知识图谱,能否成为企业下一代的数据仓库?
Posted 明略科技集团
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了知识图谱,能否成为企业下一代的数据仓库?相关的知识,希望对你有一定的参考价值。


张杰博士是明略科技资深科学家,明略科学院知识工程实验室主任,加入明略科技后便一直在负责明略科技“行业知识图谱”的研究和搭建工作,在此之前曾在华为中央研究院从事机器学习方面的研究工作。
张杰提到:“在我们内部,我们认为知识图谱是企业下一代的数据仓库。它的优点除了能够高效地进行深度关系查询外,还能图谱基础之上做一些推广,通过引入常识知识和领域知识,由已有的知识产生新的知识。”

数据仓库的概念最早是在1990年由 比尔·恩门(Bill Inmon)提出。这里需要区别数据库和数据仓库之间的不同。
数据库是一种逻辑概念,用来存放数据,由多表组成,目前市面上流行的数据库例如有 Oracle、DB2、MySQL、Sybase、MS SQL Server等。
而数据仓库则是数据库概念的升级。从逻辑上理解,数据库和数据仓库没有区别,都是通过数据库软件实现存放数据的地方;只不过从数据量来说,数据仓库要比数据库更庞大得多。数据仓库主要用于数据挖掘和数据分析,支持复杂的分析操作,侧重决策支持,并且提供直观易懂的查询结果。
在比尔的著作《Building the Data Warehouse》一书中,他将数据仓库定义为:

数据仓库是一个面向主题的、集成的、相对稳定的、反映历史变化的数据集合,用于支持管理决策。

这种组织数据方式(即面向业务过程的数据组织方式),通俗来说,就是将数据物理集中在一起。从存储的角度来看,数据就是一张张独立的表结构,如常用的会员表、订单表等,表与表之间无法在数据层面整合到一起,需要通过外在的辅助工具才能进行逻辑与数据梳理,因此这种形式又被称为物理集中,而不是逻辑集中。
这种传统的数据仓库,其优势在于统计性报表,能够高效地进行数据统计。
但其缺点正如前面张杰博士所提到的:
1)对于这种结构化的数据,需要提前定义好结构(清楚地知道数据的格式和关系),且在添加数据的过程中很难改变结构。这种结构化的数据价值密度比较高,但在大数据时代我们不可能把所有的数据事先定义好,因此也就无法利用目前互联网中出现的大量非结构化的数据。
2)针对1)中的情况,目前也有很多企业使用像Hadoop这种分布式处理框架来开发大数据平台,这可以存储一些事先定义不好的、量特别大的、或结构化数据库不好索引的数据。但这些数据之间如何有效关联,如何进行深度查询依然存在困难。例如通过结构化的或大数据平台的数仓,可以胜任一度关系、二度关系的查询,但涉及到四度、五度或者隐形关系查询时,就会非常困难。

知识图谱最早是在2012年由谷歌提出的一个概念,但事实上在很早就已经有了相关的研究(称为知识工程)。
知识图谱本质上是语义网络,是一种基于图的数据结构,由节点(Point)和边(Edge)组成。在知识图谱里,每个节点表示现实世界中存在的“实体”,每条边为实体与实体之间的“关系”。知识图谱也是“关系”的最有效的表示方式。通俗地讲,知识图谱就是把所有不同种类的信息(Heterogeneous Information)连接在一起而得到的一个关系网络。
张杰表示:“在知识组织层面上,图谱化将是企业进行数据管理的未来趋势。”
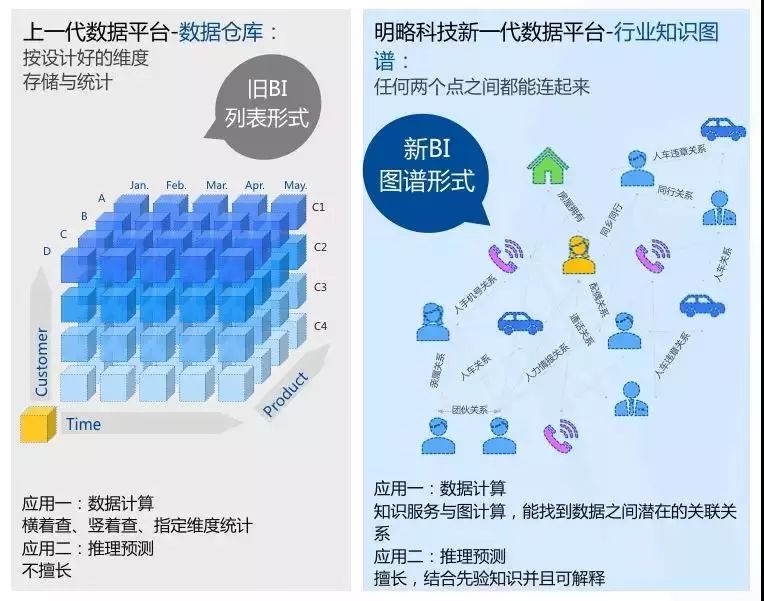
一方面,它便于将客户已有的结构化知识做更深的度数上的关联,同时保证查询效率,深度关联是传统数仓的技术框架下不善于实现的。另一方面可以帮助客户从来自于物联网、互联网等海量的非结构化数据中抽取出知识片段,从而拓展客户的数据维度,增大知识储量,释放出大数据红利。
而在知识表示层面上,知识图谱则是上游大数据和下游AI任务的有效连接。图谱化之后的知识便于进一步的语义化,知识碎片关联起来形成图谱之后,更多关联信息意味着更加丰富的语义信息。
经过适当的引入常识知识和领域知识,可以对图谱中的节点和关系做向量化处理,进而突破以往基于字符串匹配的浅层语义,更加便利、有效的帮助客户组织领域知识,为流程优化、辅助决策、预测分析等下游应用提供基础服务。
明略科技在这方面有足够多的构想和实践。例如在知识表示方面,目前明略科技聚焦于如下几个研究问题:带有部分属性和标签的静态图谱如何向量化表示,如何从动态变化且不符合马尔可夫性的图谱中挖掘出事件间的因果关系,常识知识、领域知识、非结构化碎片知识如何映射到相同的语义空间中,如何用统一的知识表示框架为下游的分类、检索、推荐、问答等任务提供知识服务。
然而目前为止知识图谱在成为数仓的过程中,依然存在着研究上的和产业上的问题。
在研究方面,有人曾对近几年国际顶会上的相关工作做了全方位分析,他们发现在知识图谱落地过程中的每个环节都还存在各自的问题:构建层面,目前比较关注的包括弱监督、远程监督、自监督、小样本等抽取方案;推理层面,主要集中在图神经网络、基于图表示学习的研究等;知识建模层面,则有一些事理图谱(这个是由哈工大首先提出的一种概念)、动态知识图谱、时序点过程的探索。
其次在产业应用方面:
首先,对于构建知识图谱的“数仓”,眼下最主要的问题是大规模、低时延下的效率问题。目前企业所能掌握的关系数据一般都在千万到百亿节点的规模,未来随着5G和物联网的普及,其规模会更大,而且很多场景下要求在秒级甚至毫秒级返回查询结果。这不光是对底层图数据库的挑战,很多上层AI任务的算法要配合中层的图挖掘算法和更底层的图数据库操作算子一起做跨层联合的并行化优化。
另外一个挑战是知识完备性问题,使用知识图谱的目的,除了让它做为一种中间态的数据服务之外,还期待能引入常识知识和领域知识,在大规模数据中做自动推理和补全,当图谱中的知识未达到一定的量级和丰富度之前,推理的准确度很难保证甚至难以开展,两者之间不是线性关系。
此外,也有人提到,现在越来越多的应用,其输入不仅限于文本,还会有图片、音频、视频等多模态的内容,如何为多模态的知识图谱构建提供一个比较好的解决方案,在未来一段时间里依然是一个具有挑战性的问题。
因此,张杰博士作为补充也指出,“知识图谱不是替换数据仓库,而是作为数据仓库的有效互补。”
[1] 百度百科, https://baike.baidu.com/item/数据仓库
[2] 数据库 与 数据仓库的本质区别是什么?,知乎问答,
https://www.zhihu.com/question/20623931
[3] 机器之心 Pro,
https://www.jiqizhixin.com/graph/technologies/6e896233-3f15-47a4-9b2e-479d7cc5478b
https://www.infoq.cn/article/OfDP3jgOaZlg7ogmfEwk
https://www.infoq.cn/article/DGJb0z4jKw8jzyf90dAE
【 相关阅读 】
明略科技集团与腾讯联合发布政务AI中台知识图谱工具箱 共建WeCity未来城市
DCA第八批大数据产品能力评测结果公布,明略知识图谱榜上有名
《人工智能变革欺诈管理》报告发布 明略科技知识图谱入选典型技术案例
以上是关于知识图谱,能否成为企业下一代的数据仓库?的主要内容,如果未能解决你的问题,请参考以下文章
参会|人工智能“图神经网络与知识图谱核心技术及应用培训班”(10.15-10.18,北京,实地视频同步教学)