小白入门hadoop,必不可少的hadoop基础知识
Posted 有趣的数据灵魂
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了小白入门hadoop,必不可少的hadoop基础知识相关的知识,希望对你有一定的参考价值。
刚开始学hadoop的时候,觉得理论还挺好理解的,但是实践起来的时候真的是very very very difficult !(真心建议小白入门一定要打好基础!!!)
你问我什么是hadoop?说真的,我很难说得上来,因为我还没有学到精髓!下面是我在网上搜索的介绍。(有什么不懂就问度娘的真实)
Hadoop是一个由Apache基金会所开发的分布式系统基础架构。
用户可以在不了解分布式底层细节的情况下,开发分布式程序。充分利用集群的威力进行高速运算和存储。
Hadoop实现了一个分布式文件系统(Hadoop Distributed File System),简称HDFS。HDFS有高容错性的特点,并且设计用来部署在低廉的(low-cost)硬件上;而且它提供高吞吐量(high throughput)来访问应用程序的数据,适合那些有着超大数据集(large data set)的应用程序。HDFS放宽了(relax)POSIX的要求,可以以流的形式访问(streaming access)文件系统中的数据。
Hadoop的框架最核心的设计就是:HDFS和MapReduce。HDFS为海量的数据提供了存储,则MapReduce为海量的数据提供了计算。
话不多说,直接上知识!!!(说明这是我自己根据我们老师上课的时候总结,都是一些非常基础的知识),喜欢的朋友们希望点赞在看支持一下啦!!
♚Hadoop的认识
1.hadoop是google公司三篇论文思想的实现
①hdfs—gfs
②mapreduce-mapreduce
③hbase-bigtable
2.hadoop版本的演变
经历三代,与一代相比二代最明显变化增加yarn
3.hadoop特点
①高可靠性②高拓展性③高效性④高容错性
4.狭义的hadoop包括:hdfs、mapreduce、yarn
5.广义的hadoop是一个很庞大的体系,具有众多组件
6.hadoop的应用场景:①旅游行业②移动数据③电子商务④能源开发⑤节能⑥基础框架管理⑦图像处理⑧诈骗检测⑨IT安全⑩医疗保健
7.hadoop的应用架构:(自下而上)①数据来源层②数据传输层③数据存储层④编程模型层
⑤数据分析层⑥上层业务
♚Hadoop生态圈常用组件及其功能
☞HDFS 分布式文件系统
☞YARN 资源管理和调度器
☞MapReduce 分布式并行编程模型
☞HBase Hadoop上的非关系型的分布式数据库
☞Hive Hadoop上的数据仓库
☞Pig 一个基于Hadoop的大规模数据分析平台,提供类似SQL的查询语言Pig Latin
☞Flume 一个高可用的,高可靠的,分布式的海量日志采集、聚合和传输的系统
☞Sqoop 用于在Hadoop与传统数据库之间进行数据传递
☞Zookeeper 提供分布式协调一致性服务
☞Ambari Hadoop快速部署工具,支持Apache Mahout Hadoop集群的供应、管理和监控☞Spark 提供一些可扩展的机器学习领域经典算法的实现
☞Oozie 类似于Hadoop MapReduce的通用并行框架 Hadoop上的工作流管理系统
☞Storm流计算框架
☞Kafka一种高吞吐量的分布式发布订阅消息系统,可以处理消者规模的网站中的所有动作
♚Hadoop的三种安装模式及特点和用途
⑴安装模式
①单机模式(Standalone Mode):Hadoop 运行在一台主机上,按默认配置以非分布式模式运行一个独立的 Java 进程
②伪分布式模式(PseudoDistributedMode):Hadoop 运行在一台主机上,使用多个Java 进程,模仿完全分布式的各类节点
③完全分布式模式(Fully-DistributedMode):完全分布式模式也叫集群模式,是将 Hadoop运行在多台主机中,各个主机按照相关配置运行相应的 Hadoop 守护进程
⑵三种模式的特点及用途
①单机模式:没有分布式文件系统,直接在本地操作系统的文件系统读/写;不需要加载任何Hadoop的守护进程。用于本地 MapReduce 程序的调试。它是Hadoop的默认模式。
②伪分布式模式:Hadoop 运行在一台主机上,使用多个 Java 进程,模仿完全分布式的各类节点。伪分布式模式具备完全分布式的所有功能,常用于调试程序。
③完全分布式模式(Fully-Distributed Mode):完全分布式模式是真正的分布式环境,用于实际的生产环境。
♚Hadoop伪分布式模式安装前准备工作和安装过程
①准备工作:安装虚拟机→安装Ubuntu操作系统→关闭防火墙→安装SSH→安装Xshell
和xftp→安装jdk→下载hadoop并且解压
♚请简述副本冗余存储策略
HDFS 默认保存 3 份副本。
(1)第一个副本(副本一):放置在上传文件的数据节点;如果是在集群外提交,则随机挑选一台磁盘不太满、CPU 不太忙的节点。
(2)第二个副本(副本二):放置在与第一个副本不同的机架的节点上。
(3)第三个副本(副本三):放置在与第二个副本相同机架的其他节点上。如果还有更多副本,这些副本会随机选择节点存放。
♚HDFS shell管理命令(hdfs dfs)
①创建文件夹
↪hdfs dfs -mkdir
②列出指定的文件和目录
↪hdfs dfs -ls
③新建文件
↪hdfs dfs -touchz
④将本地文件上传到HDFS
↪hdfs dfs -put本地文件路径 HDFS路径
↪hdfs dfs -copyFromLocal 本地文件路径 HDFS路径
⑤将本地文件移动到HDFS
↪hdfs dfs -moveFromLocal 本地文件路径 HDFS路径
☞与“hdfs dfs -copyFromLocal”命令不同的是,此命令将文件复制到HDFS后,本地的文件会被删除
⑥下载文件
↪hdfs dfs -get HDF文件的完整路径
hdfsdfs-copyToLocal[-p][-ignoreCrc][-c
♚NameNode的职责
名称节点(NameNode) 是HDFS的管理者,它的职责有3个方面:
①负责管理和维护HDFS的命名空间(NameSpace),维护命名空间中的两个重要文件——
edits和 fsimage
②管理DataNode上的数据块(Block),维持副本数量
③接收客户端的请求,比如文件的上传、下载、创建目录等
♚DataNode的职责
①保存数据块
②负责客户端对数据块的I0请求
③定期向NameNode发送心跳信息,接受NameNode的指令
♚HDFS HA与联邦的区别
①HDFS HA是配置两个NameNode:一个是Active状态 ,另一个是Standby状态。两个
NameNode的内存中各自保存一份元数据。一旦Active的NameNode宕机,Starndby的NameNode就变成Active ,接替原来的NameNode。
②HDFS Federation是HDFS有多个NameNode或NameSpace ,这些NameNode或NameSpace是联合的,它们相互独立且不需要互相协调,各自分工,管理自己的区域,一个NameNode挂掉了,不会影响其他NameNode ,但是每个NameNode还是存在单点故障问题。
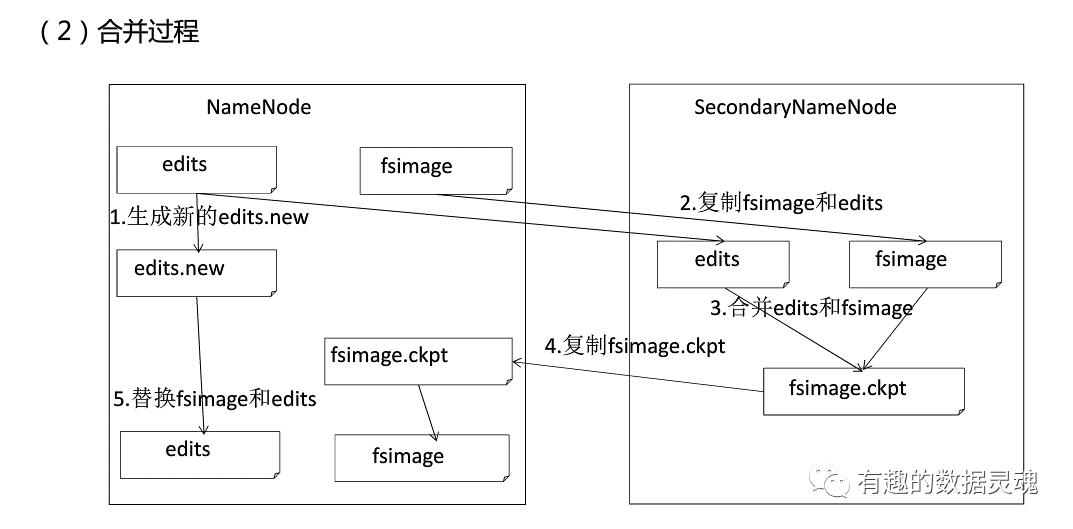
♚简述fsimage和edits文件合并的过程
①SecondaryNameNode 会定期与 NameNode 通信,请求其停止使用 edits 文件,暂时将新的更新操作写到一个新的文件 edits.new 上,这个操作是瞬间完成的。
②SecondaryNameNode 通过 HTTPGET 方式从 NameNode 上获取 fsimage 和 edits文件,并下载到本地的相应目录下。
③SecondaryNameNode 将下载下来的 fsimage 载入内存,然后一条一条地执行 edits文件中的各项更新操作,使得内存中的 fsimage 保持最新,这个过程就是将 edits 和fsimage 文件合并。
④SecondaryNameNode 执行完③操作之后,会通过 HTTPPOST 方式将新的 fsimage文件发送到 NameNode 节点上。
⑤NameNode 用从 SecondaryNameNode 接收到的新的 fsimage 文件替换旧的fsimage 文件,同时将 edits.new 文件更名为 edits
♚MapReduce 1和Yarn的区别
①MapReduce1由JobTracker负责作业调度与任务监控,而Yarn由 ResourceManager负责作业调度,Application Master负责任务监控
②MapReduce1的任务节点叫做TaskTracker,而Yarn的任务节点为NodeManager
③MapReduce1的资源调配单元为Slot,而Yarn的资源调配单元为Container
④MapReduce 1在节点数达到4000,任务数达到40000就会遇到扩展瓶颈,而Yarn 节点数可达到10000个节点,任务数可达到100000个
♚MapReduce的模型要点
(Map方法:每个文件分片由单独的主机处理
Reduce方法:将各个主机计算的结果进行汇总并得到最终结果)
①任务Job = Map + Reduce
②Map的输出是Reduce的输入
③所有的输入和输出都是<Key Value>形式
<k1,v1>是Map的输入 <k2,v2>是Map的输出
<k3,v3>是Reduce的输入 <k4,v4> 是Reduce的输出
④k2=k3, v3是一个集合, v3的元素就是v2
⑤所有的输入和输出的数据类型必须是hadoop的数据类型(实现Writable接口)
Integer-> IntWritable Long -> LongWritable
String-> Text null ->Nul/Writable
⑥ MapReduce处理的数据-般都是HDFS的数据(或HBase )
♚简述MapReduce设计思想
MapReduce 采用“分而治之”思想,把对大规模数据集的操作,分发给一个主节点管理下的各个子节点共同完成,然后整合各个子节点的中间结果,得到最终的计算结果
简而言之, MapReduce 就是“分散任务,汇总结果”
总而言之分为三点:
①对付大数据并行处理:分而治之
②上升到抽象模型:Map与Reduce
③上升到构架:以统一构架为程序员隐藏系统层细节
♚MapReduce的特点
①易于编程②良好的扩展性③高容错性④擅长对PB级以上海量数据进行离线处理
♚简述行式存储与列式存储的优缺点
☞行式存储
优点:数据被保存在一-起,INSERT/UPDATE容易
缺点:选择(Selection)时即使只涉及某几列,所有数据也都会被读取。列数不能太多,一般不能超过30列
☞列式存储
优点:查询时只有涉及到的列会被读取。任何列都能作为索引。相同列的数据存放在一起, 数据压缩容易。列数可以很多
缺点:选择完成时,被选择的列要重新组装。INSERT/UPDATE比较麻烦。
以上是关于小白入门hadoop,必不可少的hadoop基础知识的主要内容,如果未能解决你的问题,请参考以下文章