实时数据仓库介绍(Genie)
Posted 数据工程的崛起
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了实时数据仓库介绍(Genie)相关的知识,希望对你有一定的参考价值。
离线数据仓库是t+1的数据,也就是说数据时效性是处理前一天的数据。一般来说离线方案同步数据的策略是每天定时同步一次数据,而且基本是同步一次全量数据。也就是说每天一个全量数据(业务库)的镜像。
除了时效性还有一点就是镜像的数据状态只有一个,所以想知道某个值的历史变化过程,就需要走拉链表(非常耗时耗资源)。实时数据仓库的实现方式很多,但是大多都是殊途同归。第一 访问实时数据。第二结果能近似实时的返回。当然离线仓库如果优化的好,完成第二点也是可以实现的。思考两个问题,为什么要用实时数据?为什么要有实时数据仓库?
近几年数据工程师们在如何提高数据时效性上做了非常多的努力和尝试。推动这些实时数据同步,处理技术发展的当然还是场景与需求。中国的大互联网环境竞争非常激烈,如何提高用户转化率变得尤为关键。
用户画像,推荐系统,漏斗分析,智能营销等等 数据相关的产品都离不开实时数据的处理与计算。
获取实时数据最直接的方式是直连业务库,优势明显缺点也很明显。有些逻辑需要跨库多源查询关联的时候直接连业务库就行不通了。所以首先需要把多个源头的数据集中同步起来,这个同步过程就是一个非常具有挑战的地方,要考虑数据的时效性,对业务系统的侵入性,数据的安全性 和数据的一致性等等诸多难题。
所以我们需要一个同步数据的工具,它需要有以下几个特点:
1: 能够近似实时的同步生产库的数据和日志数据
2: 和生产库还有应用服务器完全解耦
3: 同步出来的数据可以分发到其他的存储
4: 整个同步过程保证数据不丢失,或者说可以按照任意时间批量重新同步
宜信大数据敏捷团队,开发的dbus和wormhole 能很好的满足以上4点
dbus利用数据库的binlog进行数据抽取,binlog一般延迟是比较低了这样既保证的实时的特性也保证了对成产库的0侵入。
其实利用日志来构建一个健壮的数据系统是一个很常见的方案。hbase利用wal来保证可靠性,mysql 主备同步使用binlog,分布式一致性算法Raft利用日志保证一致性,还有apache kafka 也是利用了日志来实现的。
dbus很好的利用了数据库的binlog日志并且进行统一的schema转化形成了自己日志标准以便支持多种数据源。dbus的定义是一个商业级别的数据总线系统。它可以实时的将数据从数据源抽取发送给kafka。
然后wormhole负责讲数据同步写入其他的存储之中。kafka就成了一个真正意义上的数据总线,wormhole支持sink端按照任意时间开始消费kafka中的数据,这样也就能很好的进行数据回溯。
Genie的实时架构如下
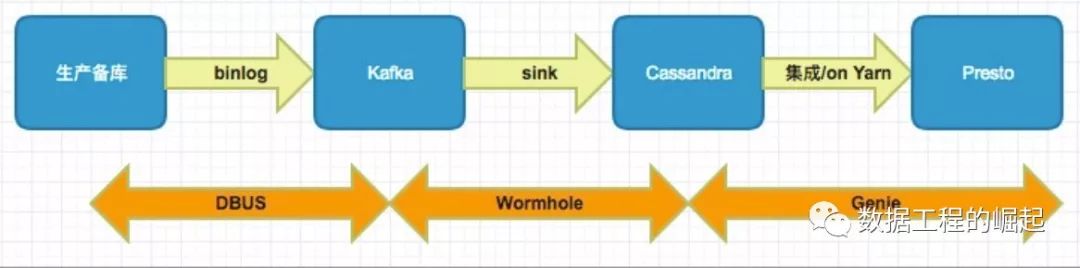
有了dbus和wormhole我们可以很轻松的把数据从生产备库实时的同步到我们的cassandra集群然后再同步presto为用户提供sql语言计算。
通过这个简单的架构我们高效的完成了实时数据仓库的搭建,并且实现的公司的实时报表平台和一些实时营销类的数据产品。
对于为什么会使用presto我可以给出以下的答案:
1:presto 拥有交互级别的数据计算查询体验
2:presto 支持水平扩展,presto on yarn (slider)
3:支持标准sql 并且方便扩展
4:facebook uber netflix 生产使用
5:开源 语言java 符合我们团队技术栈, 自定义函数
6:支持多数据源关联join 逻辑下推 ,presto 可以接cassandra 可以接hdfs 等等 pluggable connector to provide metadata and data for queries
7: pipelined executions - 减少了不必要的I/O开销
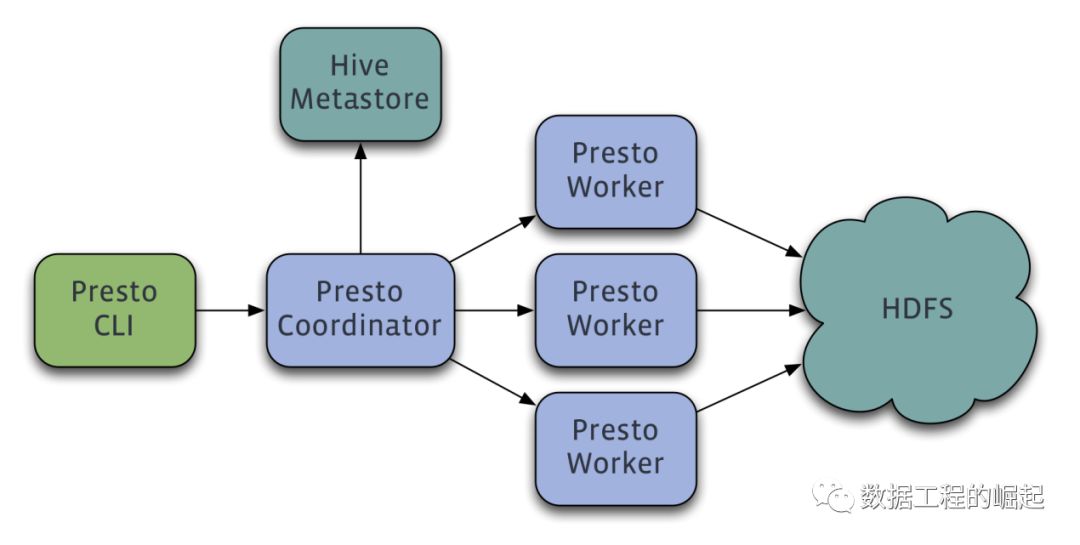
presto 是m/s架构 ,整体细节不多说了。presto 有个数据存储抽象层,可以支持不同的数据存储上执行sql计算。presto提供了metadata api,data location api, data stream api 支持自开发可插拔的connector。
免不了的对比:
在我们的方案中是presto on cassandra的,因为cassandra 相对于hbase来说可用性更好一些比较适合adhoc查询场景。hbase cap中偏向 c ,cassandra cap中偏向a。
Cassandra 是一个非常优秀的数据库,方便易用,底层使用Log-Structured Merge-Tree 有兴趣的同学可以研究一下。
综上我大概的介绍了宜人贷的实时数据处理架构,下面我们看一下整体的数据处理架构。
整体lambda架构speed层利用dbus和wormhole组装成了一套实时数据总线,speed layer可以直接支撑实时数据产品。DataLake是一个抽象的概念实现的方式很多,我们主要是利用hdfs + cassandra 存储数据 计算引擎主要已hive presto为主,再通过平台统一的metadata 对元数据整合提供 这样就现实了一个完整的DataLake。DataLake主要的应用场景是高级灵活的分析,查询场景 如 ml 。
DataLake 和数据仓库的区别是,DataLake更加敏捷灵活侧重数据的获取,DW 侧重于标准,管理,安全,和快速索引。
参考文献:
https://www.confluent.io/blog/using-logs-to-build-a-solid-data-infrastructure-or-why-dual-writes-are-a-bad-idea/
http://thesecretlivesofdata.com/raft/
https://engineering.linkedin.com/data-replication/open-sourcing-databus-linkedins-low-latency-change-data-capture-system
https://yq.aliyun.com/articles/195388
https://www.cnblogs.com/tgzhu/p/6033373.html
以上是关于实时数据仓库介绍(Genie)的主要内容,如果未能解决你的问题,请参考以下文章