性能测试实践 | 饿了么全链路压测平台的实现与原理
Posted 51Testing软件测试网
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了性能测试实践 | 饿了么全链路压测平台的实现与原理相关的知识,希望对你有一定的参考价值。
15
前言
随着业务的快速发展我们日常遇到的系统性能压力问题也逐渐出现,甚至在部分场合会遇到一些突发的营销活动,会导致系统性能突然暴涨,可能导致我们系统的瘫痪。最近几年随着电商的各种促销活动,有一个词也渐渐进入我们眼帘--“全链路压测”。全链路压测被众多互联网公司的程序员定义为核武器,传统性能测试更多的是以事务为核心,更多的是由单个或者多个事务构成业务场景进行压测。那全链路压测到底是什么?一般指完全引入相关联的系统真实模拟线上硬件环境,更多的是以请求为核心,完全模拟真实请求流量,通过引流等方式进行场景的模拟进行压测,更多的适用于业务链路较长的交易。
背景
在上篇文章中,我们曾介绍过,重点是业务模型的梳理与数据模型的构建,在形成脚本之后需要人工触发执行并分析数据和排查问题,整个过程实践下来主要还存在以下问题:
1.测试成本较高,几乎每个环节都需要人力支撑,费时费力。
2.由于测试用例较多,涉及的测试机范围较广,手工执行容易犯错,线上测试尤其危险。
3.记录结果和测试报告极不方便,需要二次加工、填写和上传。
4.测试过程中靠手工监控,覆盖不全且定位问题困难。
基于这些因素,我们决定推进全链路压测的自动化进程。这篇我们主要介绍全链路压测平台的实践。
目标
为了解决以上核心痛点,平台至少需要保证以下方面的功能:
用例管理:用户建立测试用例,上传资源文件,系统进行分类管理。
压测执行:一键触发已有测试用例,可指定线程数、预热时间、测试周期和测试机等,可以自动切分数据,分布式执行。
实时结果(热数据):响应时间、吞吐量、错误率等数据以图表形式实时显示。
测试结果(冷数据):平均响应时间、平均吞吐量,90/95/99线等数据以图表形式在测试结束后显示。
测试机集群监控:监控测试集群的使用状态,提示用户可用的测试机。
安全保障:平台应该对用户操作进行适当限制,并能自我应对一些异常情况。
主要功能与实现概要
压测平台是典型的B/S类型Java Web项目,基于Spring Boot开发,前端使用AngularJS。平台本身不执行测试只做调度,避免成为瓶颈,后台均使用JMeter执行测试;平台自身会维护压测机集群,保证压测机是可供测试的;测试期间产生的冷数据(用例数据、结果数据)持久化至MongoDB,热数据(实时数据)持久化至InfluxDB并定期清理。
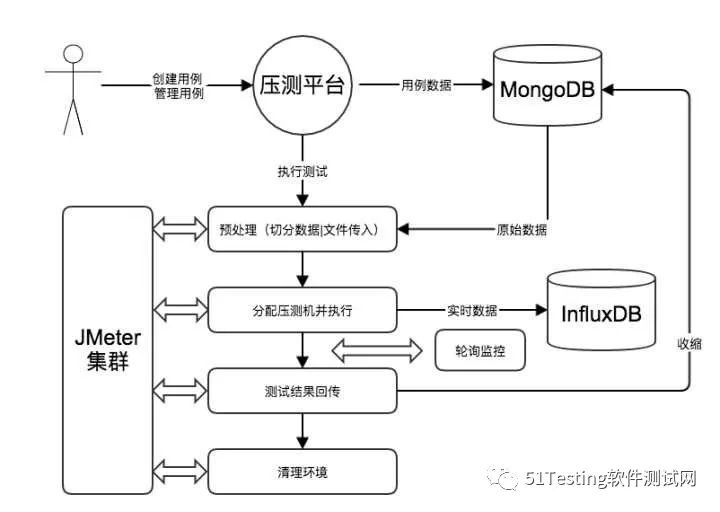
分布式测试
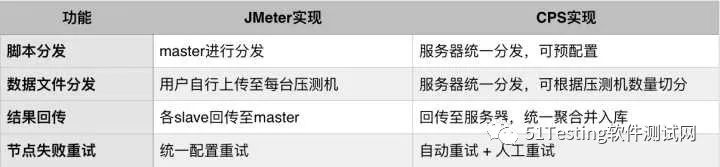
在使用JMeter进行性能测试时,如果并发量比较大,单机的配置可能无法支持,这时需要联合多机进行分布式测试。我们并没有采用JMeter自身的分布式功能,而是自己做了实现,主要是考虑到:
JMeter的分布式测试执行和单机执行方式的差异较大,这会导致平台架构不必要的复杂度,实际用户只感知测试机的数量区别。
JMeter分布式执行的方式,master机通常不参与测试,而是收集slave信息,但这会造成一定程度上的资源浪费。
我们使用饿了么内部的EOC工具对压测机进行调度,并实现了JMeter自身具备的分布式调度功能,相应的对比见下表。基于我们的实现,压测过程中热数据和冷数据是分离传输的,冷数据在测试完成后才会传输(如果不需要压测端数据,甚至可以配置不存储冷数据),因此该方案对于扩容是非常友好的,理论上支持的TPS没有上限。
测试状态流转
测试状态流转是压测平台的核心,每一轮正常的测试工作都会经历一条主线,即:配置 -> 触发 -> 运行 -> 结果收集 -> 清理。测试状态流转的设计围绕着这条主线,辅以外部干预和内部监控功能,保证测试的正常进行。
此外,我们还需要鉴别出各种可能的异常情况(如测试触发失败)和合理情况(如用户主动停止),并据此输出不同的反馈信息,并且无论测试流程出现何种分支,最后都能形成闭环,这对系统的健壮性非常重要。以下是状态流转图:
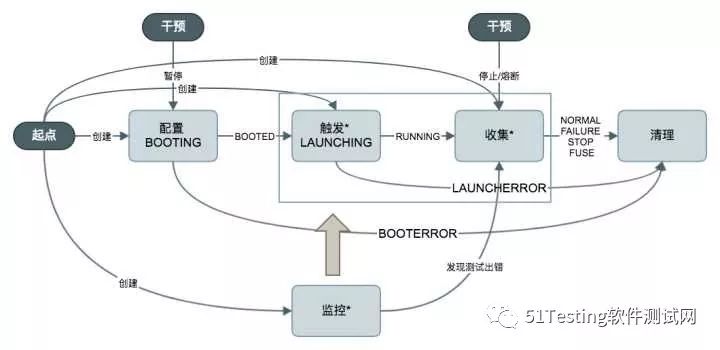
举两个典型的应用场景:
1.用户触发测试后,由于测试压力过大,运维要求立刻停止测试,这时的闭环为:初始 -> BOOTING -> LAUNCHING -> 用户触发停止 -> 直接进入收集流程 -> 状态标记为STOP -> 清理压测机 -> 初始
2.用户触发测试后,压测机由于某些原因突然断网,这时的闭环为:初始 -> BOOTING -> LAUNCHING -> 监控发现问题 -> 状态标记为FAILURE -> 清理压测机 -> 初始
整个状态流转的实现,采用异步Job机制实现了类似状态机的概念,状态属性持久化到数据库中,便于恢复。
实时数据
JMeter本身并不提供图形化的实时数据展示功能,以往我们只能通过JMeter Log看到一些粗略的信息,并结合外部监控工具观察指标情况。在压测平台中,我们对该功能进行了实现,主要原理是通过JMeter的Backend Listener (JMeter 3.2+),将测试结果实时发往InfluxDB,同时平台向InfluxDB轮询查询数据,得到实时曲线并展示给用户。
在实践过程中,向InfluxDB发送数据的频次是比较高的,可能会对压测机造成压力,因此我们改造了JMeter的InfluxDB sender,替换了HTTP方式,增加了以UDP协议发送数据的实现,解决了这一问题。
预配置
在“测试状态流转”一节中,阐明了测试的总体流程,第一步即为配置,配置的具体内容是:将测试需要的脚本、数据文件和插件,推送到每一台测试机上,为测试执行做好准备。
但如果测试文件比较大,或者需要配置的压测机数量比较多,配置可能会占用较多时间,影响测试进程,这是很多平台遇到的共性问题。对此,我们提出了预配置的概念,即用户可以提前对测试用例,针对某几台压测机进行配置工作,但并不执行。预配置会保留一定的时间,在这段时间内,用户可以直接执行测试,不需要再重复配置。
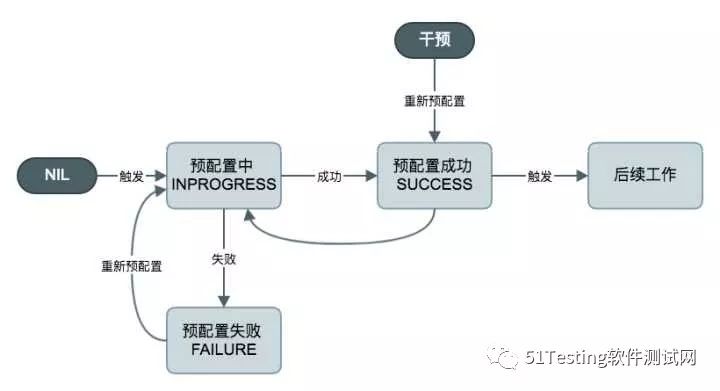
以下为预配置的状态转换图:
熔断与兜底
全链路压测一般都在线上真实环境进行,安全是首要考虑的因素,不能因为测试本身而导致服务不可用或事故。我们提供了四个维度的机制进行安全保障。
1.权限管理:用户权限分级管理,不能随意触发他人的测试用例,同时高峰期和禁止发布期,不允许执行任何测试。
2.停止功能:这是面向用户的手动停止功能,用户可以随时点击运行状态下的测试用例上的停止按钮,后台会直接kill掉所有运行该测试用例的测试机上的JMeter进程。
3.熔断功能:系统会根据实时信息中的错误率进行判断,当一定时间内的实时错误率达到或超过某个阈值时,该次测试将被自动熔断,无需用户干预。
4.兜底脚本:最极端的情况,当整个系统不可用,而此时需要停止测试时,我们提供了一份外部脚本直接进行停止。
结果收集
由于我们自己实现了JMeter分布式的管理,因此我们也需要自己对结果集进行处理,结果的主要来源为测试生成的JTL文件。
针对JTL,结果数据需要做预聚合再存入,原因是JTL中单条结果数据的大小非常小(大约100多个字节),但总量很大(可能有几万到几百万条),很容易由于重复存储维度字段的KEY值而导致表过大。预聚合主要根据以label作大分类,维度作小分类,以时间作为聚合标准,interval固定,从而保证Document大小不会过大。
以下是结果集片段的数据结构概要(单label):
{
"label": "upload",
"totalCount": 428,
"totalErrorCount": 12,
"errorMsg": [
{
"msg": "io.exception",
"count": 12
},...
],
"errorCode": [
{
"code": "404",
"count": 12
},...
],
"count": [
12, …, 15
],
"error": [
12, …, 15
],
"rt": [
12, …, 15
],
"minRt": [
12, …, 15
],
"maxRt": [
12, …, 15
]
}
前端会根据持久化的数据,形成可视化图表,为用户展现。
总结与展望
全链路压测平台自今年7月上线以来,为超过5个部门累计提供了上千次测试服务。按照每一类测试配置和执行的人力成本为15分钟计算,大约节省了1000个小时的工作量。
目前,全链路压测的自动化只是针对测试执行范畴,我们还有很多工作要做,在未来,我们希望能够将自动化的脚步覆盖到测试前和测试后,真正建设出全链路压测的自动化生态体系。
作者介绍
吴骏龙,2017年3月加入饿了么,现任饿了么测试基础设施部负责人。
-END-
上文内容不用于商业目的,如涉及知识产权问题,请权利人联系小编,我们将立即处理。
以上是关于性能测试实践 | 饿了么全链路压测平台的实现与原理的主要内容,如果未能解决你的问题,请参考以下文章