干货 | 饿了么全链路压测的探索与实践
Posted 51Testing软件测试网
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了干货 | 饿了么全链路压测的探索与实践相关的知识,希望对你有一定的参考价值。



自2015年开始,随着互联网行业的快速发展,饿了么公司的业务也进入了快速扩张阶段,饿了么在线外卖平台用户量达2.6亿,覆盖全国2000多个城市。
外卖业务本身具备以下特点:
时效性: 从用户下单到商家接单再到物流配送到家,整个流程要控制在一定时间范围之内,对时效性的要求非常高;
高并发: 大量用户产生的千万订单集中分布在中午和傍晚两个时间段内,对整个系统的冲击可想而知;
秒杀活动: 为了充分利用闲时的机器资源,会在几个整点进行秒杀活动,整点活动产生的瞬时流量甚至能超过午高峰的最高值;
常规化: 这种大流量的冲击不是偶发的,而是一个常态化的过程,这对系统的稳定性提出了极高的要求;
基于这些因素,再加上线上不断有容量引发的问题发生,对整体系统进行全链路压测势在必行。
饿了么的全链路压测工作都是在线上环境进行,至于为何不在测试环境进行,主要基于以下两个原因:
1. 测试环境硬件资源以及压测数据与线上差别太大,压测出来的数据指标参考价值不大;
2. 服务间依赖关系错综复杂,测试环境很难模拟且不够稳定。
整个全链路的压测也不是一蹴而就的,中间主要经历了三个阶段。
1. 缩减服务器
在低峰时间段,通过一台台缩减集群内服务器的数量,使得单台服务器的请求量不断加大,从而评估当前集群容量及预估后续随着单量的增长所需服务器的数量。
优点:
真实流量,评估出的容量最真实;
不用编写压测用例和准备压测数据,节省大量压测准备的时间;
无脏数据产生;
缺点:
风险性比较高,一旦发现达到瓶颈必须立马恢复;
由于请求量恒定,通过缩减服务器数量的方式并不能评估出底层基础组件的容量,如DB,MQ等基础组件,从而会导致容量评估不准确;
对于访问流量有一定要求,流量太小的话达不到瓶颈;
2. 单独业务压测
针对单个业务在低峰期进行压测,这就需要压测人员对业务有一定的敏感度,对业务和系统架构有比较深的了解。
来个实例,下面是商户系统的一个简单架构图
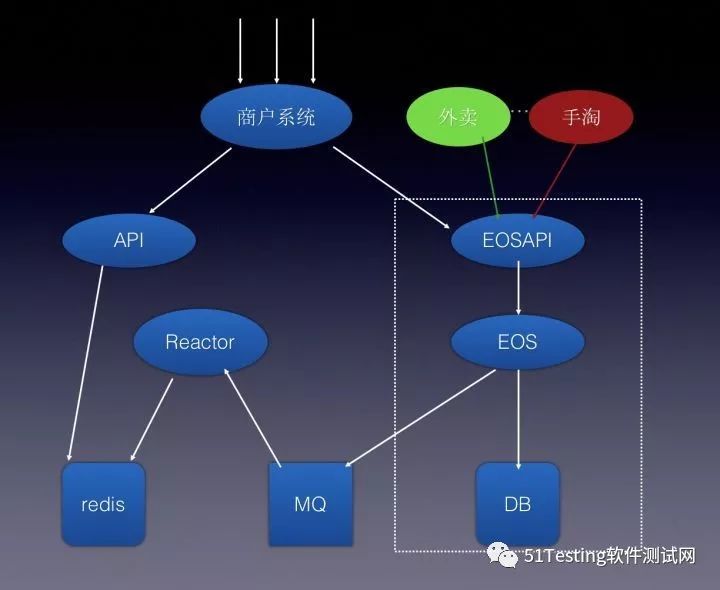
商户读请求调用API, 写请求调用EOSAPI,其中EOSAPI是订单基础服务,压测流量从商户系统进来继而评估容量,这样压测得到的数据比实际线上真实情况会偏优,因为线上EOSAPI不仅只有商户系统在调用,下单服务也会同时调用。
基于以上种种情况,最终我们决定在线上进行全链路压测。
3. 线上全链路压测
模拟外卖平台下单,开放平台下单(如手淘),商户接单和物流配送,模拟大量的用户查询操作,覆盖所有关键路径的接口,通过不断从各个入口加压,既能做到对各个服务的容量做到评估,也能观测底层服务(包括各个中间件)的性能指标,对整个业务系统的容量评估也相对精准;
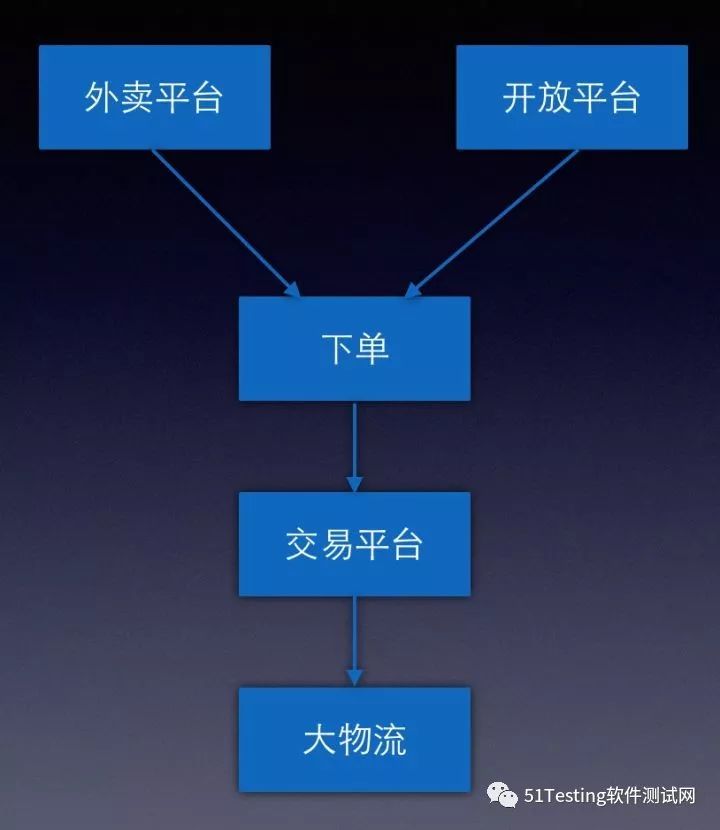
当然,这样做也会带来一些问题,最典型的就是写请求产生的脏数据怎么处理。最开始我们想把涉及到写数据的地方把压测流量通过识别写到隔离的位置,但是后来发现要改造的地方(包括各个业务,中间件等)太多,而我们又急需解决线上容量问题,最后决定对压测数据做逻辑隔离,即对压测数据做特殊的标识与真实数据区分开来,后面做大数据统计分析,清结算等也会通过特殊标记把压测数据过滤掉。
具体怎么来做好全链路压测呢?主要包括以下几个方面。
1. 业务模型的梳理
业务模型梳理需要结合业务本身和业务系统的架构,这一步至关重要,梳理的是否完善直接关系到最终压测结果是否具有参考价值。
举个例子:下面是全链路压测中某个业务的系统架构图。
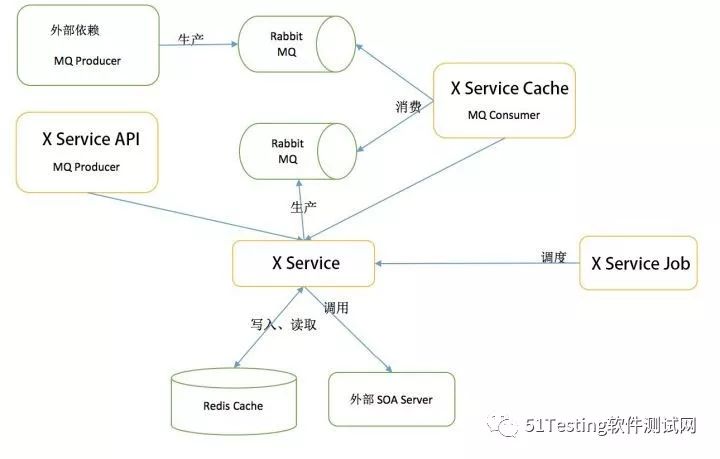
其中,不仅仅需要关注X Service服务本身提供API的性能情况,还需要关注X Service Cache MQ Consumer的消费能力。业务模型的梳理对压测人员的业务架构敏感度要求非常高。
具体的架构梳理主要有以下几个方面:
是否关键路径
业务的调用关系
业务的提供的接口列表
接口类型(http、thrift、soa等)
读接口还是写接口?
各接口之间的比例关系
2. 数据模型的构建
数据模型的构建总的原则:紧贴业务场景,最大可能地模拟真实用户的请求。
实例一: 写请求
压测场景: 用户下单
压测方法:
用户、商户、菜品等在数量上与线上等比例缩放;
对压测流量进行特殊标记;
根据压测标记对支付,短信等环节进行mock;
根据压测标记进行数据清理;
实例二: 读请求
压测场景: 商家列表及关键词查询
压测方法:
拉取线上日志,根据真实接口比例关系进行回放
实例三: 无日志新服务
压测场景: 商家资质查询
压测方法:
构建压测数据使缓存命中率为0%时,服务接口性能,数据库性能;
缓存命中率为100%时,服务接口性能;
缓存命中率达到业务预估值时,服务接口性能;
当然,曾经也因为压测数据碰到过一些坑(跟真实场景有差异):
压测用户数据未考虑sharding分布,导致DB单点过热
用户数量过少,导致单个测试用户订单量过多
商家数量过少,导致菜品减库存锁争抢激烈
可见,压测数据模型的构建也不是一蹴而就的,这是一个持续调整持续优化的过程,需要同时考虑数据的真实性,时效性,安全性等。
3. 压测工具的选型
目前饿了么压测工具以Jmeter为主,主要基于以下几点:
开源轻量级,能够了解甚至修改其每个控件的实现
方便开发插件,可以支持如thrift等类型请求
支持丰富(如RemoteServer,设定集合点等)
压测结果数据与公司监控指标吻合
4. 压测指标的监控与收集
应用层面
错误率
吞吐量
响应时间(中位线,90线,95线,99线)
GC
服务器资源
CPU利用率及负载
内存
磁盘I/O
网络I/O
连接数
基础服务
MQ
Redis
DB
其他中间件
注意点
响应时间不要用平均响应时间,关注95线;
吞吐量和响应时间挂钩
吞吐量和成功率挂钩
本文介绍了全链路压测探索和实践的过程,但其中还是需要大量的人力介入,包括压测数据的准备、压测的执行、压测结果的分析等。为了尽可能地减少人力成本,提高全链路压测的自动化程度,目前我们正在着手施压平台和数据平台的开发,会在后续另一篇文章中进行详细介绍。
作者简介
严佳奇,2015年加入饿了么,现任饿了么测试基础设施部资深测试开发工程师,负责饿了么全链路压测工作。
-END-
上文内容不用于商业目的,如涉及知识产权问题,请权利人联系小编,我们将立即处理。
点击“阅读原文”,查看全文内容!
以上是关于干货 | 饿了么全链路压测的探索与实践的主要内容,如果未能解决你的问题,请参考以下文章