自动化运维|云原生架构下的产品自动化发布快速部署和持续交付实战之路
Posted 代码讲故事
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了自动化运维|云原生架构下的产品自动化发布快速部署和持续交付实战之路相关的知识,希望对你有一定的参考价值。
自动化运维|云原生架构下的产品自动化发布、快速部署和持续交付实战之路。
1.背景介绍
CI/CD是一种通过在应用开发阶段引入自动化来频繁向客户交付应用的方法。CI/CD 的核心概念是持续集成、持续交付和持续部署。作为一种面向开发和运维团队的解决方案,CI/CD 主要针对在集成新代码时所引发的问题(亦称:“集成地狱”)。CI/CD创建了一个可重复的、可靠的且可预见的发布流程,从而大大缩短了发布周期,不仅节省下了巨大的金钱成本,还节省了包括建立和维护这样一个发布系统所需要的时间投入。
在引入CI/CD技术之前,公司测试人员自动化打包主要依赖Jenkins实现,在配置任务的源码、构建触发器、构建环境、构建、构建后操作等步骤后,可以触发构建任务。相比传统的拉代码、运行命令打包、整理上传更新文件,重启服务等繁琐的操作,Jenkins任务构建这种方式在一定程度上节省了测试和研发人员的时间。但随着代码仓库数量的日益增长,以及Jenkins在公司内部使用程度越来越深,一些问题也逐渐暴露。例如:
每一套代码或服务都需要繁琐的job配置工作,且大部分是重复劳动。
研发人员和测试人员都在使用Jenkins,需要一定的学习成本。
缺少打包结果通知,不能及时获取打包结果。
构建完成后需要手动下载归档文件,并整理后创建更新任务。
公用测试环境,频繁更新重启服务(特别是封版期间)导致服务中断的问题。
为了解决以上问题,我们使用了Kubernetes 原生 CI/CD 构建框架Tekton和基于Kubernetes的声明式持续交付工具Argo CD,并将流水线接入项目管理平台Redmine,简化了代码打包步骤、降低了使用人员的学习成本、提供稳定的测试环境、自动粘贴归档文件下载链接、自动创建更新任务等,进一步提高了持续集成的效率。
- 系统设计
流水线系统设计以项目管理平台为入口,Kubernetes为环境基础,使用Tekton完成CI部分功能,在构建完成后更新服务编排文件。Argo CD则负责持续监控应用状态,并更新应用。
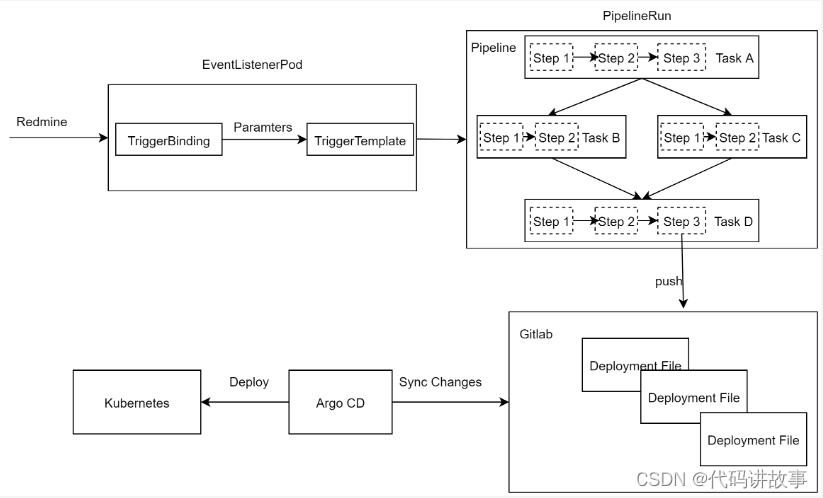
2.1Kubernetes简介
Kubernetes是一个开源的,用于管理云平台中多个主机上的容器化的应用,Kubernetes的目标是让部署容器化的应用简单并且高效(powerful),Kubernetes提供了应用部署、规划、更新、维护的一种机制。
Kubernetes一个核心的特点就是能够自主的管理容器来保证云平台中的容器按照用户的期望状态运行着(比如用户想让apache一直运行,用户不需要关心怎么去做,Kubernetes会自动去监控,然后去重启,新建,总之,让apache一直提供服务),管理员可以加载一个微型服务,让规划器来找到合适的位置,同时,Kubernetes也系统提升工具以及人性化方面,让用户能够方便的部署自己的应用(就像canary deployments)。
2.2Tekton简介
Tekton 是一个基于 Kubernetes 的云原生 CI/CD 开源框架,属于 CD 基金会的项目之一。Tekton 通过定义 CRD 的方式,让用户以灵活的自定义流水线以满足自身 CI/CD 需求。
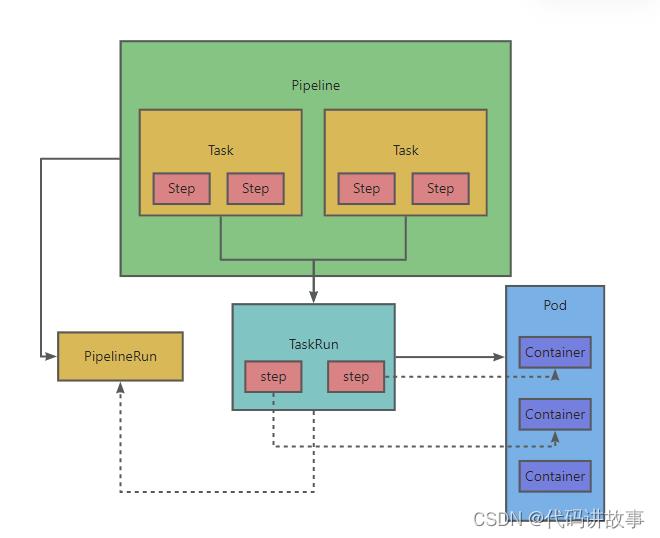
Tekton 最主要的四个概念为:Task、TaskRun、Pipeline 以及 PipelineRun。
Task: Task 为构建任务,是 Tekton 中不可分割的最小单位,正如同 Pod 在 Kubernetes 中的概念一样。在 Task 中,可以有多个 Step,每个 Step 由一个 Container 来执行。
Pipeline: Pipeline 由一个或多个 Task 组成。在 Pipeline 中,用户可以定义这些 Task 的执行顺序以及依赖关系来组成 DAG(有向无环图)。
PipelineRun: PipelineRun 是 Pipeline 的实际执行产物,当用户定义好 Pipeline 后,可以通过创建 PipelineRun 的方式来执行流水线,并生成一条流水线记录。
TaskRun: PipelineRun 被创建出来后,会对应 Pipeline 里面的 Task 创建各自的 TaskRun。一个 TaskRun 控制一个 Pod,Task 中的 Step 对应 Pod 中的 Container。当然,TaskRun 也可以单独被创建。
综上:Pipeline 由多个 Task 组成,每次执行对应生成一条 PipelineRun,其控制的 TaskRun 将创建实际运行的 Pod。
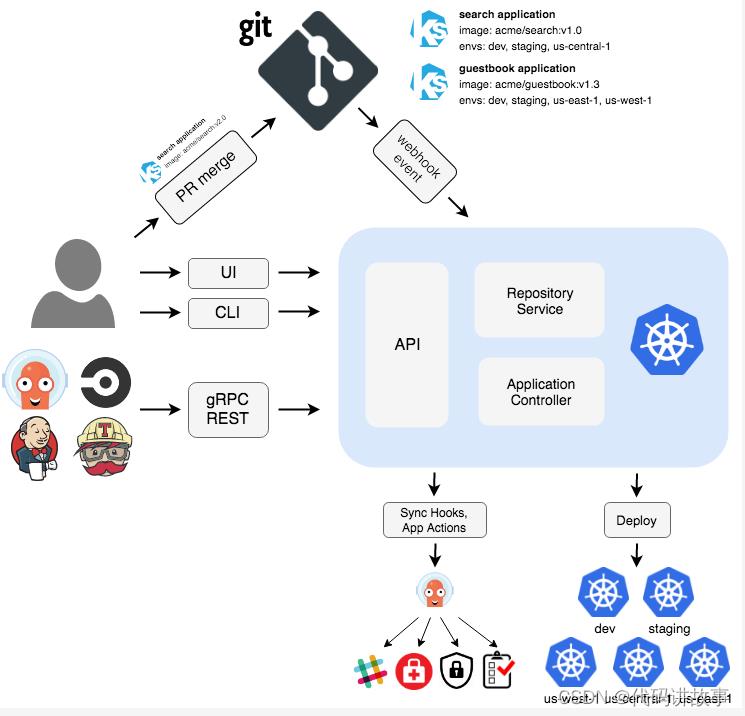
2.3Argo CD 简介
Argo CD 是一个为 Kubernetes 而生的,遵循声明式 GitOps 理念的持续部署(CD)工具,它的配置和使用非常简单,并且自带一个简单易用的 Dashboard 页面,并且支持多种配置管理/模板工具(例如 Kustomize、Helm、Ksonnet、Jsonnet、plain-YAML)。
Argo CD 被实现为一个 Kubernetes 控制器,它持续监控应用的实际状态,周期性地拉取 Git 仓库中的配置清单,并将实际状态与期望状态进行比较,如果实际状态不符合期望状态,就会更新应用的实际状态以匹配期望状态。
Argo CD的主要功能:
可搭配使用各种配置管理工具(如 ksonnet/jsonnet、Helm 和 kustomize)使应用程序与 Git 中定义的保持一致。
将应用程序自动部署到指定的目标环境。
持续监控已部署的应用程序。
基于 Web 和 CLI 的操作,以及应用程序可视化。
部署或回滚到 Git 仓库中提交的应用程序的任何状态(这也是使用 Git 进行版本管理的一大好处。
2.4项目管理平台Redmine
政通项目管理平台是流水线使用的入口系统,在同步保存Gitlab仓库、分支、CI/CD参数后,新增流水线任务时将参数传给Tekton。流水线任务执行时,会将当前流水线信息推送到项目管理平台。
流水线打包成功后会将归档路径推送到项目管理平台。

新增流水线时如果勾选了创建更新任务,也会在流水线打包成功后自动创建更新任务。
新增流水线时选择运行测试环境,则会通过Argo CD更新测试服务。
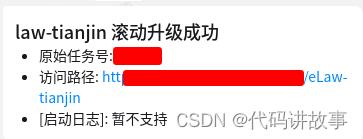
流水线运行异常时,会将相关信息推送到项目管理平台,方便排查问题。

- 流水线的使用
下面以wizdom-urban-v14代码为例,介绍流水线打包如何使用。
(1)步骤一:Gitlab参数配置。
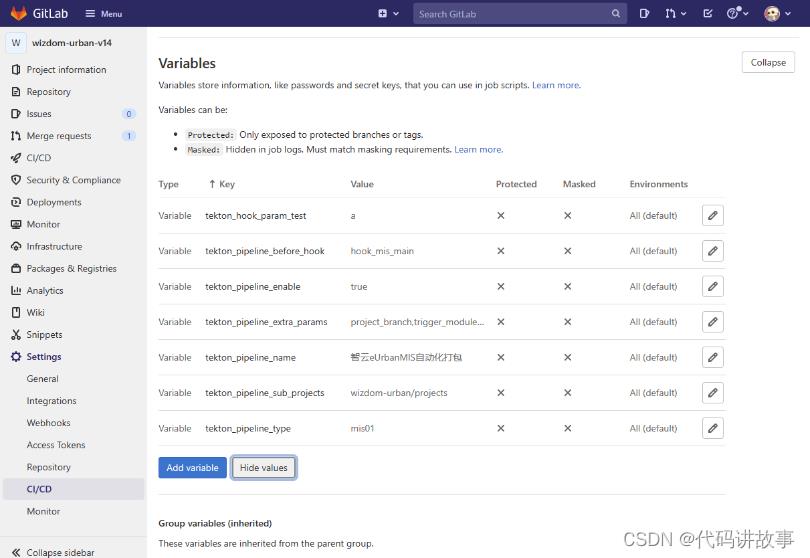
tekton_pipeline_enable:是否启用流水线,如true。
tekton_pipeline_name:流水线名称,如“执法-vue前端”。
tekton_pipeline_extra_params:新增流水线页面额外显示的参数,多个参数逗号分隔。可选值:npm_build_params(插件名)。
tekton_pipeline_before_hook:仅用于多app前端仓库,提交记录中src/pages/后面一级目录作为打包参数。如:hook_plugins_by_src_pages、hook_plugins_by_src_views。流水线构建中如果需要使用更多参数,可以配置以“tekton_hook_param_”为前缀的参数名,流水线任务预处理会判断并截取这样的参数。
(2)步骤二:Redmine同步配置管理–项目管理–gitlab同步,同步仓库、分支、变量。代码仓库会在代码提交后自动同步。变量只需要在修改后同步1次即可。
(3)步骤三:新增提测单项目管理平台任务处理完成以后,点击任务右上角“生成提测”功能按钮,从列出的根据提交记录查询的代码仓库和分支列表中,选择需要使用的流水线打包的代码仓库和分支。

(4)步骤四:新增流水线。以上步骤完成后,就来到了最关键最常用的新增流水线环节,在任务界面点击右上角“新增流水线”功能按钮,填写相关信息。
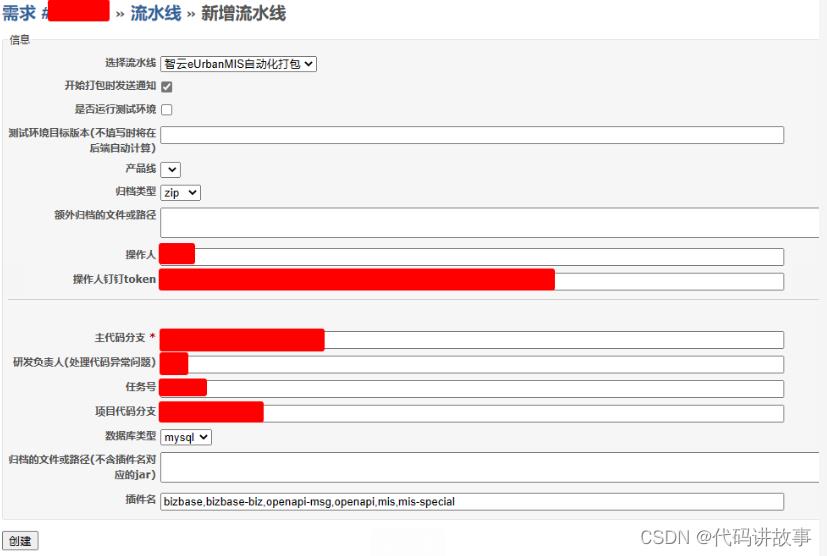
后台会根据提测单自动填充部分内容,如有调整,可手动修改。
参数说明如下:
选择流水线:根据提测单代码仓库自动选择流水线类型。
开始打包时发送通知:根据钉钉token给测试人员(成功或失败时)和对应的开发人员发送通知(失败时),一般默认都勾选。
是否生成更新任务:用于生成当前任务的子系统,提供给测试人员发更新使用。面向研发人员是隐藏状态。任务名称和内容自动生成,可以自行编辑。
是否运行测试环境:用于自动更新测试环境,默认不勾选,测试人员需要时勾选,结合“产品线”来判断更新哪一套环境。
测试环境目标版本(不填写时将在后端自动计算):运行测试环境的目标版本。
产品线:勾选运行测试环境后生效,用来判断更新哪一套测试环境。
归档类型:默认zip主代码分支:根据提测单自动生成。
项目代码分支:根据提测单自动生成。
数据库类型:默认为mysql。如果有oracle和dm时自行切换。
插件名:根据提测单自动生成,也可以手动填写,以逗号分隔。
归档的文件和路径(不含插件名对应的jar):主要是前端的文件,多个以逗号分隔。根据提测单自动生成,也可以手动修改。
额外归档的文件或路径:填写其他还需要打包时包含的文件或路径,多个以逗号分隔。
操作人:当前操作人,自动生成。
操作人钉钉token:当前操作人的钉钉token,自动生成,用来发送消息通知。
研发负责人(处理代码异常问题):根据“实际研发处理人”自动生成。为空时不显示此项。在流水线因代码问题打包失败时通知研发负责人。
大部分参数都不需要手动填写,只需要确认无误后点击创建,流水线任务即创建成功,等待流水线自动打包完成即可。打包完成或者因代码问题打包失败会通知操作人。
- 流水线任务处理流程
我们从流水线的任务处理流程、流水线任务和步骤来说明流水线中的关键技术。
4.1任务接收
流水线任务是通过TektonTrigger接收的,Tekton Trigger是Tekton的一个组件,它可以从各种来源的事件中检测并提取需要信息,然后根据这些信息来运行TaskRun和PipelineRun,还可以将提取出来的信息传递给它们以满足不同的运行要求。其核心组件如下:
EventListener:事件监听器,是外部事件的入口 ,通常需要通过HTTP方式暴露,以便于外部事件推送,例如项目管理平台的新建流水线操作。
Trigger:指定当EventListener检测到事件发生时会发生什么,它会定义TriggerBinding、TriggerTemplate以及可选的Interceptor。
TriggerTemplate:用于模板化资源,根据传入的参数实例化Tekton对象资源,比如TaskRun、PipelineRun等。
TriggerBinding:用于捕获事件中的字段并将其存储为参数,然后会将参数传递给TriggerTemplate。
ClusterTriggerBinding:和TriggerBinding相似,用于提取事件字段,不过它是集群级别的对象。
Interceptor:拦截器,在TriggerBinding之前运行,用于负载过滤、验证、转换等处理,只有通过拦截器的数据才会传递给TriggerBinding。

Tekton Trigger在接收Redmine提交的流水线请求时,使用Interceptor验证请求、解析参数,包含了新增流水线请求RequestBody的值和根据代码仓库id查询的Gitlab代码仓库的CI/CD参数,根据参数值启动对应的PipelineRun,如智信h5打包的build-mobile-h5或build-mobile-h5-npm。
4.2任务执行
PipelineRun通过pipelineRef指定要运行的Pipeline,Pipeline中定义了多个Task,每个Task又包含一个或多个Step。 以wizdom-urban-v14代码的流水线为例,主要Task及其执行顺序如下:
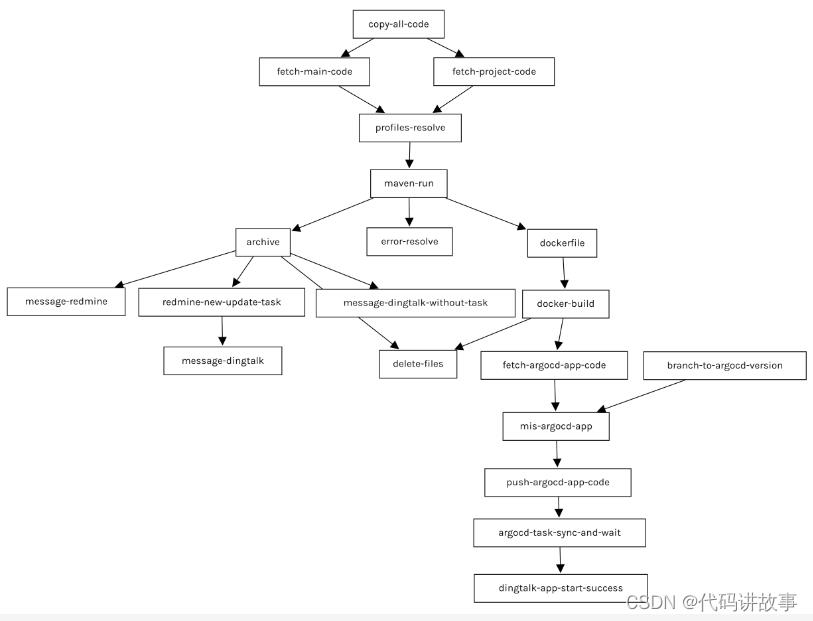
copy-all-code:复制缓存的代码。
fetch-main-code:拉取主代码。
fetch-project-code:拉取项目定制代码。
profiles-resolve:解决profile定义问题,包括合并主框架代码和项目定制代码、解析要打包的profile、解决依赖定义问题。
maven-run:运行打包。
archive:打包结果归档。
dockerfile:处理war打包结构,生成DockerFile内容
docker-build:构建docker镜像,并将镜像推送到镜像仓库
fetch-argocd-app-code:拉取Argo CD配置文件代码仓库
branch-to-argocd-version:更新部署文件的镜像版本
mis-argocd-app:
push-argocd-app-code:将修改后的代码提交推送到Gitlab仓库。
argocd-task-sync-and-wait:触发Argo CD同步,并等待验证服务启动成功。
dingtalk-app-start-success:通知服务更新成功。
redmine-new-update-task:项目管理平台新建更新更新任务。
delete-files:删除临时文件。
message-dingtalk:构建结果通知钉钉通知。
message-dingtalk-without-task: 构建结果通知钉钉通知。
message-redmine:打包成功的推送redmine。
除了以上流水线打包的任务外,还在finally部分指定了多个最终任务(finally task),无论Tasks部分声明的常规任务执行成功还是报错,最终任务都会在常规任务执行完成后并行执行。

set-pipeline-run-status:更新项目管理平台任务状态。
notify-admin-onerror:固定错误通知管理员。
notify-pom-group-onerror:mvn打包失败发送给pom修正群。
notify-dev-onerror:mvn打包失败发送给研发通知。
redmine-comment-onerror:带有任务号的流水线推送打包错误内容到任务上。
redmine-comment-on-mvnerror:打包错误内容推送到任务上。
message-op-user-on-npmerror:打包错误内容消息给操作人。
message-op-user:消息通知操作人。
任务的执行顺序是根据runAfter来决定的,未声明runAfter的任务可以和其他任务并行执行。另外,只有when中声明的条件都满足时任务才会执行,否则会跳过。例如redmine-new-update-task任务,需要等待归档任务(archive)完成后才可能执行,并且只有当项目管理平台任务号不为空,且创建流水线任务时勾选了创建更新任务,才会在归档后创建项目管理平台更新任务。
name: redmine-new-update-task
retries: 1
taskRef:
name: redmine
runAfter:
- archive
when:
- input: "$(params.issue_id)"
operator: notin
values: [ "" ]
- input: "$(params.new_update_issue_flag)"
operator: in
values: [ "true" ]
4.3典型任务和步骤
Pipeline中的任务虽然看起来非常多,但是大部分是可复用的。另外,与Pipeline中声明的任务不同,Task中声明的步骤(step)是按照声明的顺序依次执行的。我们以典型的任务profiles-resolve为例来说明,任务步骤执行顺序如下:
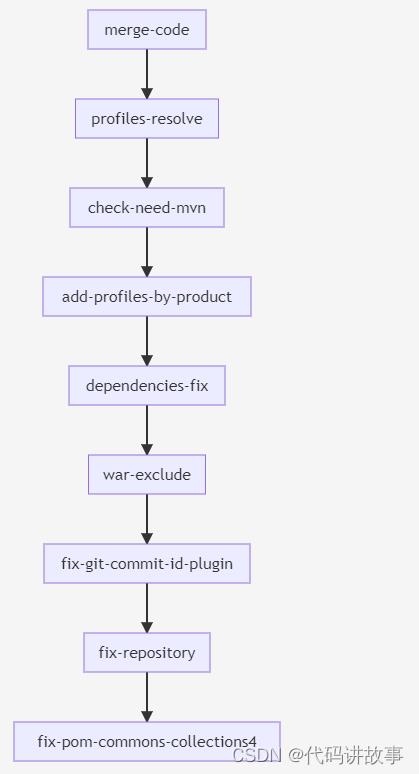
各个步骤完成的内容为:
merge-code:合并主框架代码和项目定制代码。
profiles-resolve:解决profile定义不规范问题。
check-need-mvn:判断是否需要maven构建,后续任务需要使用,例如判断是否运行打包。
add-profiles-by-product:根据产品线追加profiles。
dependencies-fix:修复pom文件中传递依赖定义不完整问题。
war-exclude:排查war打包,只需要更新部分jar时,排斥war打包步骤能够加快打包速度。
fix-git-commit-id-plugin:解决git-commit-id-plugin插件问题。
fix-repository:由于内网maven镜像仓库地址有调整,修改pom中定义的maven镜像源。
fix-pom-commons-collections4:修复部分版本缺少commons-collections4。
profiles-resolve任务的很多额外步骤是为了解决代码代码不规范的问题,例如代码中profile定义不完整,直接执行maven clean package -P pluginName1,pluginName2,…时,往往不能成功。在profiles-resolve步骤中,通过多次循环补充当前profiles依赖的其他profiles。虽然直接修改代码也能解决这个问题,但是由于wizdom-urban-v14代码插件非常多,分支也非常多,改起来会相当耗时。并且由于插件之间依赖关系比较复杂,开发过程中难以维持正确的依赖关系定义。
4.4发布更新
由上文任务列表可知,服务更新其实也是包含在任务执行中的。我们借助Argo CD的自动同步和部署应用程序的优势,在打包完成后,制作docker镜像,并推送到镜像仓库。随后更新Argo CD部署文件代码,触发Argo CD同步,Argo CD检测到部署文件更新后,将自动与K8S交互,更新服务。K8S滚动更新的特性,能够在保证服务不中断的情况下完成升级。
总结起来,流水线的使用流程如下图:
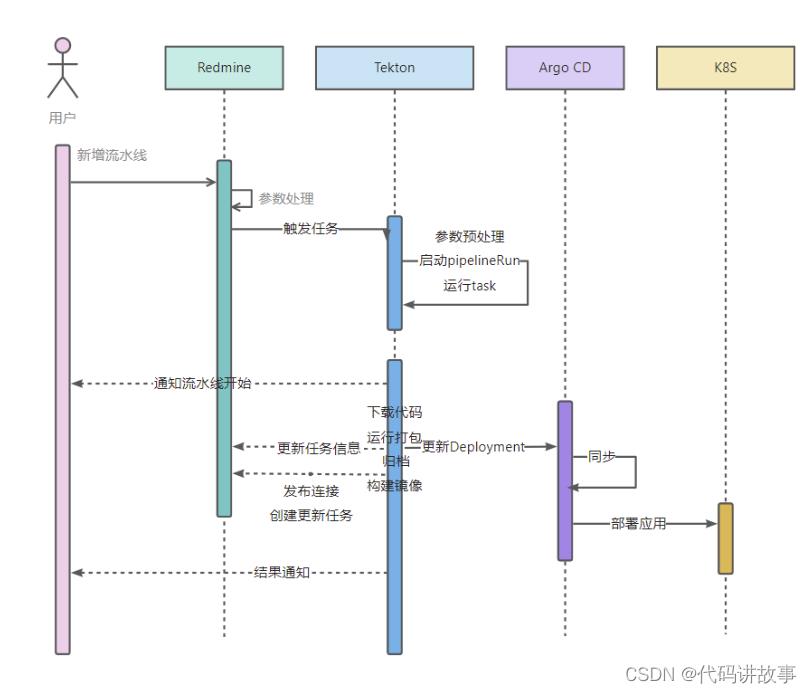
5. 成果和计划
相比传统的Jenkins打包,流水线的优势在于:
省去了繁琐的构建任务配置,简化了启动流程的步骤。研发和测试只需要在任务平台上新增提测单,新增流水线即可,降低了学习成本。
利用了K8S滚动更新的特性,可以在服务不中断的情况下进行升级。
任务中灵活的脚本处理,能够在不改动代码的情况下,完成依赖修复,镜像仓库地址替换等。
任务中增加了异常处理,能够在打包失败时第一时间通知流水线操作人、研发处理人。并在项目管理平台任务重附上错误日志,便于即使排查解决问题。
流水线完成后自动发布归档文件下载链接,省去测试人员整理结果上传百度云的步骤,提高了工作效率。
自动创建更新任务,测试人员无需手动创建更新任务并粘贴更新文件下载链接。
截止目前,流水线平台已归纳支持12种类型的代码结构打包,主要包含了智云主框架、智云前端、智信前端、微服务、智云拆分代码、智信拆分代码等。项目管理平台接入流水线仅半年就完成了打包任务数3987,流水线任务总运行8140次。通过Argo CD管理一网统管、信息采集、城市大脑、基础平台、市政、执法、星桥、灵珑、社会治理、运管服10条产品线,共67套运行环境。
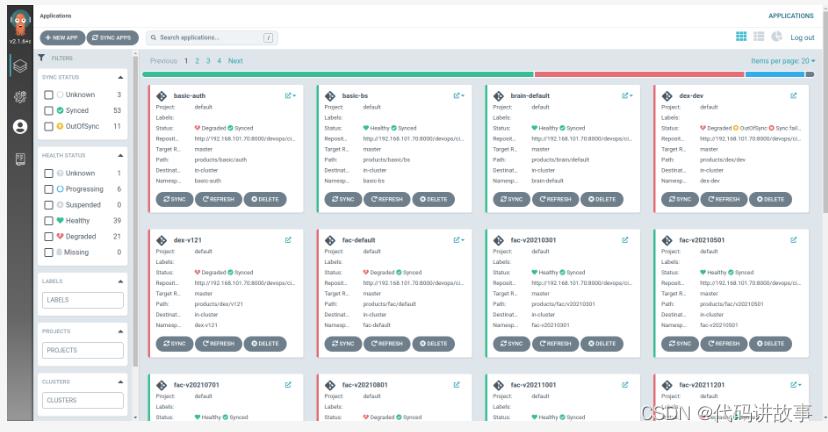
后续计划整合其它地区的服务器,全部虚拟化后,将各产品线测试环境全面接入流水线,研发、测试环境隔离互不干扰,做到可按需开启,定时关闭。利用流水线流程的易扩展性,接入单元测试、自动测试流程。
运维自动化发展
# 运维自动化发展
## 运维学习和发展的一个线路
- 1.搭建服务(部署并运行起来)
- 2.用好服务(监控、管理、优化)
- 3.自动化(服务直接的关联和协同工作)
- 4.产品设计(如何设计一个监控系统)
**云计算的核心竞争力是运维!**
系统架构师(偏管理):网络 系统 数据库 开发 云计算 自动化 运维管理 服务管理 项目管理 测试 业务
专注于某一领域
解决方案架构师
## 运维工作内容分类
- 监控运维(7x24运维值班、故障处理)
- 应用运维(业务熟悉、服务部署、业务部署、版本管理、灰度发布、应用监控)
- 安全运维(整体的安全方案、规范、漏洞监测、安全防护等)
- 系统运维(架构层面的分布式缓存、分布式文件系统、日志收集、环境规划(测试、开发、生产)、架构设计、性能优化)
- 基础服务运维(包含运维开发)(内部DNS、负载均衡、系统监控、资产管理、运维平台)
- 基础设施运维(系统初始化、网络维护)
- 机房运维(负责设备上下架、巡检、报修、硬件监控)
阿里云:
SLB LVS + Tengine(Nginx)
ECS KVM
## 运维标准化
**物理设备层面:**
1.服务器标签化、设备负责人、设备采购详情、设备摆放标准
2.网络划分、远程控制卡、网卡端口
3.服务器机型、硬盘、内存统一,根据业务分类
4.资产命名规范、编号规范、类型规范
5.监控标准
**操作系统层面**
1.操作系统版本
2.系统初始化(配置DNS、NTP、内核参数调优)
3.基础Agent配备(Zabbix agent、logstash agent、salt minion)
4.系统监控标准(CPU、内存、硬盘、网络、进程)
**应用服务层面:**
1.Web服务器选型(nginx、Apache)
2.进程启动用户、端口监听规范、日志收集规范(访问日志、错误日志、运行日志)
3.配置管理(配置文件规范、脚本规范)
4.架构规范(Nginx+keepalived、LVS+keepalived等等)
5.部署规范(位置、包命名等)
**运维操作层面:**
1.机房巡检流程(周期、内容、保修流程)
2.业务部署流程(先测试、后预生产,再生产。回滚)
3.故障处理流程(紧急处理、故障升级、重大故障处理)
4.工作日志流程(如何编写工作日志)
5.业务上线流程(1.项目发起人 2.系统安装 3.部署nginx 4.解析域名 5.测试 6.加监控)
6.业务下线流程(谁发起,数据如何处理)
7.运维安全规范(密码复杂度、更改周期、VPN使用规范、服务登陆规范、rm命令的参数写在最后面)
标准化:规范化 流程化 文档化
目标:文档化
## 运维自动化发展-工具化
**工具化:**
- 1.shell脚本(功能性(流程)脚本、检查性、报表性)
- 2.开源工具:zabbix、elkstack、saltstack、cobbler
**目标:**
- 1.促进标准化的实施
- 2.将重复的操作简单化
- 3.将多次操作流程化
- 4.减少人为操作的低效和降低故障率
工具化和标准化是好搭档
**痛点:**
- 1.你至少要ssh到服务器执行,可能出错
- 2.多个脚本有执行顺序的时候,可能出错
- 3.权限不好管理,日志没法统计
- 4.无法避免手工操作
**例子:**
比如某天我们要对一个数据库从库进行版本停机升级。那么要求评估:
停机影响:
3:00 晚上有定时任务连接该数据库,做数据报表统计
- 1.凌晨3:00 我们所有系统的定时任务有哪些crontab
- 2.这些crontab哪些要连接我们要停止的从库
- 3.哪些可以停,哪些不能停(修改到主库),哪些可以后补
- 4.这些需要后补的脚本哪个业务的,谁加的,什么时候加的
## 运维自动化发展-web化
运维平台
例子:Job管理平台
- 1.做成web界面
- 2.权限控制
- 3.日志记录
- 4.弱化流程
- 5.不用ssh到服务器,减少人为操作造成故障 Web ssh
DNSWeb管理 bind-DLZ
负载均衡Web管理
Job管理平台
监控平台 zabbix
操作系统安装平台
## 运维自动化发展-服务化(API)
- DNSWeb管理 bind-DLZ dns-api
- 负载均衡Web管理 slb-api
- Job管理平台 job-api
- 监控平台 zabbix zabbix-api
- 操作系统安装平台 cobbler-api
- 部署平台 deploy-api
- 配置管理 saltstack-api
**智能化实现**
- 1.调用cobbler-api安装操作系统
- 2.调用saltstack-api进行系统初始化
- 3.调用dns-api解析主机名
- 4.调用zabbix-api将该新上线机器加上监控
- 5.再次调用saltstack-api部署软件(安装nginx+php)
- 6.调用deploy-api将当前版本的代码部署到服务器上
- 7.调用test-api 测试当前服务器运行是否正常
- 8.调用slb-api 将该节点加入集群
## 运维自动化发展-智能化
运维自动化发展层级:
- 标准化、工具化
- Web化、平台化
- 服务化、API化
- 智能化
智能化的自动化扩容、缩容、服务降级、故障自愈
**自动化扩容**
1.zabbix触发Action
触发条件和决策:
- 1.当某个集群的访问量超过最大支撑量,比如10000
- 2.并持续5分钟
- 3.不是攻击
- 4.资源池有可用资源
* 当前网络带宽使用率
* 如果是公有云--钱够不够
- 5.当前后端服务支撑量是否超过阈值 如果超过应该后端先扩容
- 6.数据库是否可以支撑当前并发
- 7.当前自动化扩展队列,是否有正在扩容的节点
- 其他业务相关的
创建虚拟机之前,先判断Buffer是否有最近X小时已经存在之前已经移除的虚拟机,并查询软件版本是否和当前一致,如果一致,跳过234步,如果不一致,跳过23步
2.Openstack 创建虚拟机
3.Saltstack 配置环境
4.部署系统 部署当前代码
5.测试服务是否可用(注意间隔和次数)
6.加入集群
7.通知(短信、邮件)
**自动化缩容**
- 1.触发条件和决策
- 2.从集群中移除节点
- 3.通知
- 4.移除的节点存放于Buffer里面
- 5.Buffer里面超过1天的虚拟机,自动关闭,存放于xx区
- 6.xx区的虚拟机,超过7天的清理删除
以上是关于自动化运维|云原生架构下的产品自动化发布快速部署和持续交付实战之路的主要内容,如果未能解决你的问题,请参考以下文章