蘑菇街的全链路监控平台和全链路压测系统 | Open Talk 美联专场
Posted 又拍云
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了蘑菇街的全链路监控平台和全链路压测系统 | Open Talk 美联专场相关的知识,希望对你有一定的参考价值。
2017年5月13日,无相 于 又拍云 Open Talk 美联技术专场上分享了《蘑菇街的稳定性实践》,本文根据无相分享的下半部分整理;上半部分另行整理成《大促不慌,蘑菇街的稳定性保障》一文。
无相:2014年加入蘑菇街的搜索团队,开发了类似于全链路监控的工具,用于提升整条链路的稳定性。后开始负责全站稳定性工具和平台相关的工作,并参与了全流程加速系统的开发。
这里分享一下蘑菇街研发的全链路监控平台——lurker,和全链路压测系统。
全链路监控平台对于梳理应用关系非常有帮助,全链路压测系统的意义则在于寻找瓶颈,解决瓶颈。这对日常、大促的平台稳定性有着非常重要的意义。
lurker:蘑菇街全链路监控平台
为了加强稳定性工作,蘑菇街开发了一个全链路监控平台工具——lurker。取这个名字的初衷,是希望它埋伏在地底下,在设计和使用的时候,尽量地减少业务方对这个东西的感知,但实际上lurker又帮助他们解决了实际问题。
在开发lurker的时候,蘑菇街95%代码以上还是php,部分代码做了PHP服务化,服务可以互相去调用的。比如想监控PHP服务里面的每一个函数,到底是不是每一个函数时间过长。所以我们当时想了一个办法,Facebook有一个xhprof的工具,可以监控每个函数,通过PHP扩展实现。我们在xhprof的基础上改了一下,就变成蘑菇街的lurker,它的原理是什么?PHP有一个绽裂引擎,有一个函数执行指针,把这个指针替换成蘑菇街的hook函数,然后做了一些处理,可以让业务方判定哪些函数是需要监控的。此外还修改了curl以及php-curl的实现。

全链路监控的原理最早是由Google Dappen提出的,是一个分布式的监控系统。当本身的应用逐步服务化的时候,服务拆分会越来越细,现在蘑菇街有大几百个应用,应用之间互相有很复杂的调用。某一条复杂的链路可能要涉及到几百次调用,如果一次调用IP超时的话,怎么知道这么复杂的链路里面到底哪个超时了?
它的原理,每次调用都有一个全局唯一的Trace lD,它里面包括了一些业务含义,比如当时请求进来的机器IP、请求发生时间、进程ID等等,这些信息的加入,本身是为了保证全局唯一的特性。
另外一个是SpanlD,是为了区分调用中是一个顺序关系或者嵌套层次的关系。Trace Context是在哪里产生的?因为所有的请求进来都是在nginx,所以蘑菇街直接在nginx端做了插件,插件里面会产生Trace Context,它就会从请求进来的最前方开始一直传到最后面;它通过ServletFilter去实现在前端加入外部应用。
全链路监控系统架构
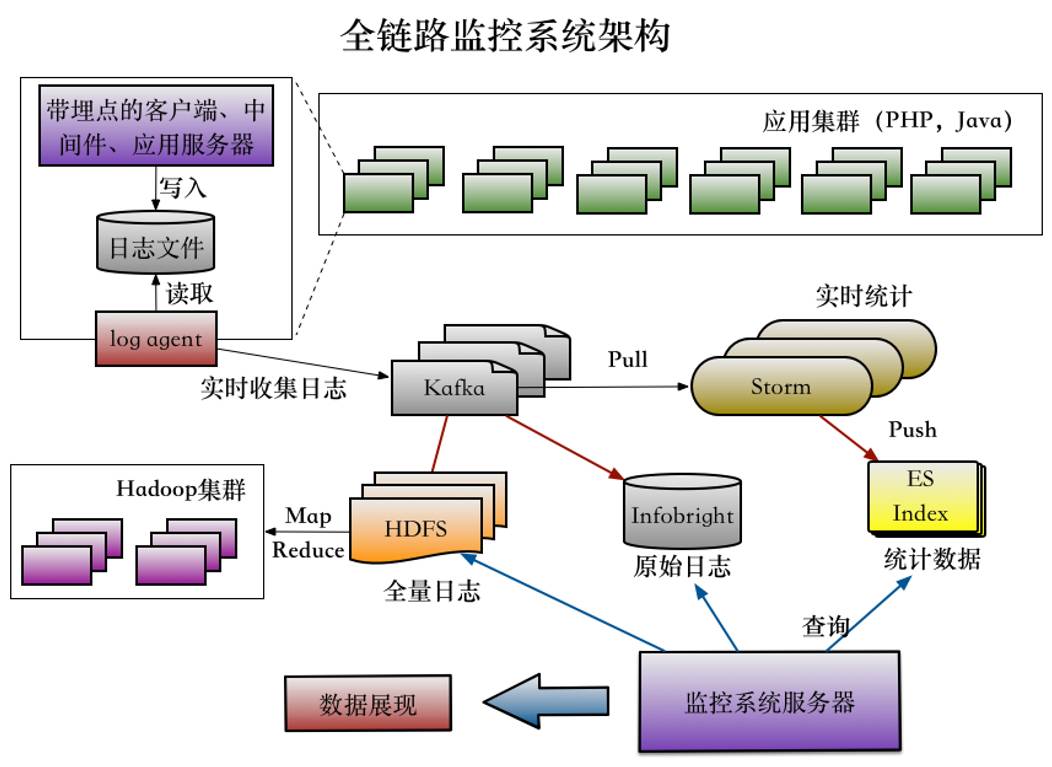
△ 蘑菇街全链路监控系统架构
蘑菇街全链路监控系统的架构如图所示。通过插件放在应用集群,不管是PHP还是Java,日志都会在本地落款。本地落款相对通过网络上传会更安全一点,出问题概率会小一点。
日志在本地落款之后再实时收集到Kafka,进入Kafka之后数据分三份:
一份数据进入Storm,然后进入ES Index里;
一部分原始日志直接放在Infobright;
一部分数据进入到HPS。
这个系统要支持多维查询,数据一开始放到支持全文检索的ES里,但ES数据不做压缩,存储成本很高。当时数据一天有好几T,存不了多久。后来用了Infobright,节约了很多成本,很好用。但Infobright是开源版,有一个人为设置,写数据的时候不能读。另外它只能单线,速度很慢,读一条日志需要6、7秒的情况。今年Q2,蘑菇街模仿Infobright做了一个类似存储的东西,现在已经差不多完成了,测试的结果性能还是相当不错的,压测率和Infobright差不多,速度很快。
Kafka另外一部分数据进入到HPS,主要是适应不适合用Storm做实时计算的情况。
全链路监控系统的作用
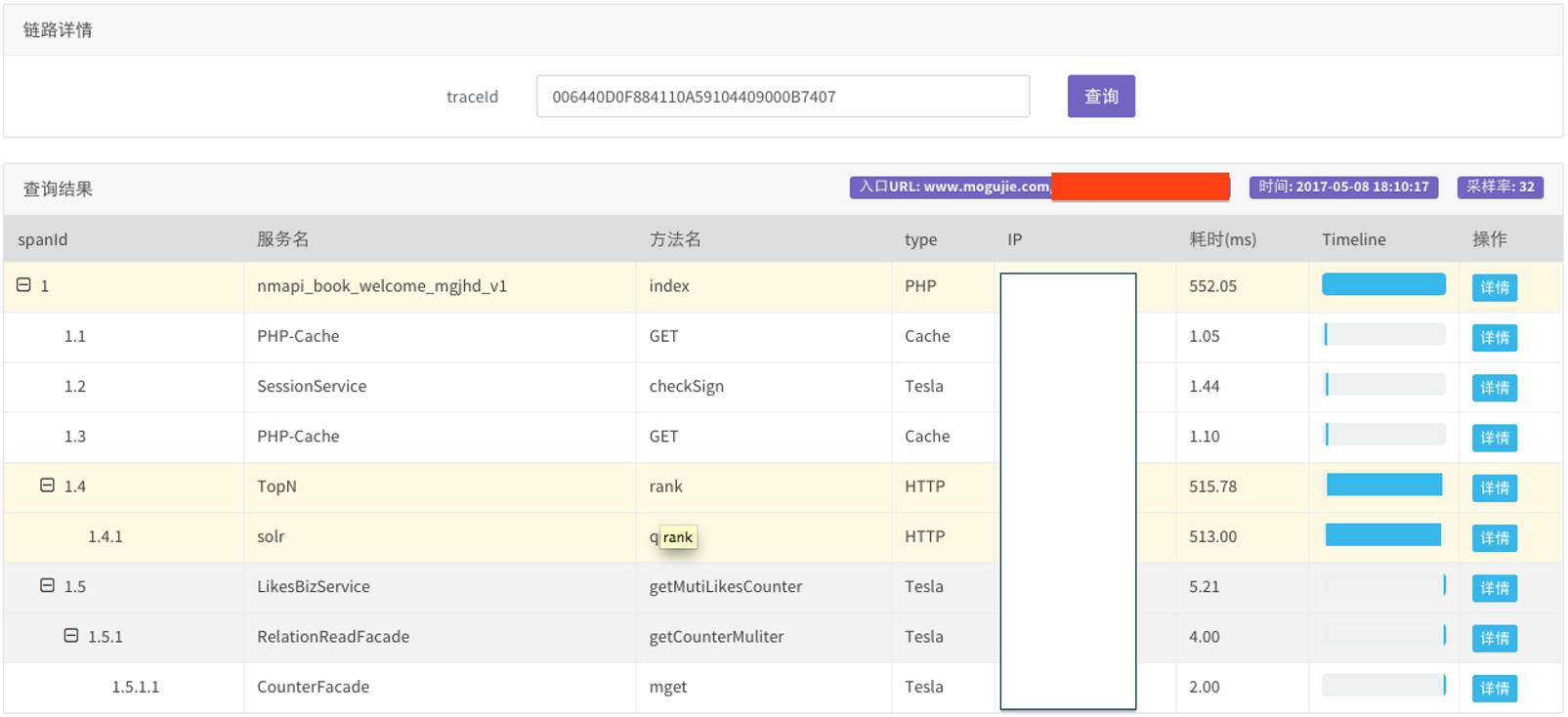
△ 蘑菇街 lurker 示意图
在蘑菇街lurker 示意图里,左边可以看到整个链路呈竖状的结构,1是1.1、1.2、1.3、1.4和1.5,1.4里面又有1.41,1.5调了1.51,每次调用服务、方法都写在这里,时间后面有Timeline,整个调用关系一目了然。
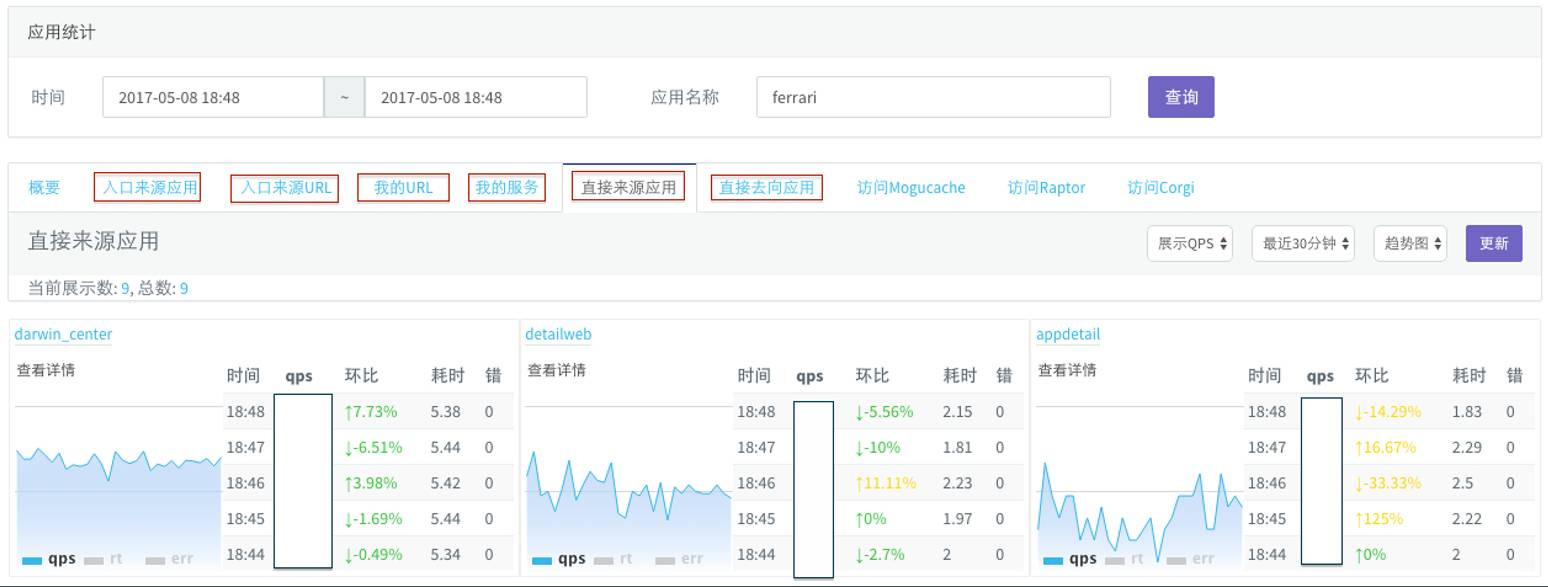
△ lurker 应用信息统计
除了调用关系之外, lurker 还能统计应用信息。每次调用和被调用者都有一条固定的认证关系,可以算出每个应用的直接应用来源、去向应用的数量,蘑菇街称之为“法拉力应用”,每个时间点上QPS到底是多少,有没有出错,都可以在应用信息统计上看到。假如调用了一个前端应用,还可以看到URL是多少。假如调用了一个后端服务,还能看到最最前面的应用,就是最早进来的URL,或者来源于哪几个应用。
利用监控系统,可以画出所有应用之间互相依赖的关系,并且把互相调用的比例也算出来。
lurker带有一个多维查询的功能,有些业务方可能想根据某些特殊条件,比如应用名、服务名、方法名、业务响应码或者是IP,都可以通过多维查询搜出来。多维查询的要求还是很高的,因为后续查询、后续数据存储都是需要解决的问题。
lurker 尚需解决的问题
在开发lurker 的过程中,蘑菇街也碰到了一些问题:
数据存储
跨线程传递trace context
前端应用接入不全,导致后端应用QPS不准确
周期性任务,链路路过长,展示有问题
数据存储问题如上文所说,历经几版,希望我们最近研发的产品能够撑住平台上产生的巨大数据量。
第二是跨线程传递,因为trace context从前端要往最后端传,为了给业务方不产生影响,或者让它们尽量没有感知,我们就把trace context放在这里面。但会出现一个问题,假如中间的一些工具有自己的现成词句,那就传不过去,信息就丢失了,链路到这一步就断掉了。我们想了几个办法,第一把trace context做的东西放进去,但是业务方不知道去用,他们不愿意去用,觉得比较麻烦。第二去修改现成词,直接把这些数据弄进去,但是修改以后业务方觉得修改后的这些东西到底靠不靠谱?所以目前碰到这个问题的时候,基本上建议业务方手工传一下,要不然在里面看不到。
第三个问题:前端应用接入不全。在推这个产品的时候,没有强制去接入,监控系统强大了之后,所有的前端用户都接入了,到后面的调用就没有被记录下来,所以后端应用QPS不准确。
最后是一些周期性任务。有一些任务链路比较长,比如一次跑一个小时,可能调个1万字也有可能,这个内容展示会有些问题。
全面分析全链路压测系统
全链路压测的意义在前文已经讲过了,在于验证瓶颈是否存在,以及找出可能的瓶颈,具体来说有以下几点:
对线上真实环境进行大流量演练
验证链路在超大流量系统里,容量和资源分配是否合理
找出链路中可能存在的瓶颈
验证网络设备、集群容量和预案、限流策略
建立压测模型
为了找到这个瓶颈,使蘑菇街的系统更加灵活,在设计压测模型的时候会有一些考虑:压测链路、压测场景、流量模型、压测任务、压测脚本。
所谓链路,一个URL就是一个链路,场景是链路上一层的概念,一个场景可以有单个或者多个链路组合而成。在电商环境下,某些场景是可以复用的。
压测场景以后,加上流量模型就可以构成一个压测任务,流量模型就是压测的时候流量怎么来,是一条直线比值压,还是要阶梯爬坡?
压测任务又会转化成压测脚本,这是一一对应的。
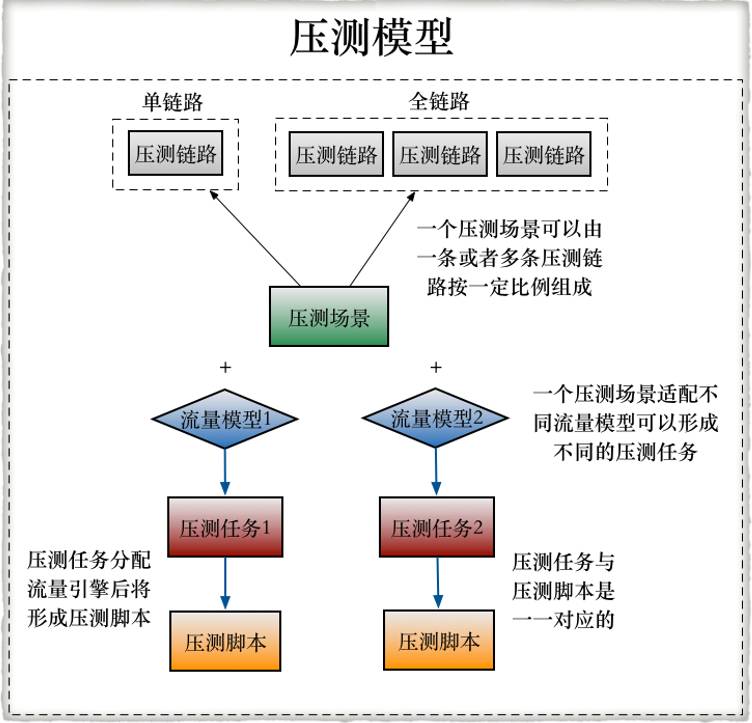
以支付里面的一个场景为例。支付收单是一个链路,流量从虚拟根节点进来之后,100%流量会去到支付收单节点,然后100%流量又会进入到收银台渲染节点,5%的流量会去A节点,40%去B节点,55%去C节点,最后100%去D节点。通过鼠标拽一下,一旦规定了入口接点是多少,就可以把整个场景规定下来。
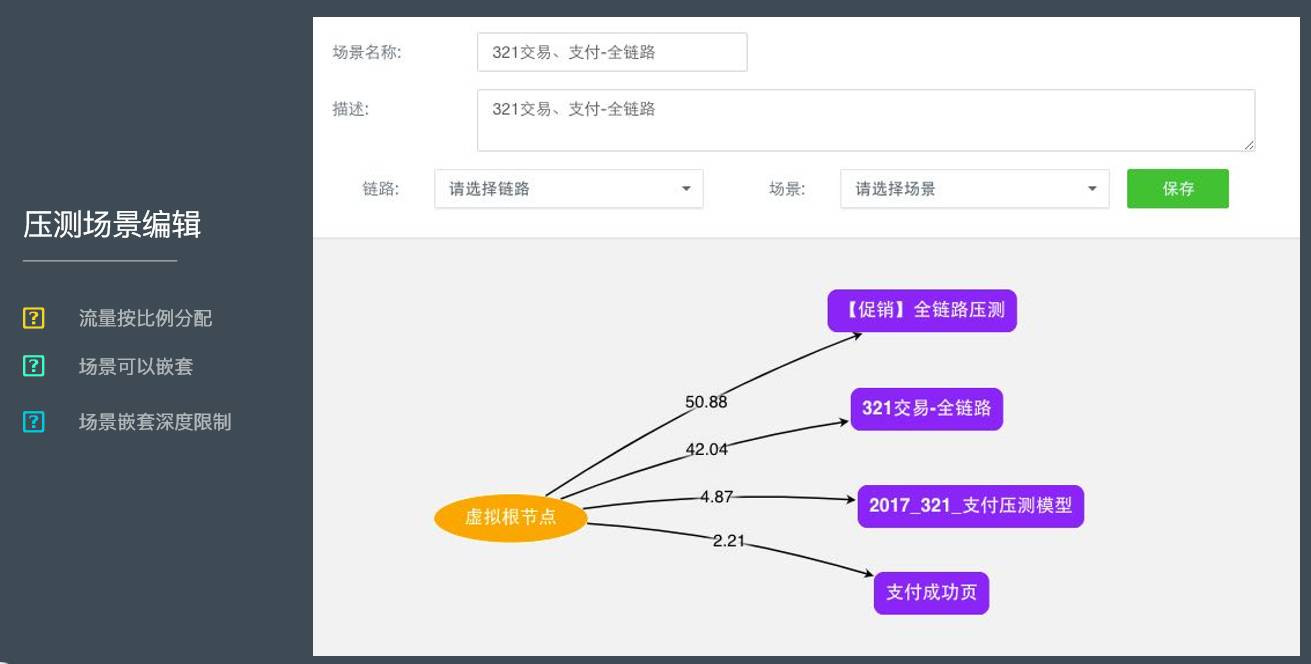
电商场景是可以嵌套,比如3.21交易之后的全链路,里面包括了促销压测模型、交易模型、支付模型、支付成功页,这些全部可以复用。假如说业务场景的逻辑不变,下次大促时这一个场景直接可以附在上面。
压测脚本做了二次改造,能够支持这四种不同的协议。第一会做脚本的确认,第二是数据确认,可以上传一些压测数据。第三是开始之后状态的检控以及结果的展示。
全链路压测系统架构解析
蘑菇街的全链路压测系统基于master slave开发,搭建速度很快。
这里有一个比较坑的地方,系统仅仅是支持单master,一套系统部署起来只支持一个master,我们要尽量避免单点。当时全链路压测系统刚完成1.0版,第二周就要压测,当时我们担心这个master会不会贵?结果果真贵了。贵的原因是什么?它和slave有交互,全链路压缩大概有100台压测机,特别是当压力压的比较大的时候,容易出错。
之后做了一些改造,包括实时回传、发起压测命令、上传压测数据、观察压测进度、收集压测结果。改造之后master好了很多。生成完了之后有一个数据工厂,它会自动生成要压测的那些数据,比如商品流数据、交易数据、促销数据都是从这个数据工厂里面来。
全链路压测系统还有一个OSS Storage,用于存储压测脚本和压测数据。OSS Storage有好几个备份,而且能够保障数据文件的安全,不需要再次关注。
全链路压测系统也碰到一些问题。蘑菇街的场景非常大,场景里面有很多内容定义,脚本会编译成JVM方法,大小不能超过65535。解决方法是——拆场景,比如把交易支付拆成一个场景,把搜索拆成一个场景。假如有100台机器,每一台机器跑一个脚本,这样就绕开脚本大小的限制了。
整个全链路压测系统要表面单点,它没有办法加载太大的压测数据文件。有一些业务方会要求回访现场数据,一拿回来就是几个G的大小,这需要非常长的时间,所以不推荐。蘑菇街现在的应对做法是把数据分割开。
以上是关于蘑菇街的全链路监控平台和全链路压测系统 | Open Talk 美联专场的主要内容,如果未能解决你的问题,请参考以下文章