吕健|Microservices 场景下的持续部署 Posted 2021-04-24 中生代技术
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了吕健|Microservices 场景下的持续部署相关的知识,希望对你有一定的参考价值。
内容简介
近两年作者在海外交付中参与
microservices
下的团队,为客户提升
Finance
系统的扩展性。
作者所在团队,3
对开发(pair
programming,
2
个
dev
为
pair)为客户支撑着
11
个
services,持续部署流水线(CD
pipeline)是其中必不可少的一个技术实践。本次分享作者将从实践的角度分享
microservices
架构下的持续部署(CD)。
内容概述
1. microservice
概述:简要介绍
microservice
架构下的挑战
2. 持续部署实践:这里会提到『Build
Pipeline
as
Code』,『Infrastructure
as
Code』等概念。
3. 持续部署了之后呢?
这里会介绍
CD
结合团队的敏捷开发流程的实践经验。
microservices 概述
当提到
microservice
的时候,我们通常会从下图开始:
为了从业务和技术方面得到更好的扩展能力,我们将单一架构的系统(Monolithic
architecture),拆分成若干的微服务(Microservices
architecture),这种拆分是架构演进的一个过程。
在整个拆分过程中,对团队的组织架构,数据的管理方式,部署监控技术方面都带来极大的挑战。
持续部署(简称
CD)是
microservices
架构中一个必备的实践之一。本文将介绍基于Docker
的
CD
方式。
部署方面带来的挑战
单一架构下(Monolithic),我们的系统
Code
base
可以在一个项目中,这个系统采用一个持续集成(简称:CI)
pipeline,并且此时我们也可以采用持续集成(简称:CD)pipeline,最终将系统持续部署到生产环境中。
在这种情况下,每当系统引入一个改变的时候,CI,CD
pipe
line
都会执行一次。例如:
- 10
mins
Unit
Test
- 2
hours
Acceptance
Test
- 15
mins
package
- 20
mins
deployment
上面列举的例子并不算坏,更庞大的系统可能会需要更多的时间。
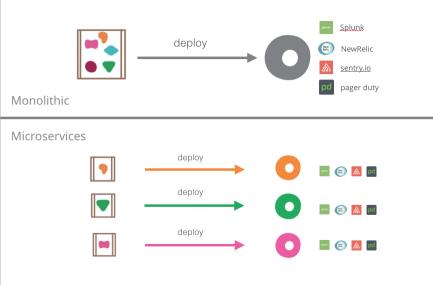
当我们将
Monolithic
系统拆分成多个
micro
services
时,并且将每个
services
进行独立部署。每当系统引入一个改变的时候(code
change),它只会影响个别
service,我们只需要部署发生改变的部署,从新运行一个
service
的
CI,CD
pipeline:
- 1
mins
Unit
Test
- 1
mins
Integration
test
- 5
mins
package
- 5
mins
deployment
这种拆分之后,更符合我们对解耦的追求:
『当代码引入一个改变的时候,它应该影响的改动最小』
此时所提到的改变涉及整个开发流程,从代码到部署的影响做到了最小。
拆分
services
之后的代价是,每个
service
都需要独立部署,我们需要为每个
service
搭建
CD
pipeline。
在
microservices
场景下,不同的
service
按照需求可能会采用不同的技术栈。并且在每次新建
service
时,配套的日志,监控,报警系统也需要进行配置。
这个对
CD
提出了很大的挑战。
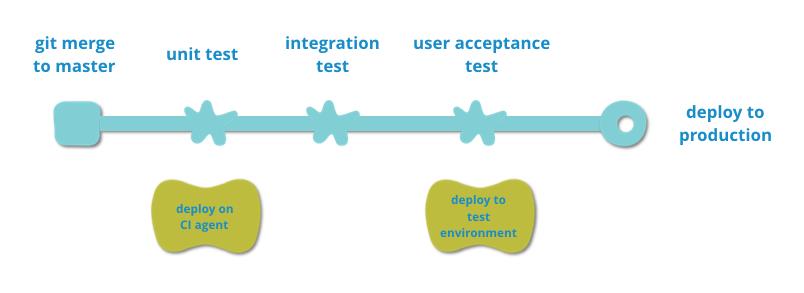
持续部署方面的实践
当我们谈持续部署的时候,此时也会包括持续集成。持续部署的整个过程会从代码
push
到
master
开始:
我们采用
Docker
来解决技术栈差异的问题,DevOps
创建部署工具将部署,监控,报警等配置模板化。
实践:
- 使用
Docker
构建和发布
service
- 采用
Docker
Compose
运行测试
- 使用
Docker
进行部署
准则:
- Build
pipe
line
as
Code
- Infrastructure
as
Code(base
on
AWS)
- 共享构建脚本
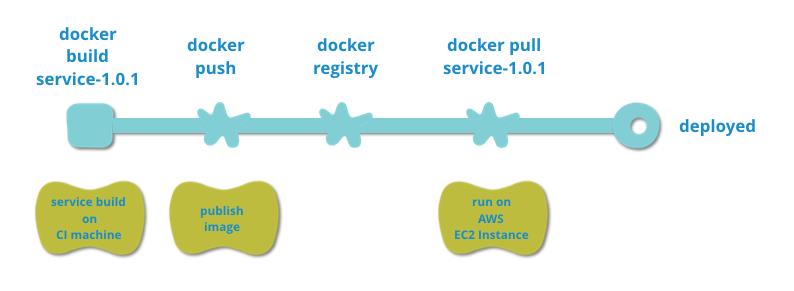
使用
Docker
构建和发布
service
- 使用
Docker
构建
service,service
已
docker
image
的方式发布
- 将
docker
发布到
docker
registry
- 从
docker
registry
上
pull
docker
image
进行部署
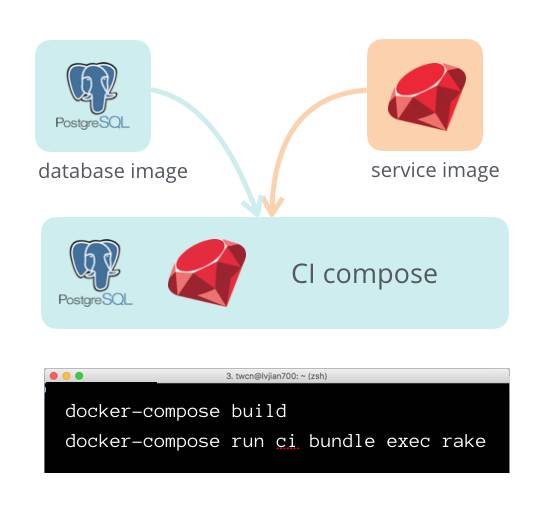
使用
Docker
Compose
运行测试
可以将多个
docker
image
进行组合。有些
service
需要访问数据,我们可以通过
docker
compose
将
service
image
和
database
image
组合在一起。
组合之后,我们可以采用
docker
compose
运行持续集成。
下面这个实例展示如何进行这种组合:
Build
pipeline
as
Code
通常我们使用
或者
来搭建
CI/CD
pipeline,每次创建
pipeline
需要进行大量的手工配置,此时很难自动化
CI
服务器配置。
Build
pipeline
as
Code,即使用代码来描述
pipeline,这样做可以带来非常好的可读性和重用性。我们可以很容易的做到
CI
服务器配置。
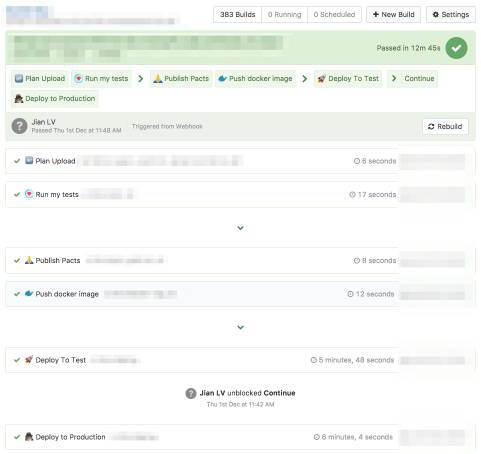
今年团队将所有
pipeline
从
Bamboo
迁移到了
。在
BuildKite
上可以使用如下代码描述上图的
pipeline:
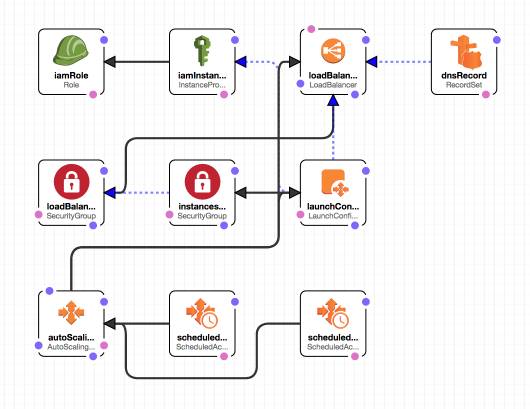
Infrastructure
as
Code
如果我们要发布一个基于
HTTP
协议的
REST-ful
API
service,我们需要
service
准备如下基础设施(Infrastructure):
- 可部署的机器
- 机器的
IP
和网络配置
- 设备硬件监控服务(GPU,Memory
等)
- 负载均衡(Load
Balancer)
- DNS
- AutoScaling
(services
自动伸缩服务)
- Splunk
日志收集
- NewRelic
性能监控
- Sentry.io
和
PagerDuty
报警
这些基础设施的搭建和配置我们希望将其模板化,自动化。我们才用代码描述基础设施,DevOps
提供工具模板化基础设施的描述。
实践:
- 采用
AWS
云服务进行部署
- 采用
AWS
CloudFormation
描述和创建资源
- 将对资源操作的脚本进行
source
control
准则:
- 对资源的描述和操作应该在
git
中
- 在所有环境中采用相同的部署流程
- 使用
ssh
等手动操作资源的方式,只能用于测试环境和做一些
debug。
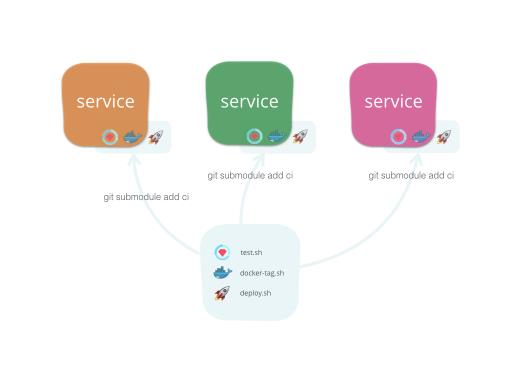
共享构建脚本
在为多个
services
搭建
CD
pipeline
之后,我们将
CD
pipeline
归纳为三部:
1. 运行测试
2. 构建发布
docker
image
3. 部署
分别为这三步提取出
shell
scripts:
1. test.sh
2. docker-tag.sh
3. deploy
<test|prod>
之后为上述脚本创建
git
repository,并且将其以
git
submodule
的方式引入各个项目。
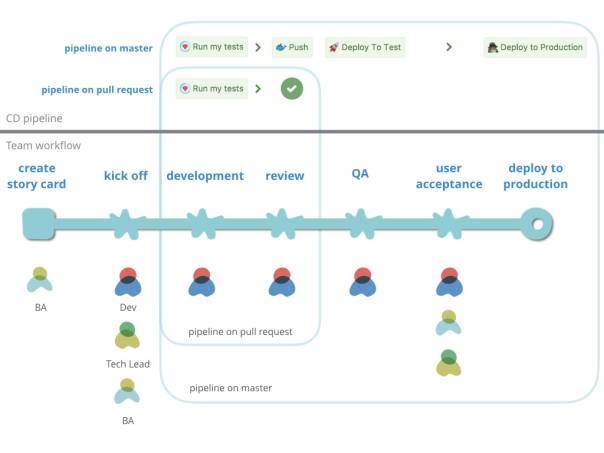
持续部署了之后呢?
让
CD
pipeline
服务团队的工作流程
我们搭建好
CD
pipeline,需要让它在团队的敏捷开发流程中发挥为威力:
团队职责:
- 团队主要分为
BA,Developer(简称
Dev),Tech
Lead(简称TL)
- BA
负责分析业务,并在故事墙上创建
Story
- Dev
负责开发,QA,运维(跨能型团队)
- Tech
Lead
负责技术
工作流程:
1. Dev
从
Backlog
中拿卡进行分析,分析完成后跟
BA,TL一起
kickoff
确定需求、技术实现。
2. kickoff
之后,
Dev
在
repository
上创建
Pull
Request(简称
PR)
开始工作。此时在
PR
上的每一次
git
push
会触发
PR
的
pipeline,此时在
CI
机器上只会运行单元测试和集成测试。
3. Dev
开发完成后,其他
Dev
对
PR
进行
Review,Review
通过之后将
PR
merge
到
master
分支,此时会
trigger
master
分支上的
pipeline,将最新代码自动部署到
test
环境。
4. 部署
test
环境成功后,Dev
基于
test
环境进行
QA。
5. QA
完成后向
BA,
TL
做
showcase
进行
user
acceptance
test。
6. 通过
user
acceptance
test
之后,在
BuildKite
上点击部署到
production
按钮完成发布。
按照以上流程,团队可以快速从
CI/CD
pipeline
上得到反馈,高度自动化的
CD
pipeline
可以让团队做到按照
Story
进行
service
发布。
Summary
Microsservices
在业务和技术的扩展性方面带来了极大的便利,同时在组织和技术层面带来的极大的挑战。
由于在架构的演进过程中,会有很多新服务产生,持续部署是技术层面的挑战之一,追求极致的自动化,可以让团队从基础设施抽离出来,关注与产生业务价值的功能实现。
Q&A
Q1:你们的docker是用什么来管理的?k8s,swarm
还是其他什么?
A1:
K8S,
Swarm
都没使用,对这两个服务我也只是听说过。
每个独立的
service
Docker
image
会单独运行在
AWS
EC
2
Instance。管理一般也都是围绕
EC
2
Instance
来做。关于
Docker
Images
仓库,采用自建的
Docker
Registry
服务来
push
和
pull
docker
image。
================
Q2:如何做跨语言的服务集成
A2:
我们做过
Ruby
和
Node.js
的集成。服务器间通信采用
HTTP
协议,JSON
作为传输格式,
JSON
基于
hyper
media
link
的实现之一
HAL
。
如何解决
service
之间的约定,我们采用
Consumer
Driven
Contract
的方式,使用单元测试代替集成测试,这部分实现采用
Pact
。
================
Q3:service的粒度如何确定
A3:
这是一个非常好的问题,也是很难回答的问题。
我个人觉得
microservices
中最难回答的两个问题是:
1.
什么拆分出一个
service?
2.
怎么拆分?(也就是拆分多细,系统边界如何确定)
service
粒度如何确定,一句话来回答(TL;DR):『采用领域驱动设计(DDD)的方式拆分』。
更长版本,我们项目是为客户解决已运行10年以上财务生态系统的拆分问题。也就是老系统改造,也是我觉得最适合实施
micro
services
的场景。老系统存在很多痛点,并且需求较为稳定。
那么如何拆:
1.
需要引入业务专家,技术专家,相关利益人一起分析业务场景,系统构成确定领域语言对业务进行建模。
2.
将以前以业务切分系统的思路转为按照数据模型切分的思路。
3.
每个类数据模型可以划分多种子模型来辅助主数据模型。
4.
service
的粒度一般以数据模型的粒度来确认。
还有一些按照非功能性需求来切分的原则,比如实施
CQRS
的时候,将读写拆成两部分,采用
Even
Sourcing
解决分布式系统数据状态同步的问题。
================
Q4:为什么没有考虑gocd,gocd可是first
class的CI/CD工具
A4:
好问题,这个我需要找
ThoughtWorks
负责
GoCD
的同时聊聊销售问题。BTW,我个人还没机会使用过
GoCD
================
Q5:目前发现从esb
soa转microservice,原本进程内的调用关系变成了网络调用,一次rpc变成了几次或者几十次rpc,同等条件下性能损失严重。这个问题如何得到解决?
A5:
好问题,性能问题也是被同事问得最多的问题。关于性能问题我没遇见过高并发的场景,当时对于降低
services
依赖,控制网络请求我们是有一些解决方案。
1.
所有
services
基本都部署在同一个网络,比如
AWS
的网络上,可以讲起想想成内部局网,HTTP
call
带来的性能损耗目前为止还算可以接受。
2.
从系统设计的角度讲,与其降低HTTP请求的消耗时间,不如减少HTTP
请求的发送次数。从系统设计上考虑,大部数据模型都是
immutable
(不可变得),在系统系统间我们将数据缓存,减少
HTTP
请求的次数。(全文完)
扩展阅读
以上是关于吕健|Microservices 场景下的持续部署的主要内容,如果未能解决你的问题,请参考以下文章
持续部署Microservices的实践和准则
微服务架构(Microservices Architecture)介绍
基于Docker环境下的Jenkins搭建及使用
State of the Art in Microservices
负载均衡续:万亿流量场景下的负载均衡实践
自动化运维|云原生架构下的产品自动化发布快速部署和持续交付实战之路