的压力异常大,这压力来自CPU、磁盘、内存和网络带来的压力,带来NameNode的高负载,如图表所示为客户端、DN同NameNode进行的交互关联图:
为缓解NameNode的压力,按照当前JDW集群的实际情况,我们对数据仓库NS1进行了以下拆分:(1)用户粒度:将dd_edw_test、dd_edw_read、dd_sdm这几部分的用户的数据进行迁移到NS4;(2)库级别粒度:对基础层BDM库、BKT库层的数据迁移到NS2;(3)冷数据迁移:通过解析Namenode的元数据镜像文件,判断90天内未访问的数据我们归纳为冷数据,按照当前仓库的体量,仅dd_edw这部分数据每天增量约8T,然后将这部分数据挪到NS3。通过上面三部分的操作,集群的文件数、块数在各个NS得到合理的分配,间接减轻Namenode的压力。拆分后JDW仓库NS架构如下:
资源合理的分配。目前数据仓库采取的是Fair的调度算法,该调度算法默认是为每一个用户提供一个独立的资源池,再结合用户组和提交JOB客户端的配置来进行资源的划分。这种按照用户来区分业务线的划分保证了同一时间点关键任务的资源使用率。为此,我们按照仓库当前各业务线的运行状况,将集群资源划分了四个时段,分别保证凌晨核心以及其他业务线资源的合理使用。以下为各时段资源的配置图:
数据仓库基础表进行ORC的转换。作为列存储格式,ORC不管是HDFS的压缩率上,还是在计算速度方面很大程度上提升了效率。基于此,我们将逐步将仓库中基础层的表转化为ORC+SNAPPY的格式进行存储,相比于Text+LZO的存储格式,压缩比提高了10%以上,更大的节约了存储空间。而且在计算层面,ORC格式的数据在计算的时候每个task只输出单个文件,使用多个相互独立的RecordReaders并行读取相同的数据文件,在提升读取效率得同时降低了Namenode的负载,而且更快的提升了HQL的运算性能。
综上,作为大型HDFS集群,如何保证集群的稳定不是一蹴而就,而是结合实际业务进行相应的调整。
以上是关于关于双11——离线数据仓库架构升级的主要内容,如果未能解决你的问题,请参考以下文章
数仓架构的持续演进与发展 — 云原生湖仓一体离线实时一体SaaS模式