全链路压测在网易传媒的落地与实践
Posted 网易传媒技术团队
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了全链路压测在网易传媒的落地与实践相关的知识,希望对你有一定的参考价值。
为了快速定位问题,小分队开发了全链路追踪项目。项目核心方案:在各类请求header中增加全局唯一TraceId并可以在请求过程中不同服务之前进行透传,达到根据traceId将同一请求在不同服务中的请求数据进行关联的目的,这一项目上线后解决了线上压测面临的最大问题:无法区分正常流量和测试流量,我们利用全链路tracer agent同样实现了在测试流量header中增加压测标记,并在请求过程中跨服务进行透传。以此为基础,结合互联网各大公司使用的影子存储、流量录制等技术的实战经验,设计了适合传媒技术体系的全链路压测服务。
3.1 压测流量构建
全链路tracer agent随服务同时启动,拦截服务的所有请求并将traceId和压测标记向下游透传,同时根据分布式配置中心实时下发的配置决定是否要上报当前请求的path、headers、参数等(可指定录制的时间段),全链路追踪服务端接收请求后将数据保存到ES集群中方便后续使用。为尽量减少存储,录制开关平时默认关闭,按需开启。业界使用Tcp copy、goreplay等开源方案复制线上流量,以Tcp copy为例,局限性在于是4层流量复制,没法按照域名或接口进行过滤,一是资源浪费,二是运维部署较为复杂;我们当前的方案可以在整个调用过程中的任一环节按需获取流量,更加方便灵活。
3.2 数据污染
参考业界影子存储方案解决测试流量产生的数据污染,利用tracer agent拦截服务各类请求,包含:jdbc、redis、memcaced、kafka、rabbitmq、logback、http、rpc等,将压测流量产生的写请求写入到影子存储中。
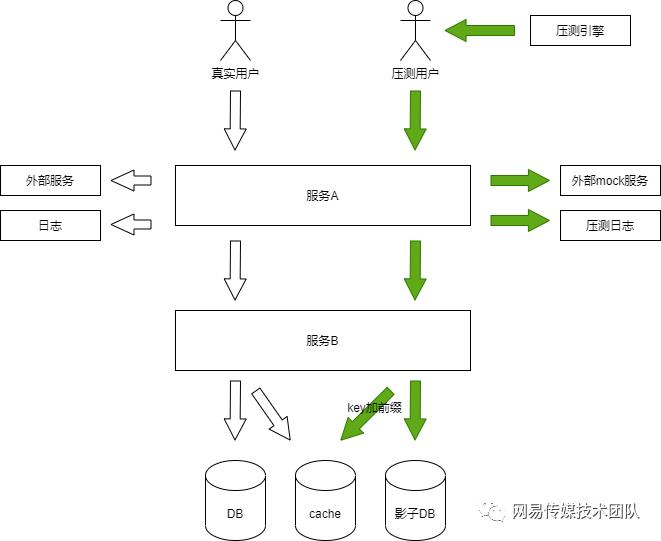
a、数据库:数据库的影子存储是拦截数据库连接后替换jdbc connection对象,保证测试流量的sql语句执行在影子db实例中,影子db实例与线上db实例保证在同一数据库集群内,保证压力测试有效;
c、日志:部分业务产生的日志可能会被大数据部门采集后制作报表或各类数据统计,目前对logback进行了支持,将测试流量产生的日志写入单独的测试日志文件中。另一种可选方案是在日志内容中增加压测标记,在日志收集处理服务中识别压测标记后丢弃,这样处理出错风险更低,但前提是用相同的日志框架并有统一的日志收集处理服务,目前网易严选团队采用的是这种方案;
d、消息队列:所有应用使kafka和rabbitmq因为暂时业务使用版本不统一,低版本无法透传压测标记,目前方案是遇到压测流量产生的消息统一丢弃不做处理;
e、其它:需要特殊注意的是:java本地内存读写是无法拦截和做影子存储方案的,需要在压测前与业务方确认,做代码侵入式的做响应的修改;
以HikariDataSource数据连接池为例,大概介绍一下具体的数据库的影子逻辑实现方式。
private void addHikariInterceptor() {this.transformTemplate.transform("com.zaxxer.hikari.HikariConfig", new TransformCallback() {@Overridepublic byte[] doInTransform(Instrumentor instrumentor, ClassLoader classLoader, String className,Class<?> classBeingRedefined, ProtectionDomain protectionDomain, byte[] classfileBuffer)throws InstrumentException {InstrumentClass target = instrumentor.getInstrumentClass(classLoader, className, classfileBuffer);InstrumentMethod setJdbcUrlMethod = InstrumentUtils.findMethod(target, "setJdbcUrl",String.class.getName());setJdbcUrlMethod.addInterceptor(SetJdbcUrlInterceptor.class.getName());return target.toBytecode();}});addGetConnectionInterceptor("com.zaxxer.hikari.HikariDataSource", TransformHandler.EMPTY_HANDLER);}private void addGetConnectionInterceptor(String className, TransformHandler handler) {this.transformTemplate.transform(className, new TransformCallback() {@Overridepublic byte[] doInTransform(Instrumentor instrumentor, ClassLoader classLoader, String className,Class<?> classBeingRedefined, ProtectionDomain protectionDomain, byte[] classfileBuffer)throws InstrumentException {InstrumentClass target = instrumentor.getInstrumentClass(classLoader, className, classfileBuffer);handler.handle(target);InstrumentMethod getConnectionMethod = InstrumentUtils.findMethod(target, "getConnection");getConnectionMethod.addInterceptor(JdbcInterceptor.class.getName());return target.toBytecode();}});}
@Overridepublic Ret before(Object target, Object[] args) {SofaTracerSpan span = SofaTraceContextHolder.getSofaTraceContext().getCurrentSpan();if (span != null && span.getSofaTracerSpanContext().isLoadTest()) {Object testDb = DataSourceHolder.getInstance().getLoadTestDb(target);if (testDb != null) {DataSource dateSource = (DataSource)testDb;try {return Ret.newInstanceForReturn(dateSource.getConnection());} catch (SQLException e) {if (logger.isWarnEnabled()) {logger.warn("Failed to getConnection. {}", e.getMessage(), e);}}}if(DataSourceHolder.getInstance().isLoadTestDb(target)) {//压测数据源拦截不处理,返回nonereturn Ret.newInstanceForNone();}else {//数据源无配置或者有异常,则返回null,保证压测不影响数据库正常逻辑return Ret.newInstanceForReturn(null);}}return Ret.newInstanceForNone();}
3.3 压测风控
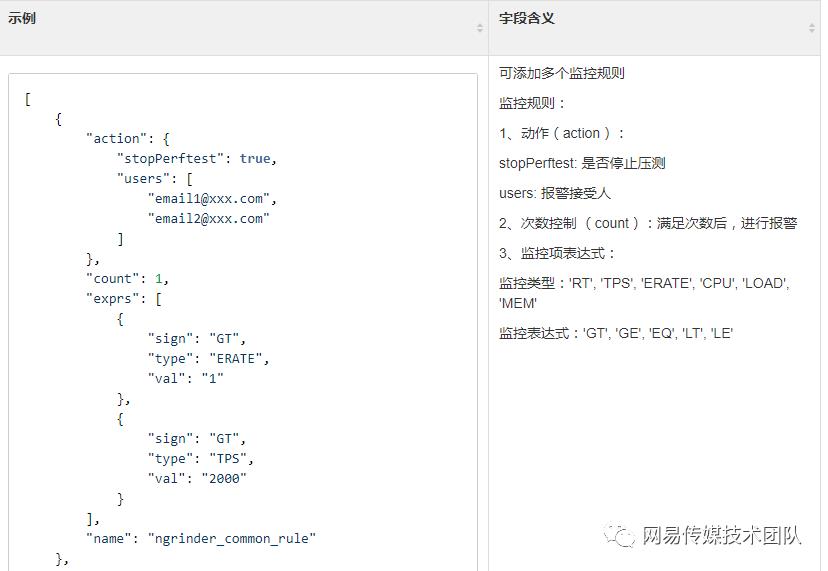
与集团内部统一监控平台打通,用户可在压测平台设置停止规则,随时监控压测链路各服务监控数据,达到阈值后自动停止压测流量(QPS、错误率等业务指标手工设置,CPU、内存等通用指标默认提供兜底规则)。
停止规则为JSONArray格式,每个规则可单独配置关注用户,大概结构如图:
3.4 压测平台建设
压测平台跟踪压测流程,流量录制、发送、停止规则设置等操作全部界面化,简单设置后自动执行,完成后生成压测报告。平台规范用户操作习惯,为了防范线上压测风险,所有压测必须先在测试环境预演,没问题之后线上小流量验证再开始压测。
压测标记和影子存储采用java agent实现,不侵入业务代码
录制真实线上流量,仿真度高且可以录制足够的请求量,测试同学只需要按需做简单调整即可投入使用,不再需要开发脚本进行数据准备
根据停止规则自动化停止压测流量,避免影响线上用户
压测平台可视化操作流程,大幅节省测试团队操作成本
降低压测成本,主要体现在以下几方面:
过往经验,压测开始前需手工梳理被压接口调用链路,全链路追踪项目生成接口调用拓扑图来圈定压测影响的各类服务,方便测试同学关注受影响的集群并设置停止规则;
录制线上流量用作压测,无需手工构造,压测平台提供host、参数、path、header等流量转换功能;
自动生成压测报告,给出初步分析结果;
容量评估
利用全链路线上压测可以完成两种目标:1.制定目标qps,达标即停止;2.探测qps极限值,集群某类资源达到上限才停止。获取qps极限值数据后,我们可根据需要调整集群内节点数量:极限值远高于预期值,集群节点数可减少;极限值与预期值较为接近则可能无法应对流量突发高峰,需要扩容。如果压测可以常态化,则可以根据业务变化随时调整各集群间资源配置,更好的应对业务需要。故障演练
服务在各环节增加了应对不同场景的降级、流控、熔断功能,在问题发生时是否可以按预期响应,之前这类测试的成本也很高。我们可以利用全链路压测在流量低峰期模拟各环节故障,以达到检验服务稳定性的目标。
传媒各服务会逐步接入service mesh,将影子存储等相关压测功能迁移到mesh中,优雅解决跨语言全链路压测(目前功能主要针对java项目),且代码迭代不再需要业务方升级和重新部署;
开发工具来简化压测前铺底数据同步成本,缩短压测前准备时间;
压测过程中各类监控项中异常数据的算法识别和监测,不再依赖阈值和人工识别,提高线上问题识别的准确率和召回率;
增加工单化的压测审批流程,责任落实到具体负责人;
配合测试团队建立压测结果评分系统并将线上压测常态化,根据压测评分反推各开发团队提高服务质量;
以上是关于全链路压测在网易传媒的落地与实践的主要内容,如果未能解决你的问题,请参考以下文章