0644-5.16.1-如何在CDH5中使用Spark2.4 Thrift
Posted Hadoop实操
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了0644-5.16.1-如何在CDH5中使用Spark2.4 Thrift相关的知识,希望对你有一定的参考价值。
温馨提示:如果使用电脑查看图片不清晰,可以使用手机打开文章单击文中的图片放大查看高清原图。
Fayson的github:
https://github.com/fayson/cdhproject
提示:代码块部分可以左右滑动查看噢
1
文档编写目的
Fayson在前面的文章中介绍过什么是Spark Thrift,Spark Thrift的缺陷,以及Spark Thrift在CDH5中的使用情况,参考《》。
在CDH5中通过自己单独安装的方式运行Thrift服务现在已经调通并在使用的是如下版本组合:
1.在CDH5中安装Spark1.6的Thrift服务,参考《》
2.在CDH5中安装Spark2.1的Thrift服务,参考《》
从Spark2.2开始到最新的Spark2.4,因为变化较大,不能够采用上述两种办法直接替换jar包的方式实现,更多的依赖问题导致需要重新编译或者修改更多的东西才能在CDH5中使用最新的Spark2.4的Thrift。本文主要介绍使用网易的一个开源工具Kyuubi来实现Spark Thrift的功能。
测试环境:
1.Redhat7.4
2.CDH5.16.1
3.集群未启用Kerberos
4.Spark2.4.0.cloudera2-1
2
Kyuubi介绍
Kyuubi是Apache Spark的原始Thrift JDBC/ODBC服务的增强版,它由网易开源,并已经使用过到了网易现有的大数据平台中。它主要用于将Spark SQL直接运行到集群,其中包括与HDFS,YARN,Hive Metastore等组件的集成,并且它本身也具备安全功能。Kyuubi是一个可以保证端到端多租户的Spark Thrift服务。
Thrift JDBC/ODBC可以基于Spark SQL提供ad-hoc的SQL查询服务,充当JDBC/ODBC或命令行的分布式查询引擎。在这个模式下,最终用户或应用程序可以直接使用SQL的方式与Spark SQL进行交互,而不需要编写任何代码。我们可以使用一些支持JDBC/ODBC连接的BI工具(例如Tableau,NetEase YouData等),使用大量数据制作漂亮的业务报告。利用Apache Spark的功能,我们可以将在Hadoop之上提供比Hive更好的性能。
但不幸的是,由于Spark自身架构的局限性,要用作企业级产品,与HiveServer2相比存在许多问题,例如多租户隔离,身份验证/授权,高并发性,高可用性等等。Apache Spark社区对该模块的支持一直处于长期停滞状态。
Kyuubi以某种方式增强了Thrift JDBC/ODBC服务以解决这些现有问题,如下表所示。
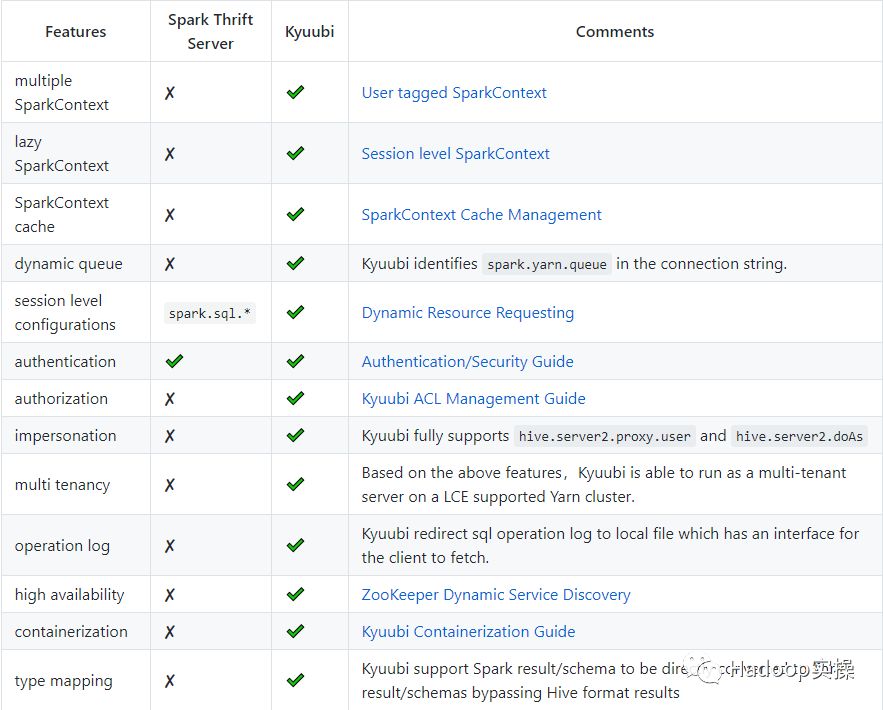
参考:
https://github.com/yaooqinn/kyuubi关于网易自身的描述参考《》

3
在CDH5中使用Kyuubi
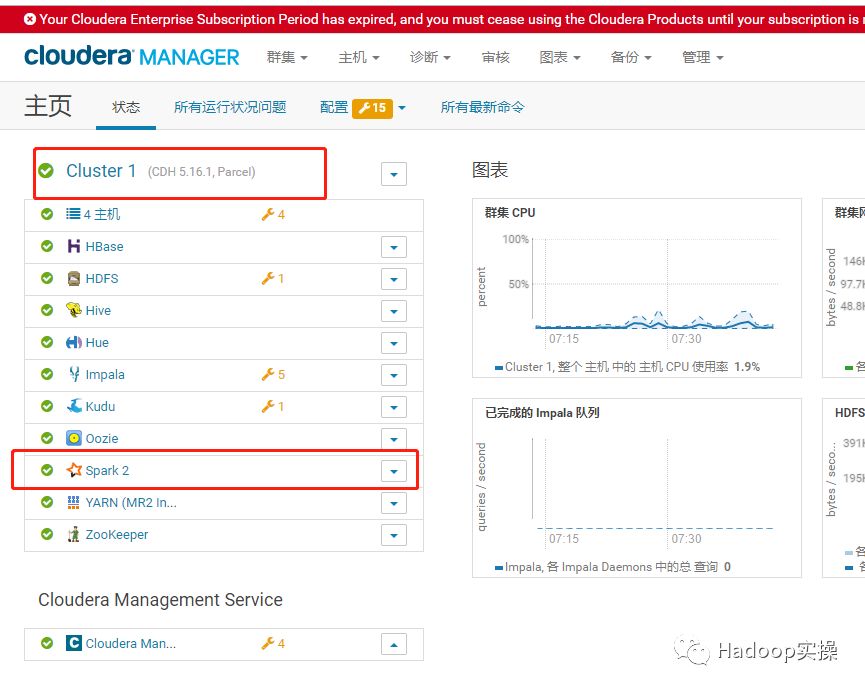
1.确认目前CDH的环境
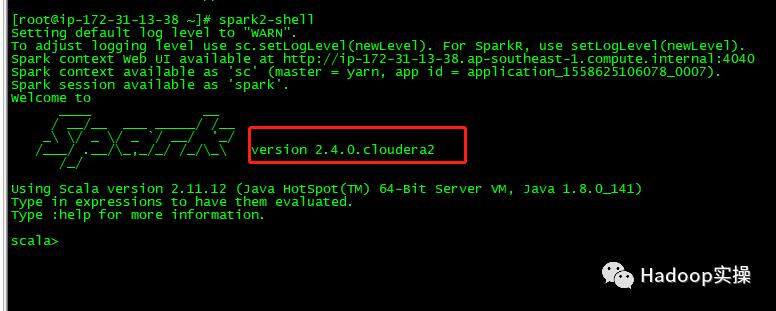
2.确认Spark2的版本
3.到Kyuubi下载已经编译好的最新的包。
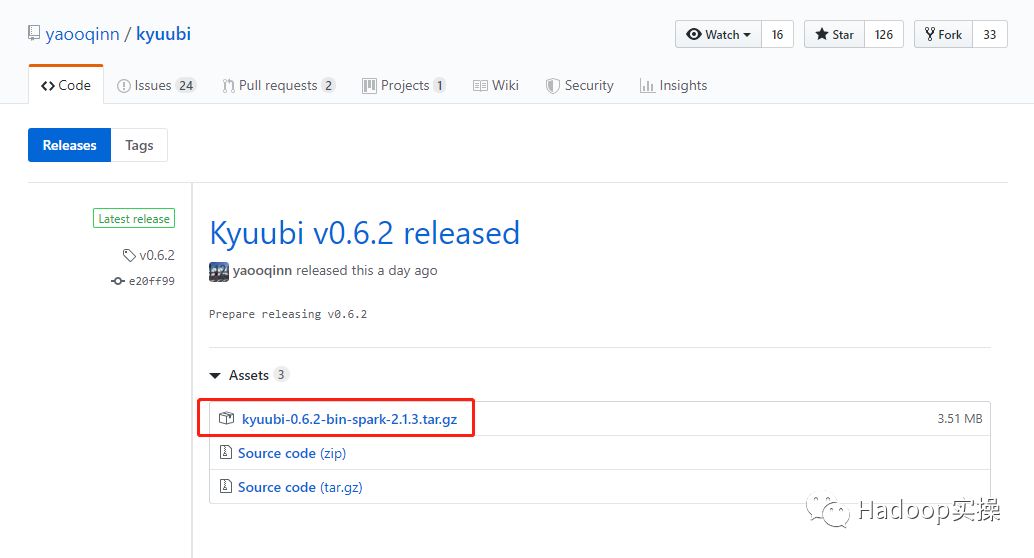
https://github.com/yaooqinn/kyuubi/releases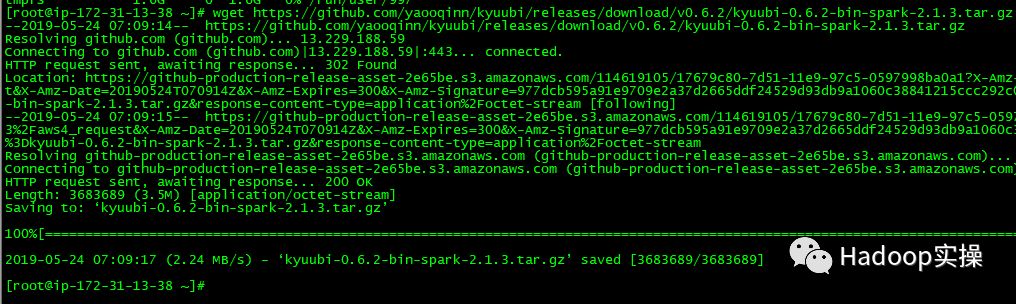
4.启动kyuubi服务。
export YARN_CONF_DIR=/etc/hadoop/conf.cloudera.yarn/
export SPARK_HOME=/opt/cloudera/parcels/SPARK2/lib/spark2
./start-kyuubi.sh \
--master yarn \
--deploy-mode client \
--driver-memory 10g \
--conf spark.kyuubi.frontend.bind.port=10009

5.通过beeline连接Spark Thrift,执行最简单的查询
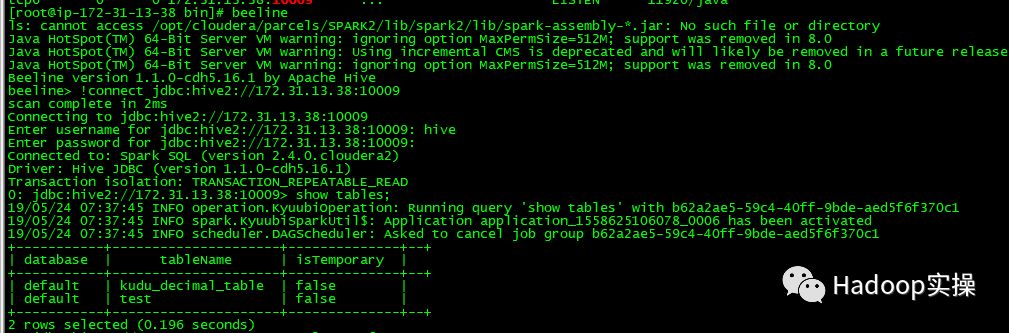
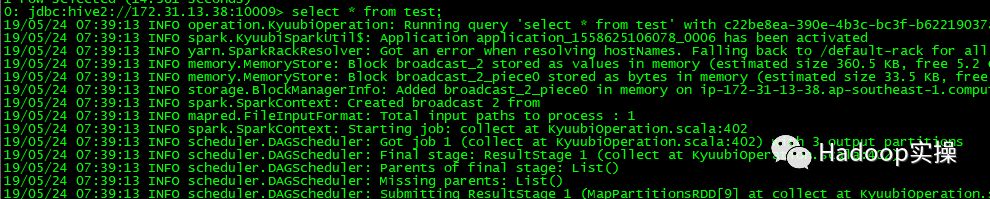

6.从CM的界面上个可以查看Kyuubi在YARN上启动了一个Application Master

7.读取较大数据的textfile的Hive表。

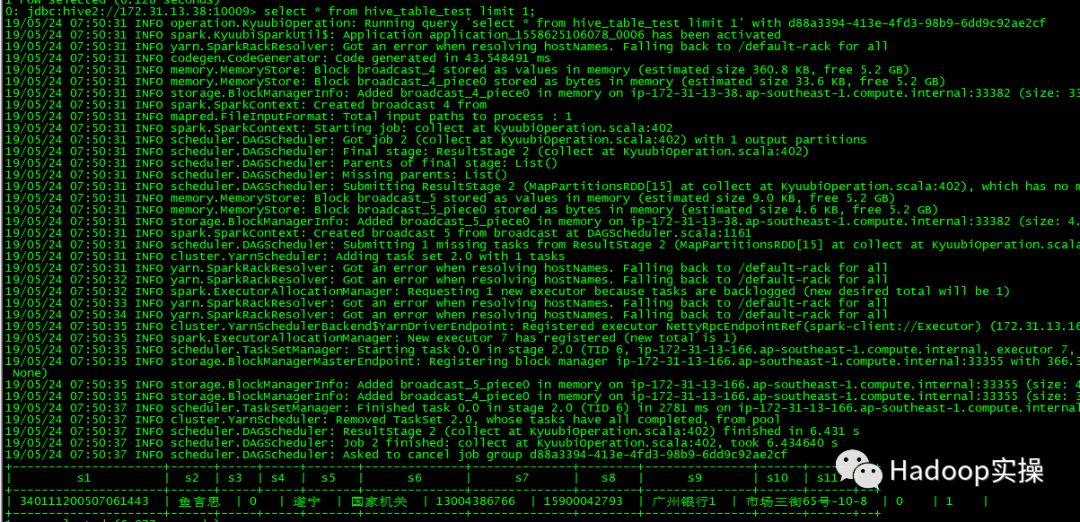
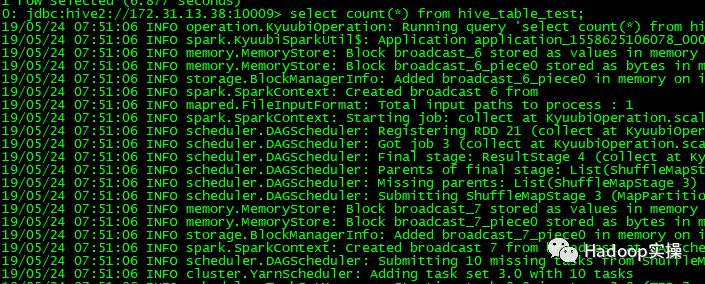
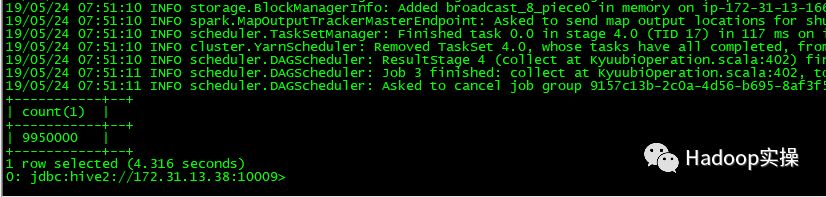
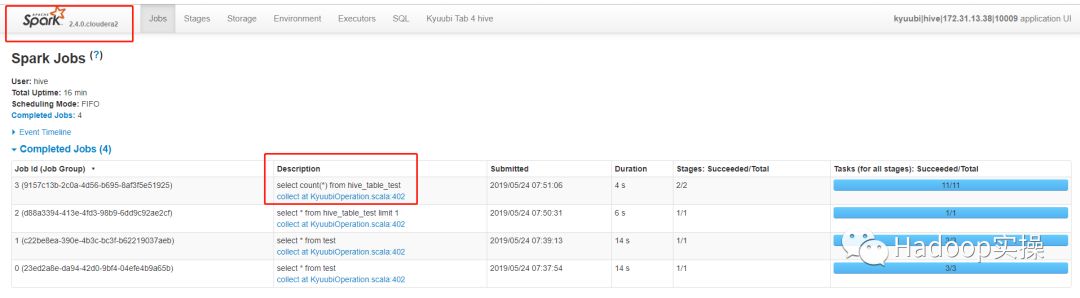
在Spark界面上可以查看到该任务:
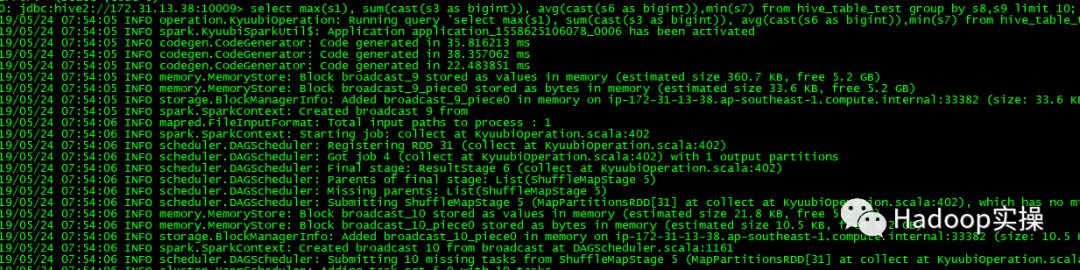
8.执行较为复杂的SQL
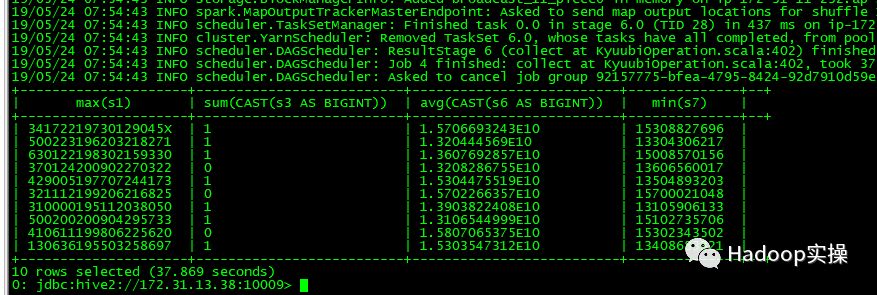
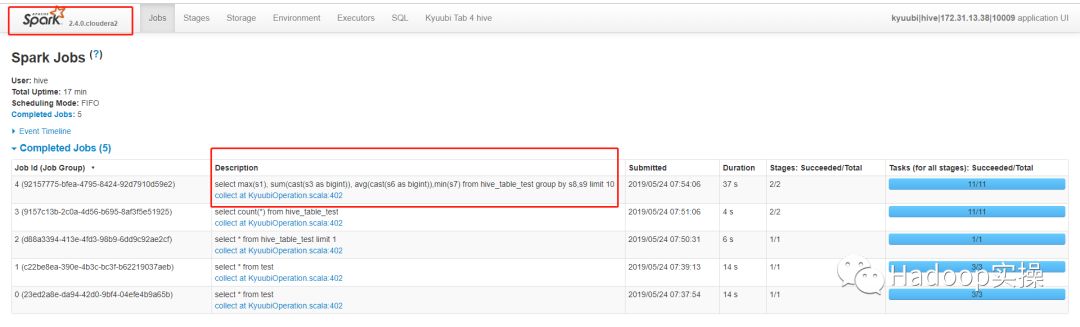
9.读取Parquet表。
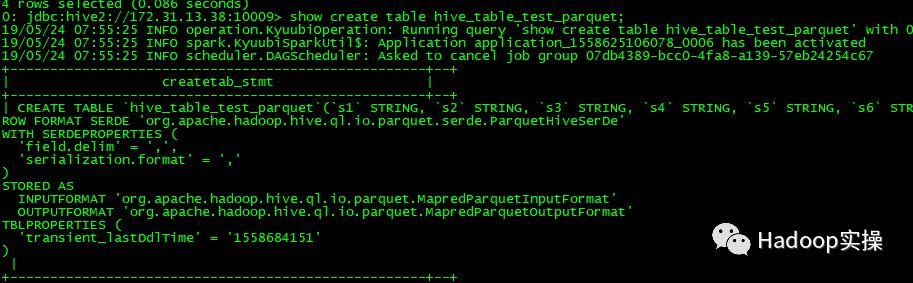
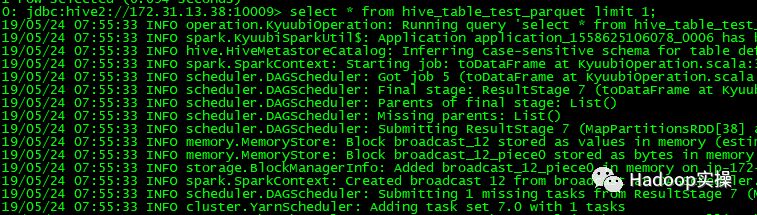


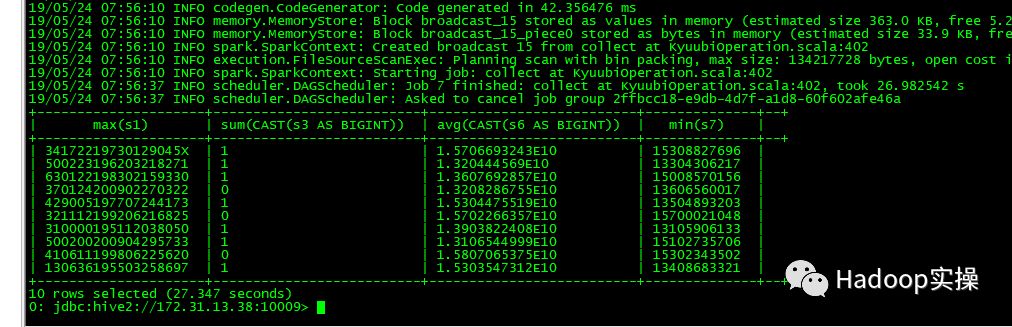
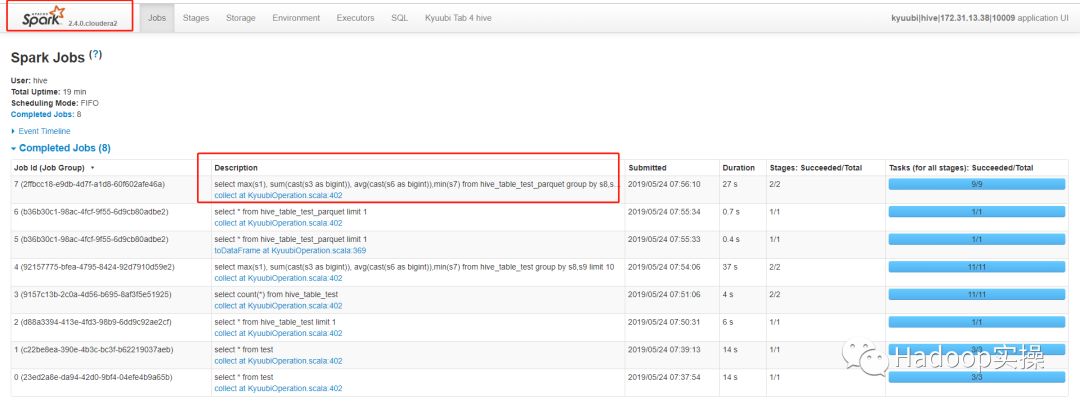
通过以上测试结果可以看到通过beeline可以连接到Spark2.4 Thrift服务,并且执行Spark SQL任务。我们在Hive中创建的文本表或者Parquet表,都能被Spark SQL正常访问,任务执行完毕后,在Spark的界面上也能够正常查看到该任务。自此,Spark2.4 Thrift服务在CDH5.16.1上测试通过。
4
其他问题
1.首次运行Kyuubi服务启动失败。
WARNING: Running kyuubi-daemon.sh from user-defined location.
/opt/cloudera/parcels/SPARK2/lib/spark2/bin/load-spark-env.sh: line 77: /opt/cloudera/parcels/SPARK2-2.4.0.cloudera2-1.cdh5.13.3.p0.1041012/lib/spark2/bin/kyuubi-daemon.sh: No such file or directory
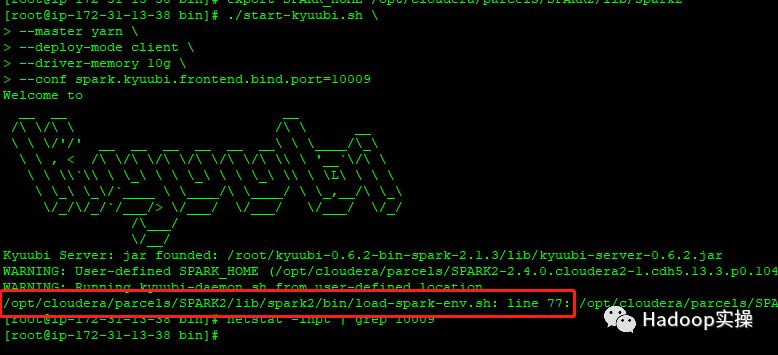
2.注释掉/opt/cloudera/parcels/SPARK2/lib/spark2/bin/load-spark-env.sh中的第77行,保存文件并退出。 。
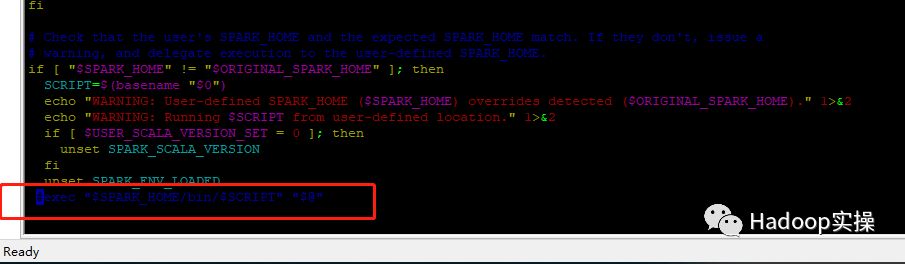
3.再次启动Kyuubi成功。
服务启动成功,端口能正常监听,问题解决。
提示:代码块部分可以左右滑动查看噢
为天地立心,为生民立命,为往圣继绝学,为万世开太平。
温馨提示:如果使用电脑查看图片不清晰,可以使用手机打开文章单击文中的图片放大查看高清原图。
推荐关注Hadoop实操,第一时间,分享更多Hadoop干货,欢迎转发和分享。
以上是关于0644-5.16.1-如何在CDH5中使用Spark2.4 Thrift的主要内容,如果未能解决你的问题,请参考以下文章
如何在使用 HubSpot 跟踪代码的 SPA 中“去识别”用户