浅谈基于平安云容器集群服务(PKS)的全链路压测调优实践
Posted 平安云
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了浅谈基于平安云容器集群服务(PKS)的全链路压测调优实践相关的知识,希望对你有一定的参考价值。
微服务架构现在越来越流行了,系统的拆分变得不可或缺,但随着系统逐渐服务化后,迎来的问题就变得多种多样了,同时以Kubernetes为核心的容器生态成熟完善,以微服务框架结合容器技术的研发体系已成为当前基础平台技术主流选择及演进方向。
本篇主要讲基于平安云容器集群服务PKS【基于kubernetes构建的容器产品】部署业务系统的全链路的监控及时找到问题瓶颈及调优。
随着业务系统的不断变大臃肿,服务按照不同的维度进行拆分,因此需要帮助理解系统行为、用于分析性能问题的工具,以便能够快速定位和解决问题。全链路监控组件就在这样的问题背景下产生了。针对业务场景越发复杂化、海量数据冲击下整个业务系统链的可用性、服务能力的瓶颈,让技术更好的服务业务,创造更多的价值。
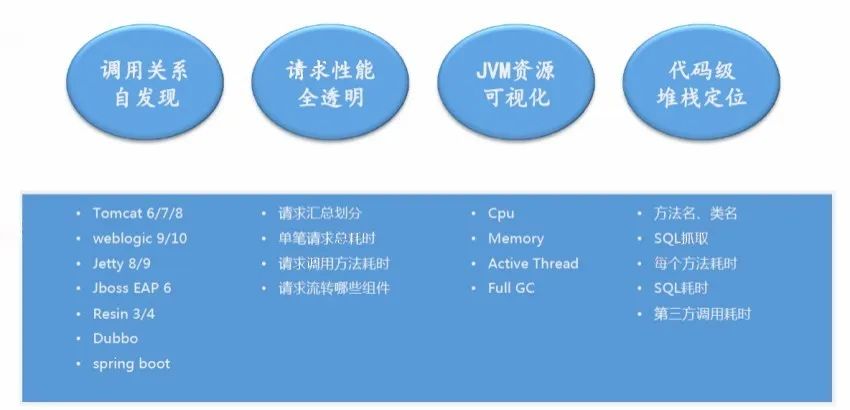
WiseAPM Detector是一款APM(Application Performance Management/应用性能管理)工具,平安科技自研,平安集团内主推的全链路APM监控系统平台。
特点:
服务端无侵入式全链路应用性能管理
自动发现应用拓扑,实时还原调用依赖关系
用户代码级堆栈跟踪,快速分析定位问题
支持多种语言,容器,架构及分布式等复杂环境
请求调用/DB调用综合数据分析
PKS是基于Kubernetes构建的容器产品,打破了传统IaaS/PaaS的界限,使用编排又十分灵活,且对业务应用有着直接的影响,基于PKS部署的应用做相关的问题瓶颈发现,场景分析调优是下面着重要讲的。
JVM的默认规则,它分配的Max Heap Size是系统内存的1/4,很容易超出resource limits的限制,导致容器被kill掉,让JVM在容器内感知内存稳定运行的,解决方法就是在Java启动命令前加上JVM_OPTS参数,具体规则如下:
如果低于这个版本,那么在 Java 容器的 CMD 命令里得加上具体的内存分配大小,如"-Xms64M -Xmx256M",注意-Xms最好不超过 Pod 限制资源3/4,因为不止是 JVM 要使用内存,容器本身也是需要内存的
需要加上参数
"-XX:+UnlockExperimentalVMOptions
-XX:+UseCGroupMemoryLimitForHeap
-XX:MaxRAMFraction=1"
特性默认开启
基于上述在做全链路压测时,监控JVM的监控指标,应用实例的性能,综合调优,最终确定一个适合当面业务的最佳资源配置,即Pod的resource request/limits配置,及JVM_OPTS参数设置。
组件的性能调优关注项:


Kubernetes的编排管理,自动驾驶能力来源于Master,运行中的应用实例,特别是在大流量高压力状态下的重新调度,故障自愈,自主管理对Master的要求很高,Master里的etcd的IO,数据同步时效,ApiServer的QPS,Scheduler的调度效率,Controller Manager的高感知响应度,都是集群稳定的关键。
调优方式包括底层的资源选择:
全闪存储,资源配置规格,ELB
集中式部署
各Master组件的参数调优,关掉不使用特性,调整自动管理的参数
Node节点上面会部署kubelet,kube-proxy,Docker,网络组件【Calico/Flannel/自研CNI】,还有OS的内核,Systemd,Iptables,各种Agent,都是要消耗资源的,且优先级高于容器实例,预留合适的资源,即能稳定地运行,又能尽量留出资源给业务Pod使用,提升资源利用率,这个是要压测评估的。
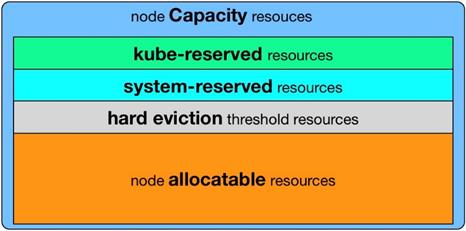
资源构成分析:
Node Capacity:整个Node节点的全部资源
System Reserved:预留给systemd,iptables,各种Agent的资源
Kube Reserved:预留给kubelet,kube-proxy,docker,网络组件【非容器化部署】的资源
Hard Eviction threshold:部署应用Pod时,为保证稳定性,在Node维度设置的一个安全阈值,可以设置为具体的数量,也可以设置为比例
Node allocatable:剩下可分配给应用Pod使用的资源,具体就是如上图
公式:
Node Allocatable = Node Capacity - Kube-reserved - System-reserved - Eviction-threshold
主要就是指CoreDNS,Prometheus,Node-exporter,Autoscaler等,整个集群公共的,以Pod形式部署的系统组件,这个是业务运行提供如,域名解析,监控数据采集汇聚,节点资源伸缩等,资源的配置,实例个数及分布,相关组件的参数设置都是结合实例状态可做优化的。
全链路压测最原始的目的就是找出部署架构的瓶颈,测出整个系统的负载能力,达到最优的效率,高稳定性,合理的容器规划,充分利用资源,最佳的支撑表现,最终满足业务的要求。
PKS由于是资源池配置逻辑,实例规格/个数,亲和/反亲和编排等相当灵活,所以具体关注优化的项目如下:
应用/中间件Pod的理想资源规格范围,如JVM在什么规格下性能最好
实例个数,基于HA考量,至少2个实例以上,实例是高配置资源,还是横向扩展个数
特别是ingress的对外流量转发Pod的选择
合理的选择Node的资源规格及节点数
资源超分配置,不同应用的资源参数设置,即request/limit的配置
应用编排,依据压测的监控数据,做到高负载的实例分散反新和部署,相互依赖的调用亲和性部署,使用localhost访问,实例的部署密度平衡,碎片化剩余的资源最小化
诞生于平安集团,由平安科技自主研发的平安云已经建设成为金融行业内最大的云平台,涵盖平安集团95%以上的业务公司,支撑80%的业务系统投产。并以金融为起点,深度服务于金融、医疗、智慧城市、房产、汽车五大生态圈,作为平安服务的综合输出平台为全行业提供IaaS(基础设施服务)、PaaS(通用平台服务)、SaaS(软件应用服务)全栈服务。
热门
云以致用 智造未来
奖项
平安云大事记
新闻
平安科技CEO陈立明发表演讲
以上是关于浅谈基于平安云容器集群服务(PKS)的全链路压测调优实践的主要内容,如果未能解决你的问题,请参考以下文章