稳定性全系列——如何做线上全链路压测
Posted 品质出行技术
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了稳定性全系列——如何做线上全链路压测相关的知识,希望对你有一定的参考价值。
小编推荐:稳定性全系列,作者结合自身多年稳定性工作经验,带你快速了解线上全链路压测方案的设计和落地。
如今,在微服务架构盛行的互联网时代,微服务架构下模块(本文指可独立部署的服务)之间的关系错综复杂(哪怕是避免模块之间的直接循环依赖都很变得困难),评估一整套业务系统(集群)的容量已经不像评估单机系统那样容易,而系统的容量评估,是稳定性建设的核心内容之一,是我们绕不开的主题。
有了系统容量评估,配合今年的业务目标,我们才知道应该申请多少预算、什么时候需要扩容、系统瓶颈在哪、哪些服务(模块)需要扩容。评估系统容量或者准确的说评估线上系统的容量现阶段最优效也是最准确的方式就是进行线上全链路压测。
你要问实现线上全链路压测难不难?当然难(现阶段稳定性工作哪一项不难?),但依然有迹可循。而且和当前技术体系的系统化建设程度以及各团队之间协作有关系。想实现线上全链路压测,我们需要做如下三个方面的准备工作(为了描述简单,本文的“全压”指的是线上全链路压测):
-
确定需要哪些团队参与 -
确定全压技术方案 设定全压目标和计划
▌确定需要哪些团队参与
全压绝对是一项耗时耗力的工程,特别是刚开始的时候。首当其冲的当然是得到老大的支持,一般需要参与进来的至少有研发、测试和运维三个团队。研发团队主要负责技术方案的设定和实施(当然如果有架构组或中间件团队,技术方案的设定可以交给他们),测试团队负责验证全压方案和数据的正确性以及真正的施压,而运维团队需要关注压测对线上集群的影响以及一些辅助工作(例如提前调整网关的限流阈值)。
▌确定全压技术方案
这一步应该是难度最大的,不同技术体系具体实施方案当然不一样,但可以相互参考,就拿我的业务部门举例,我们服务端是Java栈,整个业务流量符合如下链路:
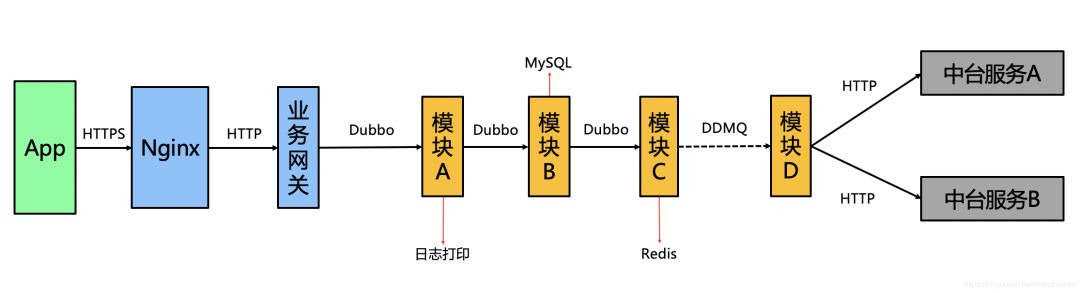
上图最左边的App指的是用户手机中装的App,从后面的链路我们可以看出,业务网关后面就是我们的服务端系统,各模块之间使用Dubbo来进行交互,当然异步用的是DDMQ,而当模块需要使用集团的中台服务时,我们使用的是HTTP。模块内部还使用了线程池,也使用了mysql、Redis等外部服务。
第一步,确定“全链路”应该包含链路(或顶级接口),所谓的全链路,它其实是一个相对的概念,在刚开始做全压时,我们主要是把线上的核心链路找出来,找到这些链路的顶级接口,这其实就是发压的主要入口。
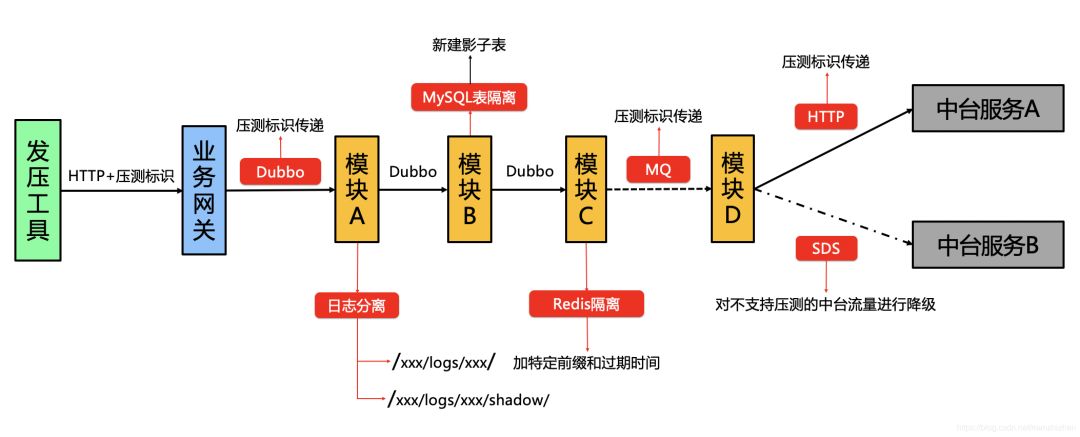
第二步,确保压测标识在这些链路中传递以及处理,第二步是最难的也是最复杂的,我们要分析第一步中这些链路中如何有效安全的传递压测标识,压测标识是系统中用来区分压测流量还是线上正常流量的标识,我们要保证压测标识正确的传递和清除,否则可能导致严重的线上事故。这里将给出我们的做法,供大家参考,主要分四大部分:
尽可能的对模块无侵入或低侵入
微服务架构下可独立你部署的模块数可能会非常惊人,任何能成功实时的技术方案都应该要求是对业务模块是无侵入或者是低侵入的,否则将影响方案的推广以及实施成本,我们为了做到这一点,打算直接在我们的基础组件(内部使用的公共库和中间件)动刀子,尽可能的对用户透明。
压测标识安全的传递和处理
这个要分模块内、模块间、模块外三个部分来考虑:
模块内:假如模块内部已经知道该流量是压测流量,我们如何保证该压测流量能在模块内部复杂的逻辑处理中不丢失?模块内主要考虑的是线程中和跨线程执行的时候,压测标识容易丢失,线程中,我们使用的是对ThreadLocal的包装类(我们没使用阿里开源的TransmittableThreadLocal)。而为了能够跨线程传递,我们修改了taxi-thread公共库,将其中的TaxiThreadPoolExecutor等类进行了修改,加入了压测标识的传递(这里补充下背景,我们为了traceId能跨线程传递,在taxi-thread公共库中包装了JDK线程池相关的类,并在开发规范中要求研发同学不能直接使用JDK原生的线程池)。还有一块,就是日志打印,为了能准确区分压测流量和正常流量,也为了压测流量不污染线上数据(比如线上很多模块有埋点日志),我们修改了taxi-log(我们这边没有直接使用SLF4J,而是使用包装过的日志公共库taxi-log),将压测流量所有的日志打在原日志目录下的shadow影子目录下,这一切对用户也是透明的。
模块间:我们这边模块间的通讯方式主要是Dubbo和DDMQ,Dubbo这块的话我们直接通过Filter来实现压测标识传递,而DDMQ本身就自带压测标识传递方式,可以直接使用。
模块外:这一部分主要是存储、缓存以及一些外部服务(比如上图的中台服务)。
存储例如MySQL、MongoDB等,我们必须要隔离压测和线上数据,所以我们会事先建好所谓的影子表,影子表其实和线上表的区别就是表名,影子表会在真实表名前加一个shadow_前缀,而我们的taxi-mybatis、taxi-mongo等公共库在识别到压测标识时,会给表或者文档名称前也带上shadow_前缀。之所以只是做表隔离而没有做库级别隔离,考虑到的还是降低侵入性和成本。关于存储,还有一个关键点,假如模块只提供查询服务(比如某些配置中心),如果按照前面说的,存储接入压测标识这块做成无侵入的话,全压流量查询也会走影子表,这也许是我们不希望看到的,所以在MySQL这块我们特意做成有侵入的(需要加一个插件配置),否则默认不识别压测标识。
对于分布式缓存,我们使用的是Redis,这一块的处理方式和存储类似,我们修改了我们自己Redis包装的公共库,如果是识别到压测标识,默认在操作的key上加一个shadow_前缀,保证压测流量不污染线上缓存数据。
对于外部服务,我们使用的是HTTP来调用,所以修改了我们taxi-util中的HTTP组件,做了压测标识的传递,保证下游外部服务能知道这是压测流量。那肯定有人问,如果下游服务不支持压测流量识别该咋办?所以这里我们借助了SDS服务降级系统(https://github.com/didi/sds),可以只对压测流量进行拦截,使其不调用下游外部服务。
最后的效果如下:
第三步,确保全压流量能被监控到,这涉及到我们在实际全压中能否直观的感受到压测流量,这一块需要和内部的监控系统来打通,由于能方便的取到压测标识,这一块的实现我们不再阐述。
第四步,准备全压数据,确定接口调用比例,最理想的方式是能对线上流量进行克隆、放大和处理,作为压测输入数据来重放,但这块难度较大,需要有好的平台来支撑,我们目前只能使用更简单的方式来造数据。由于无法使用仿真数据,我们提前在影子表中造了一批用户、设备信息、位置等和业务相关的数据,然后去线上统计了链路上各顶级接口的流量和交易量的比例,来作为压测时流量放大的依据。当然,必不可少的还有一个发压工具或平台,例如滴滴的奥创发压平台。
▌确定全压目标和计划
截止到目前,我们已经进行过很多轮的全压,也在不断往全压中补充新的链路,加入新的模块,目前全压的人力成本还是较高,我们也在探索全自动化全压方案,到时候有成果将和大伙继续分享。
我是易振强,热爱开源,热爱分享,深耕分布式系统和稳定性建设,欢迎关注SDS服务降级系统:https://github.com/didi/sds ;也热爱生活,热爱漫画,一拳超人和海贼王都很好看!!
以上是关于稳定性全系列——如何做线上全链路压测的主要内容,如果未能解决你的问题,请参考以下文章