我对传统数据仓库粗浅的理解
Posted 与众不同的视角
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了我对传统数据仓库粗浅的理解相关的知识,希望对你有一定的参考价值。
当你无法预知未来的时候,相信你的第六感
如果说工作时我是一个理性的人,那么我骨子里一定是个感性的人,因为我一直很相信第六感,包括在大学时期对数据库的痴迷和毕业之后花大价钱考OCP(好吧OCP已经过时了,技术的发展速度就是这么快,这么不留情面)。
之所以要写这篇文章的原因,是希望让更多的人知道什么是数据仓库,作为数据的重要存储方式之一,数据库和数据仓库的区别如下:
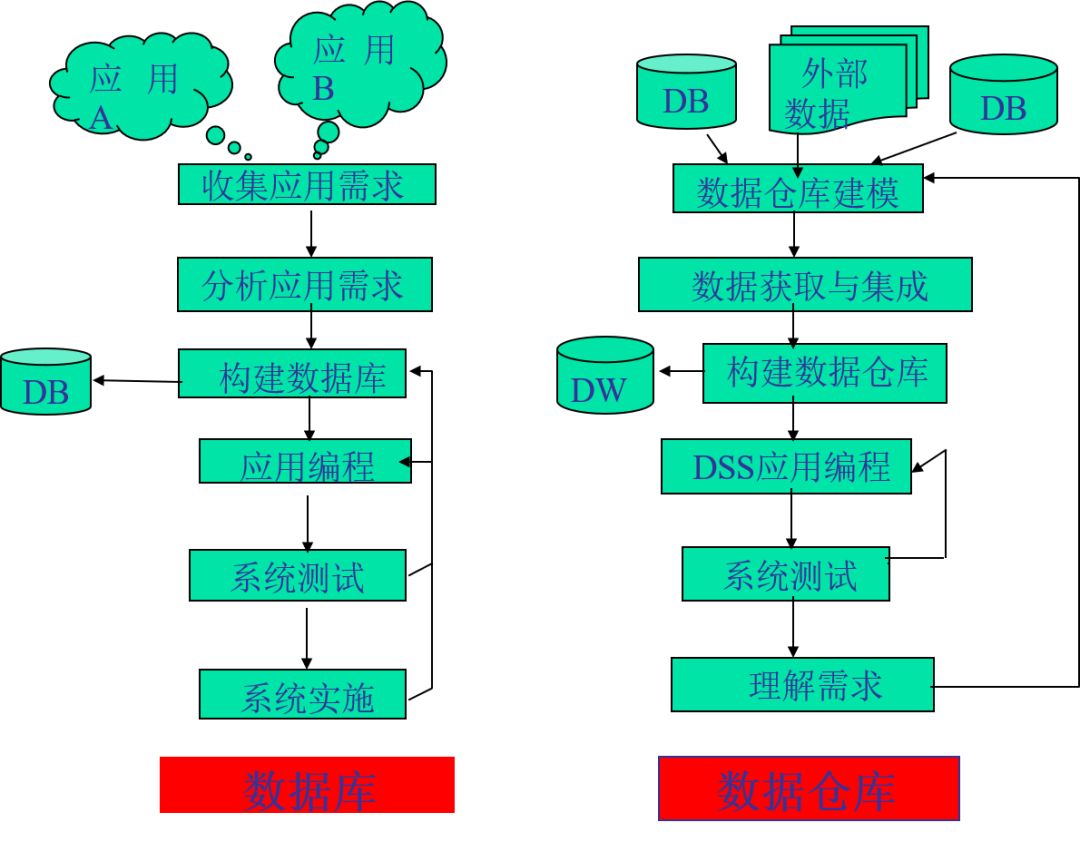


一个数仓项目大致会经历下面一些阶段
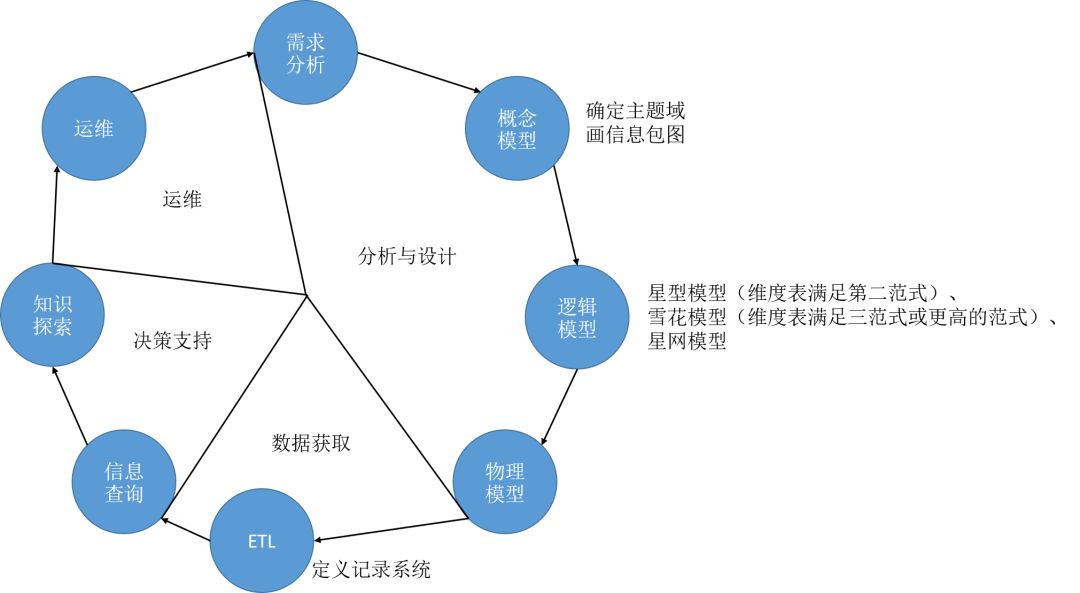
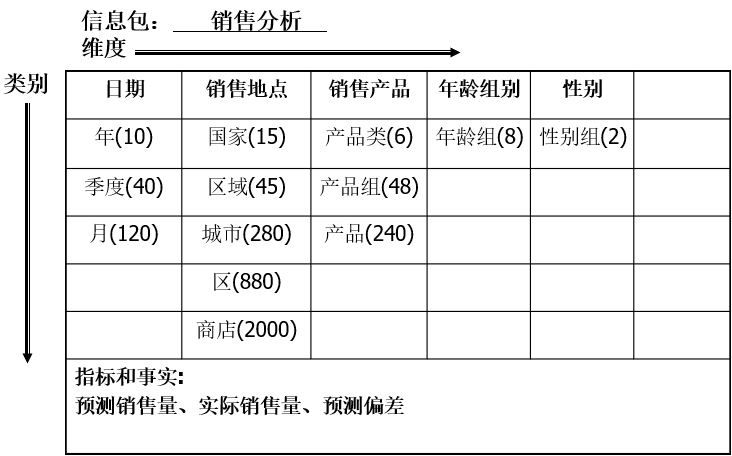
在“概念模型”阶段会用到信息包图:
在“逻辑模型”阶段我们要考虑数据“粒度”划分:
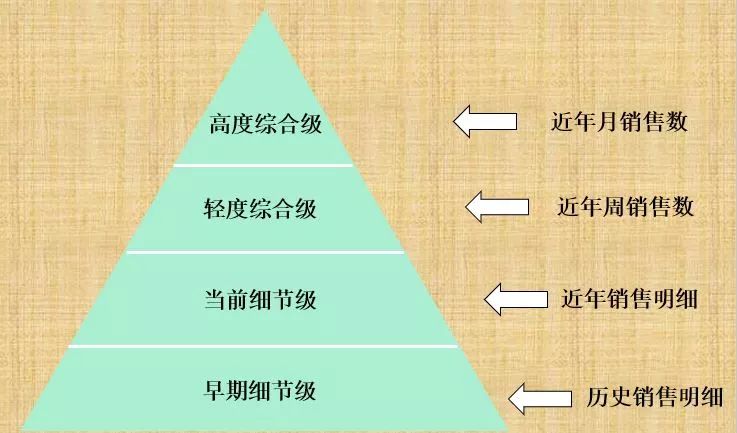
因为“粒度”深深地影响存放在数仓中的数据量的大小,同时影响数仓所能回答的问题类型。
所以,传统的相对完整的数仓项目,必然包含以下组成部分:
MDM(主数据管理)
ETL
数据仓库
报表系统
数据可视化
数据挖掘
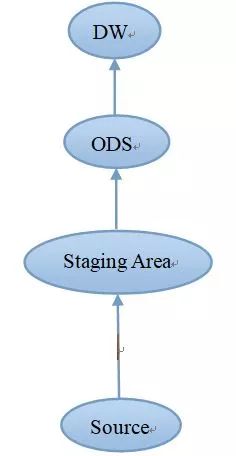
数据从源头Source开始,会先落地到Staging Area,数据存储格式可以是Flat File、XML或其他,之后会流向ODS层(数据模型一般采用第三范式),目的之一是出一些营运性报表,最后到DW,也就是数据仓库(数据模型表现为星型模型、雪花模型、星网模型),其中最重要的两类表是“事实表”和"维度表",事实表中主要存储指标类数据(好比“1”,“2”,“3”这种数值类型的值),维度表主要存储描述类信息(好比“高”、“矮”、“胖”、“瘦”这种值)。
我们也会记录与数仓项目有关的源系统信息,将其映射到各个主题:
主题名 |
属性名 |
数据源系统 |
源表名 |
源属性名 |
商品 |
商品号 |
库存子系统 |
商品 |
商品号 |
前面有提到数据模型,如果把数仓比作一个房子的话,那”数据模型“无疑类似于一个房子的户型图,常见的数据模型主要有三范式、星型模型、雪花模型、星网模型等。
范式
在讲范式之前,对于关系数据库不得不讲的几个概念如下:
“关系模式”一般用R表示,可以简单把它理解为表,如下图:
“元组”可以简单把它理解为表中的一行
简单属性:原子的,不可再分的
派生属性:可以由其它属性得来,如计算得来
单值属性:例如一个特定的职工只对应一个职工号和职工姓名
多值属性:在某些情况下,一个属性可能对应一组值。例如职工的亲属姓名可能有多个
Candidate key:若关系中的某一属性或属性组能唯一地标识一个元组,则称该属性或属性组为候选码
Primary Key:若一个关系有多个候选码,则选定其中一个为主码
Foreign key:若关系模式R中的属性或属性组非该关系的码,而是其他关系的码,则该属性或属性组对关系模式R而言是外码
通过分解,可以将一个低一级范式的关系模式转换成若干个高一级范式的关系模式,这个过程叫规范化(normalizer)。
主要的三个范式
第一范式(1NF):若关系模式R的每一个分量是不可再分的数据项。
第二范式(2NF):若关系模式属于1NF,且每一个非主属性完全依赖于码(主键)。
第三范式(3NF):当满足了2NF,并且消除了非主属性对码的传递函数依赖。即3NF消除了部分依赖和传递依赖。
星型模型
星型模型存取数据速度快,主要在于针对各个维做了大量的预处理,如按维进行预先的统计、分类、排序等。在星型模型中,通过维度表获得事实表数据。事实表与维度表的联系通过每个维度中的最细的详细类别实体进行连接。
雪花模型

雪
雪花模型
有时,维表还要向外延伸至详细类别实体,它是维表的附加信息,是维表的扩展。雪花模型的事实表与所有的维表都要进行连接(直接或间接)。相比星型模型,它的特点是贴近业务,数据冗余较少,但由于表连接的增加,导致效率相对星型模型要低一些。
网模型

构造星网模型的方法:
(1). 增加汇总事实表和衍生的维表形成星网模型
(2). 构造相关的事实表形成星网模型
数据仓库搭好架子
ETL填充内容
ETL大致过程
(1). 确定目标数据
(2). 确定源数据
(3). 确定映射关系
(4). 确定抽取规则
(5). 确定转换和清洗规则
(6). 为综合表制定计划
(7). 组织数据缓冲区域和检测工具
(8). 为所有的数据装载编写规程
(9). 维度表的抽取、转换和装载
(10). 事实表的抽取、转换和装载
数据质量问题
(1). 字段中的虚假值
(2). 数据值缺失
(3). 不一致的值
(4). 违反常规的不正确值
(5). 一个字段有多种用途
(6). 编码规则不一致,例如A系统“1”表示“男”,“2”表示“女”;B系统“M”表示“男”,“F"表示”女“。
以终为始
启动数仓项目的主要原因有以下几个方面:
(1). 查询与报表:
例如:给出销售量最好的产品名单
找出出现问题的地区
对比其他的数据
显示最大的利润
(2). 多维分析与原因分析
例如:追踪查找出现问题的原因
(3). 预测未来
(4). 实时决策
例如:当一个地区的销售低于目标值时,提出警告信息
(5). 自动决策
数据仓库的发展
数仓的发展经历了从早期将数据集中在同一处,到承认数据可以散落在不同的地方,而所有这些地方的数据对企业来说就形成了一个Data Lake(数据池)。
情理之中
很多事情的发生看似毫无关联,但细想又会发现是情理之中,例如,虽然早期经历了很多数仓的项目,特别是报表项目:

但是,当在做项目的过程中遇到被频繁的需求变更折磨到怀疑人生,被经常性加班的日常折磨到天天抓狂的时候,如果你是一个善于思考的人,一定会想方设法去寻找出问题的原因,有没有更好的替代方案,这也是我去学习ACP敏捷的原因,因为我们每个人都在试图抓住一根救命稻草。随着你吸收的知识越来越多,眼界越来越开阔,最终会对你的思维模式,看待问题的角度产生重大的影响,这也是为什么我又继续学了NPDP的原因:

希望越来越多的人知道数仓是什么,这样我在向跨领域的朋友介绍自己以前的经历时,别人不会一脸懵逼,我也不会很尴尬 。或者我也可以直接说我是搞技术出身的。
。或者我也可以直接说我是搞技术出身的。
我们的愿景:价值决定品牌,黏性决定寿命,我们立志于做一个长寿的企业
我们的使命:为您的时间赋予价值
敬请期待下周精彩内容

微博:@unique_perspective


合作推广请联系小编:237483992@qq.com
图片来自互联网,版权归原作者
以上是关于我对传统数据仓库粗浅的理解的主要内容,如果未能解决你的问题,请参考以下文章