数据仓库建设3——需求分析和模型设计
Posted 二环上狂奔的大象
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了数据仓库建设3——需求分析和模型设计相关的知识,希望对你有一定的参考价值。
数仓需求分析
1.需求分析原则
由粗到细,由宏观到微观。
从不同层次的客户代表收集不同层次的需求
循序渐进,逐步挖掘隐形需求
2.需求获取
需求获取过程
3.需求分析
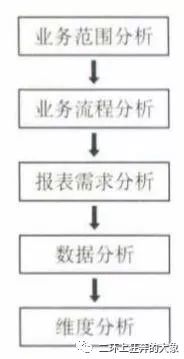
需求分析过程
4.业务流程分析
一般以泳道图的形式展现。将各个业务的流程细化。
5.报表需求分析
列举报表说明、报表样式、预置条件、报表元素说明、度量(包括要显示的和不显示但被引用到的)、条件选择组件(下拉框、日期选择框等)、钻取。
6.维度分析
列举各维度的需求描述、统计指标、指标类别、是否交叉分析、需求来源、需求分类、使用目的、数据来源、是否整理维度矩阵。
7.维度矩阵
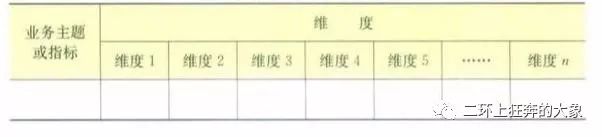
维度矩阵
8.需求论证(略)
数据仓库搭建

数据仓库建设流程
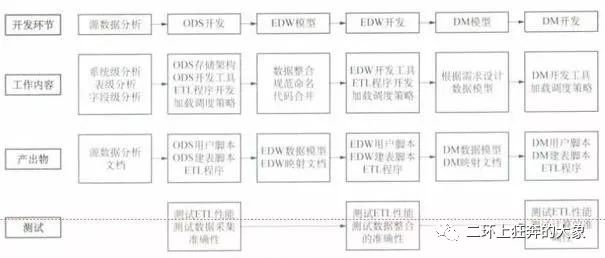
数据仓库开发流程
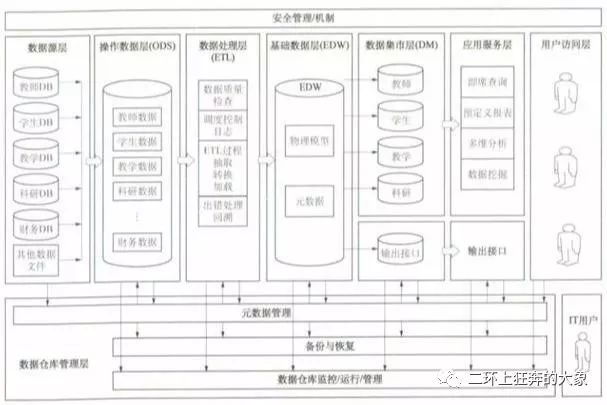
高校数据仓库系统架构
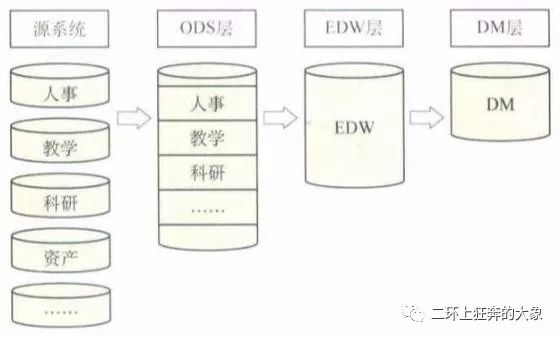
高校数据仓库数据架构
为方便管理和使用,数据仓库物理存储上使用一个数据库,逻辑上使用不同用户区分不同数据存储区,通过权限设置控制访问范围。
ODS层一个业务数据对应一个用户,不同业务系统数据在ODS层单独存储,同时设置一个独立的ODS层用户来调度ETL执行。基础数据层使用一个EDW用户。数据集市层使用一个DM用户。外部访问再设置一个只读用户。

数据仓库存储规划
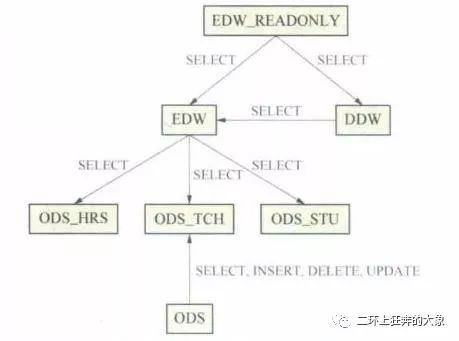
数据仓库各用户访问权限
1.数据仓库主题规划
主题划分的本质是对数据仓库涉及到的所有数据进行抽象并合理分类。主题具有分层的特点,一个完整的数据库主题是一个树状的结构。主题划分方法及过程:
确定用户所处的行业及所要开展的业务。
详细了解用户目前已有的信息系统。
详细了解各信息系统的数据内容及计划纳入数据库的外部数据内容。
详细分析所有源数据主要反映的客观事物,此时应忘记系统的概念,重点关注数据本身,将抽象出的客观事物初步定义为主题域。
在每个主题域下再进行更细粒度的划分,作为子主题。
规划数据仓库主题时的原则:
主题是在较高层次将数据归类的标准,每一个主题对应一个宏观分析领域。
主题划分要抽象业务的本质,避免与业务、系统混淆。
主题域个数不宜太多,最好控制在10个以内。
主题域具有分层结构,避免扁平化随意扩大主题域。
每个主题都应该有明确的定义和边界。
主题划分要充分考虑拓展性,覆盖当前和未来可预见的业务数据,未来的数据能找到最适合的主题位置。
高校数据仓库主题划分
2.源数据分析
主要为帮助数据仓库设计人员充分了解业务,源系统主要功能、源系统数据结构、数据内容、相互关系、数据使用情况等方面内容,进而为后续设计打下基础。
源数据分析过程
(1)源系统分析
①源系统包含的业务。②源系统主要功能。③源系统的重要性,是否核心业务系统。④源系统中数据的流动过程。⑤源系统与其他数据库的关系。⑥源系统数据库类型。⑦源系统数据库环境。⑧源系统数据量。
(2)源表分析
①整理表清单。②统计各表数据量。③划分表类型。④分析表的业务信息和主要字段。⑤筛选入仓表。⑥整理主外键依赖关系。
(3)源字段分析
①整理数据库表字段及中文含义。②整理字段数据类型,是否可谓null。③整理物理主外键,逻辑主外键。④对特殊字段进行调研。⑤筛选入仓字段。
3.数据模型设计
整合不同业务系统的数据,进行规范存储,建立清晰合理的数据关系,便于理解业务。
(1)操作数据层(ODS)建模
ODS层的表结构和业务系统基本一致,表名和字段名无需重新定义,要根据需要增加一些标识字段,如ETL加载时间(确定ETL执行时间和加载数据是否正常),如果没有业务日期,增加业务日期字段(标识是哪一天的数据,保留历史数据)。
(2)基础层(EDW)建模
功能定位:①按主题分类存储、管理梳理后的业务实体,作为业务人员的业务视图和技术人员的数据视图。②使用关系型模型组织实体,减少数据冗余。③存储通过校验规则清洗后的干净数据。④统一编码标准化业务数据,包括业务类和编码类的重新编码。⑤保留业务中的所有历史变化,特别是业务的状态等。⑥根据业务的发展变化,可以灵活调整数据模型,满足高拓展性。
建模原则:源系统稳定、合理、符合3NF的结构要沿用。建模前对源系统结构有清晰的理解,发现不合理的地方并重构。关注数据反映的业务实体,找到最合适的主题位置。跨系统集成,表结构的横向合并和纵向合并。识别数据的真正源头,丢弃重复的数据。逻辑模型和物理模型命名要统一、规范。
基础层命名规范:统一采用英文或英文缩写进行命名。
基础层代码合并:重复的字典代码表合并成一套标准代码。只有多个系统同时存在的代码表才需要合并重新定义。
数据在集成的过程中不进行更新,只加时间标识,数据的存储方式主要分为拉链表、快照表和流水表的方式进行存储。EDW层的数据每天通过增量和全量的方式进行加载,数据不进行删除,持续保存历史数据。
拉链表的优点是数据不会产生冗余,节省存储空间;缺点是容易出现断链的情况,数据质量会受到影响。显著特征是通过字段开始日期(SDATE)和结束日期(EDATE)来标识,表示某一条记录在开始日期和结束日期之间是有效的数据。当前日期的有效数据是以‘99999999’为结束日期;当数据发生变化时,会将‘99999999’更新为变化的前一天,并插一条变化后的数据作为当前数据,以变化当天的日期为开始日期,以‘99999999’为结束日期。这就是整个接链表的变化过程。适用于以下情况:【大数据量的数据表】不会重复存储数据,有效的节约存储空间,提高对该数据表数据的存取效率。【字段较少的数据表】在插入新记录时需要将新记录与原有记录做比较,比较的时候需要逐个字段进行比较。【数据表的逻辑主键明确,需要清晰反映数据业务变化过程的时候】
快照表是每天保存全量数据,通过时间戳来表示整张数据表的每一个时间点的快照。优点是数据处理逻辑简单、方便,数据质量较高不会出现错误。缺点是数据存在冗余,存取效率低。适用于以下情况:【数据量较小的数据表】快照表是每天一个快照,数据量重复存储。数据量较大不宜使用快照表,会占用大量的存储空间,并且随着时间的推移,访问效率会越来越低。【字段较多的数据表】字段较多,如果不采用快照表而采用拉链表会影响数据仓库数据的跑批效率。
(3)集市层(DM)建模
数据仓库的一个子集,主要面向部门级业务。为特定用户预先计算好统计指标,以满足用户对性能的需求。采用维度建模方法,方便应用层使用数据,利用空间换时间的方式提高访问性能,按数据汇总的粒度和面向的应用,一般分为基础层、轻度汇总层、高度汇总层。
基础层:从EDW抽象的维度模型,包括尽可能多的维度和指标,侧重维度和指标的全面性,可以满足不同应用的需求,关注数据的重复利用。
轻度汇总层:基础层明细数据的轻量级汇总加工,粒度相对粗一些,适合基础层数据量较大,访问效率较低的场景,通过开发通用性比较高的汇总数据,提高轻度汇总层数据的有效利用率,便于汇总数据的而管理和维护。
高度汇总层:面向特定应用需求的数据存储区域,解决复杂报表的需求,数据来自基础层和轻度汇总层,在此基础上进行跨业务数据的融合、汇总、加工等,直接查询便可以产生用户需要的报表。
根据统计分析需求提炼指标和维度,进而形成指标维度矩阵,再进行模型设计。采用维度建模的方式建立模型,考虑空间和时间因素,存储空间足够的情况下采取更多有效冗余,满足性能需要和访问效率。主要采用宽表设计方式,把一个主题尽可能多的指标和维度合并在一起,满足多种不同应用需求,会有一部分行数据冗余,但减少了表之间的关联,提高了数据应用效率。数据存储形式可以采用物理表、物化视图、视图。视图可以灵活的修改和调整业务逻辑,对性能开销小的应用尽可能采用视图方式,及时响应需求变更。对于性能开销较大的应用,采用物理表和物化视图提高访问效率。
以上是关于数据仓库建设3——需求分析和模型设计的主要内容,如果未能解决你的问题,请参考以下文章