技术干货|关于logback日志压缩的那点事
Posted 热云数据
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了技术干货|关于logback日志压缩的那点事相关的知识,希望对你有一定的参考价值。

· 高性能(相比log4j在核心路径上有近10倍的提升,并且内存占用更少)
· 丰富齐全的文档和测试用例(这个对于商业场景其实非常重要)
· 支持自动动态重加载配置文件(不用非得重启应用了哦)
· 可优雅处理IO failure场景(容错性更好)
· 支持基于时间或文件大小等各种策略来删除历史旧日志备份
· 支持对归档日志文件的自动压缩
因为logback配置的关键其实就是appender部分,我们以热云数据某内部服务使用logback组件的真实场景为例,摘录出其中的一个appender定义如下(对敏感数据路径已做脱敏处理):
<appender name="rawdata"
class="ch.qos.logback.core.rolling.RollingFileAppender">
<file>/xxx/rawdata/rawdata.log</file>
<encoder>
<pattern>%m%n</pattern>
</encoder>
<rollingPolicy class="ch.qos.logback.core.rolling.TimeBasedRollingPolicy">
<fileNamePattern>/xxx/rawdata/rawdata.log.%d{yyyy-MM-dd-HH}.gz</fileNamePattern>
</rollingPolicy>
</appender>
可以看到,我们使用了TimeBasedRollingPolicy这个基于时间的切换策略,每到整点时就会自动切换,并且会对切换后的历史归档文件进行gzip压缩处理(注意:logback会根据fileNamePattern里的后缀名来判断,如果是.gz的就会自动做gzip压缩处理,如果是.zip的就会做zip压缩处理)。这样的appender在该内部服务中有十几个,也就是说其实是有十几个不同的日志文件每到整点就做自动切换及自动压缩处理。随着热云数据业务数据规模的不断增长,我们接收的日志条数自然也越来越多,最近几个月,我们可以直观地观测到如下状况:
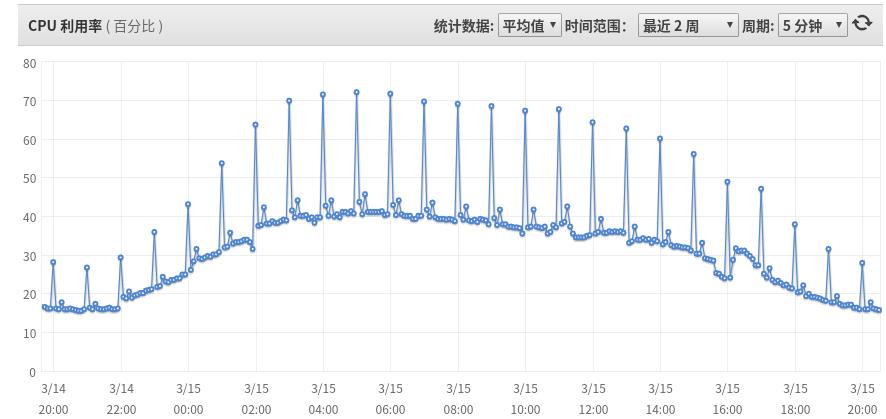
上面是该服务某台线上服务器的CPU使用率监控图(小小说明一下,时区是0不是东8),可以很明显的看到,每到整点时,CPU就会飙升,在业务高峰时段(相应的日志数据量大)CPU会飙升30~35%左右。有经验的开发者一定很容易就想到这会导致很多问题,比如给资源调度和优化成本带来干扰,资源拥挤对正常的业务代码性能也有明显影响性,能抖动进一步会影响整体服务的稳定性,甚至上下流系统的整体服务链路可用性等问题。
比如,我们从某上流系统对该服务的请求平均时延监控看:
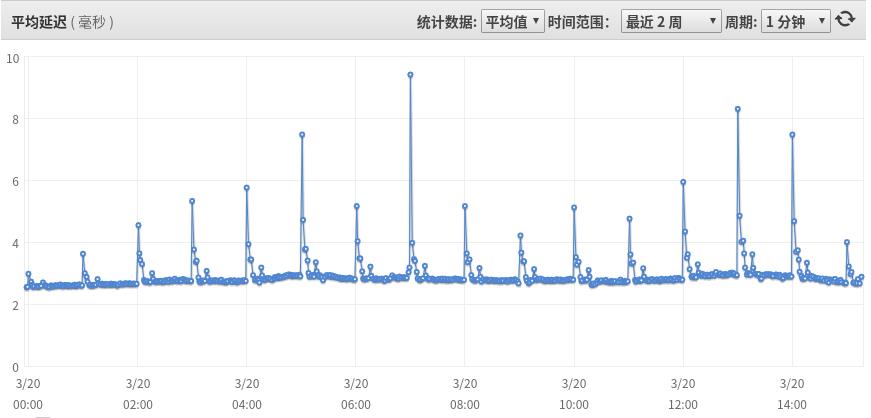
在整点时段,平均时延会从平时的2.x毫秒直接恶化一到两倍,严重的接近10毫秒,这会大大影响整体数据的吞吐和时延技术指标。而且上面还只是平均时延指标,如果拿p95/p99/p99.9等长尾指标观测的话会更加惨不忍睹。
面对这个小问题,我们怎么办呢?当然很容易想到的就是减压,怎么把压缩日志这种纯耗CPU资源的操作干掉,比如我们可以只让logback做日志切换工作,然后再用三方压缩命令来做压缩工作。限于热云数据的2B商业场景,必然需要极高的可靠性,脚本命令可能就得考虑好logback日志切换何时完成,如何控制好压缩并发数,支持压缩率修改等等细节。这样相当于数据整体处理流程中,需要多引入脚本步骤,大家都知道系统每多增加一个环节,稳定性其实就也相应要增加了个监控报警和准备人工干预的预案环节;或者就是把原始的日志文件直接网络传输到其它离线机器做进一步处理,这相当于用网络带宽替换CPU,但如果你从整体IT成本考虑的话,显然这不是一个成本上最优的选择。那么做为一个有着技术理想追求的团队,本着使用一个开源组件,就要至少熟练用好的态度,我们尝试下能不能在logback内就把这个事情解决掉呢?
通过阅读logback代码,我们很容易就能弄明白,整点日志切换的流程大致如下(以logback 1.1分支代码为例):
RollingFileAppender.attemptRollover()→TimeBasedRollingPolicy.rollover()→renameRawAndAsyncCompress()→compressor.asyncCompress(),
其实现为:
public Future<?> asyncCompress(String nameOfFile2Compress, String nameOfCompressedFile,String innerEntryName) throws RolloverFailure {CompressionRunnable runnable = new CompressionRunnable(nameOfFile2Compress,nameOfCompressedFile,innerEntryName);ExecutorService executorService=context.getScheduledExecutorService();Future<?>future=executorService.submit(runnable); return future; }
我们可以看出其实每到整点,就会rename这十几个appender对应的日志文件,然后扔到线程池中异步执行。当我们进一步查看线程池时很惊讶的发现,其大小居然是固定值写死的8:
public static final int SCHEDULED_EXECUTOR_POOL_SIZE = 8;
而我们线上的服务器其实只是4核(热云君为了节省成本也是拼了),并且还混布其它的用户服务进程,那这个配置就当然不合理了。由于logback不支持压缩线程池的可配置化,我们就只好fork出来一个内部版本,将其更改为更适合我们热云数据线上主机环境的值。
同时,一提到压缩,自然就会想到压缩率,我们查阅logback的gzip压缩实现,发现其使用的是jdk自带的GZIPOutputStream类,我想如果是个开发老手一定就会想到翻看jdk源码了,没错,我们进一步就可以了解到jdk自带的这个GZIPOutputStream类,居然是不支持开发者直接修改压缩率的!只暴露出一个默认的压缩率DEFAULT_COMPRESSION供开发者使用。于是我们本着快速试错的原则,先用系统自带的gzip命令行,同过指定-1或-9选项来拿实际线上的日志大文件对比测试,结论就是快速压缩模式,可以用20%的文件体积增长来换取更短的real&user CPU执行时间(只有默认压缩模式的55%左右),原型结果很鼓舞人心,于是我们就想办法实现吧。
首先我们可以在logback工程代码里添加个自定义的类实现:
public class ReyunGZIPOutputStream extends GZIPOutputStream {…public void setLevel(int level) {def.setLevel(level);}}
通过这种方法我们就可以对jdk中隐藏不暴露出来的Deflater自定义压缩级别了,比如setLevel(Deflater.BEST_SPEED);
那么我们看看logback经过修改压缩率和线程池后的表现吧。
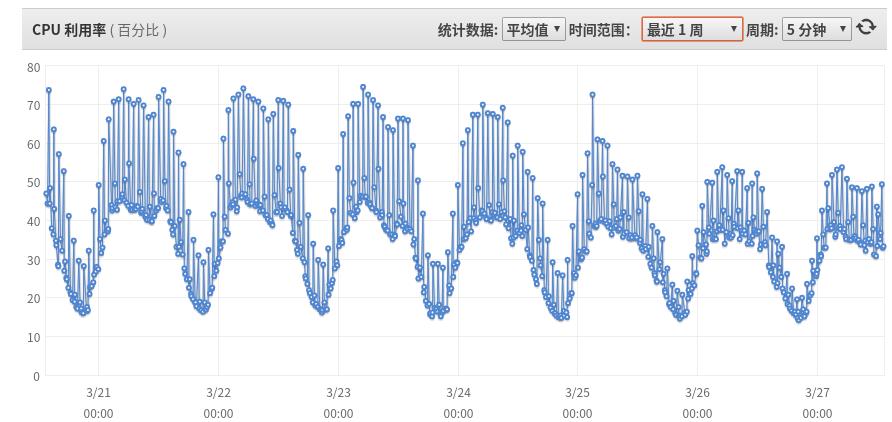
上图是某个主机上线完修改后热云数据logback内部版本的CPU使用率监控图,可以看到CPU spike明显好转,原来的40%忽升到70%+ 变成了50%+,这意味着集群扩容可以推迟到比原来多20%的流量,我们再来看看上流系统的请求平均时延吧:
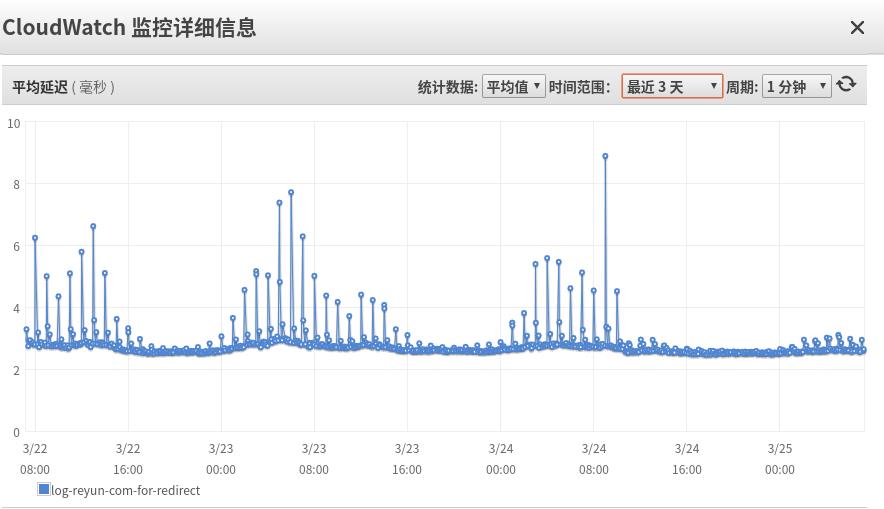
可以看到请求毛刺基本没有了,抖动明显改善了,世界顿时美好了不少。
那么这就完了么?其实还可以继续的,比如目前是整点切换及压缩,大家想像一下如果面对的是一个大集群,流量高峰期,所有节点在整点统一切换统一压缩,如果前面的LB负载均衡正常的话,其实每个节点的日志文件大小是类似的,那就相当于每到整点节点集体一起“抽风跳舞”,尽管我们通过限制并发数,修改压缩率已经尽可能平滑CPU使用了,但我们依然可以更进一步优化。比如在thread pool执行压缩任务前加个随机jitter,sleep random秒,让每个节点压缩启动、执行时机不再精准统一,站在整个集群的角度看是不是更美好了?:)甚至我们可以进一步修改jdk线程池的队列实现,不再先进先出,而是随机poll出来个任务(对应我们的日志文件压缩顺序随机化),那集群的整体吞吐和时延抖动就能更平滑化了。
我们做为开源软件的使用者,如果能发现问题,回馈问题才是一个更合理的正循环生态做法,所以我们也创建了相应的logback jira,如果感兴趣欢迎watch参与讨论和review patch,附上jira链接:https://jira.qos.ch/browse/LOGBACK-1512 。我们会经过与社区开发人员讨论,确认接纳我们的想法后,把相应热云数据内部patch贡献回开源社区,方便有类似困扰的logback用户能更好的使用它。
以上就是我们最近几天的一个微不足道但有点趣味的尝试,限于作者认知有限,如有疏漏,请不吝赐教指正,多谢。后面我们技术团队也会抽时间不断分享更多更有趣的技术文章,欢迎大家一起探讨学习,共同进步。

以上是关于技术干货|关于logback日志压缩的那点事的主要内容,如果未能解决你的问题,请参考以下文章