打怪升级之小白的大数据之旅(四十一)<大数据与Hadoop概述>
Posted GaryLea
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了打怪升级之小白的大数据之旅(四十一)<大数据与Hadoop概述>相关的知识,希望对你有一定的参考价值。
打怪升级之小白的大数据之旅(四十)
Hadoop概述
上次回顾
- 好了,经过了java,mysql,jdbc,maven以及Linux和Shell的洗礼,我们终于开始正式进入大数据阶段的知识了,首先我会为大家带来Hadoop相关的知识点,Hadoop是大数据框架中最最基础的一个,也是最好入门的一个
- 学习大数据框架前,我们首先要知道,大数据是什么?OK,让我们带着问题正式开始心心念念的大数据旅程吧~
大数据概述
大数据概念

大数据是什么?
- 首先是官方的解释:
- 大数据指无法在一定时间范围内用常规软件工具进行捕捉、管理和处理的数据集合,是需要新处理模式才能具有的更强的决策力、洞察力发现力和流程优化能力的海量、高增长和多样化的信息资产
- 是不是一头雾水?其实很简单,大数据就是用于存数据和分析数据,而主要特点就是数据量特别大
数据规模
- 说起数据量大,我先为大家科普一下数据存储的单位,前面Java基础讲过数据的存储单位,现在我再完善一下
- 数据的存储,按照大小排序,分别是:
bit Byte KB MB GB TB PB EB ZB YB BB NB DB - 我们知道,bit到byte的换算是1byte=8bit,其他的都是1024,在目前的现实生活中,一些大的企业,其数据已经接近EB量级了,这是一个什么概念呢?
- 我们现在的笔记本硬盘通常都是1T,而EB数据量的公司,他们就相当拥有102410241024块1T的硬盘
- 大数据的服务器是以机房存在的,它有很多的服务器,每台服务器我们就可以理解为一台电脑

大数据的特点
大数据的特点我们通常称为4V
-
大量 volume
- 我们每天都会产生大量的数据,据不完全统计。从人类有文字记录开始计算至今,全球人类生产的所有纸质的印刷材料数据为近200PB,从人类会说话至今,全球人类总共说过的话数据量大约是5EB

- 我们每天都会产生大量的数据,据不完全统计。从人类有文字记录开始计算至今,全球人类生产的所有纸质的印刷材料数据为近200PB,从人类会说话至今,全球人类总共说过的话数据量大约是5EB
-
高速 velocity
- 大数据区分于传统数据的显著特征就是高速,举个例子
- 天猫双十一在2016年零点开始用了6分28秒,交易额超过100亿
- 天猫双十一在2017年零点开始用了3分01秒,交易额超过100亿
- 天猫双十一在2019年零点开始用了1分36秒,交易额超过100亿
- 2020年天猫从11月1号就开始了活动,并没有统计秒杀…这个数据我没找到
- 上面里案例就是高速大家,在海量的数据面前,处理数据的效率就是企业的生命

- 大数据区分于传统数据的显著特征就是高速,举个例子
-
多样 variety
- 数据是多种多样的,比如每天说的话,浏览网页的记录,每个摄像头记录的视频、图片,电商网站中用户产生的浏览记录等等,以前我们存储数据都是使用mysql这种关系型数据库,随着时代的发展,数据越来越多样化
- 根据数据的多样性我们可以将数据分为结构化数据和非结构化数据,这在前面mysql中我提到过,结构化数据就是安装规则存储的例如mysql,而非结构化数据,如网络日志、视频、图片、地理位置信息等,是存储在nosql数据库中

-
低密度 value
- 数据量大带来的就是数据价值的低密度性,比如在某个马路的摄像头监控中,我们要找到需要的某一秒钟的某个人,如果只是靠传统技术,那是非常困难的,如何有效地对有价值数据提纯,就是我们今后大数据工作中必不可少的工作之一
- 数据量大带来的就是数据价值的低密度性,比如在某个马路的摄像头监控中,我们要找到需要的某一秒钟的某个人,如果只是靠传统技术,那是非常困难的,如何有效地对有价值数据提纯,就是我们今后大数据工作中必不可少的工作之一
大数据的应用场景
大数据的应用场景有很多,我就列举集合我们经常性遇到的应用场景
- 京东物流
- 上午下单下午送达,下午下单次日上午送达
- 京东根据用户购买的习惯,通过大数据分析出在一个区域内用户经常买的商品,然后将这些商品存放在附近区域的京东仓库中。这样就可以实现快速的物流
- 推荐
- 我们常见的推荐系统就是根据大数据来推送出用户感兴趣的东西,比如电商的推送
- 抖音的视频推荐算是我见识中的最厉害的,我有一个朋友他没事就喜欢看各种好看的小姐姐,现在他的抖音已经养成了,一打开怎么划基本上都是小姐姐…哈哈
- 金融
- 大一些的金融公司都会做量化交易来辅助进行金融分析,量化交易就是通过大量的数据来分析以前某只公司股票的走势以及相关信息,从而推断他未来的发展情况
- 大一些的金融公司都会做量化交易来辅助进行金融分析,量化交易就是通过大量的数据来分析以前某只公司股票的走势以及相关信息,从而推断他未来的发展情况
大数据的业务流程&部门组织结构
介绍完大数据的概念、特点与应用场景后,接下来我来介绍一下大数据在工作中的业务流程与工作的部门结构
- 业务流程
- 产品人员提需求,例如统计总用户数、日活跃用户等
- 数据部门搭建数据平台、分析数据指标(这个就是我们要做的工作)
- 数据可视化(大屏展示、报表推送等)
- 部门组织结构
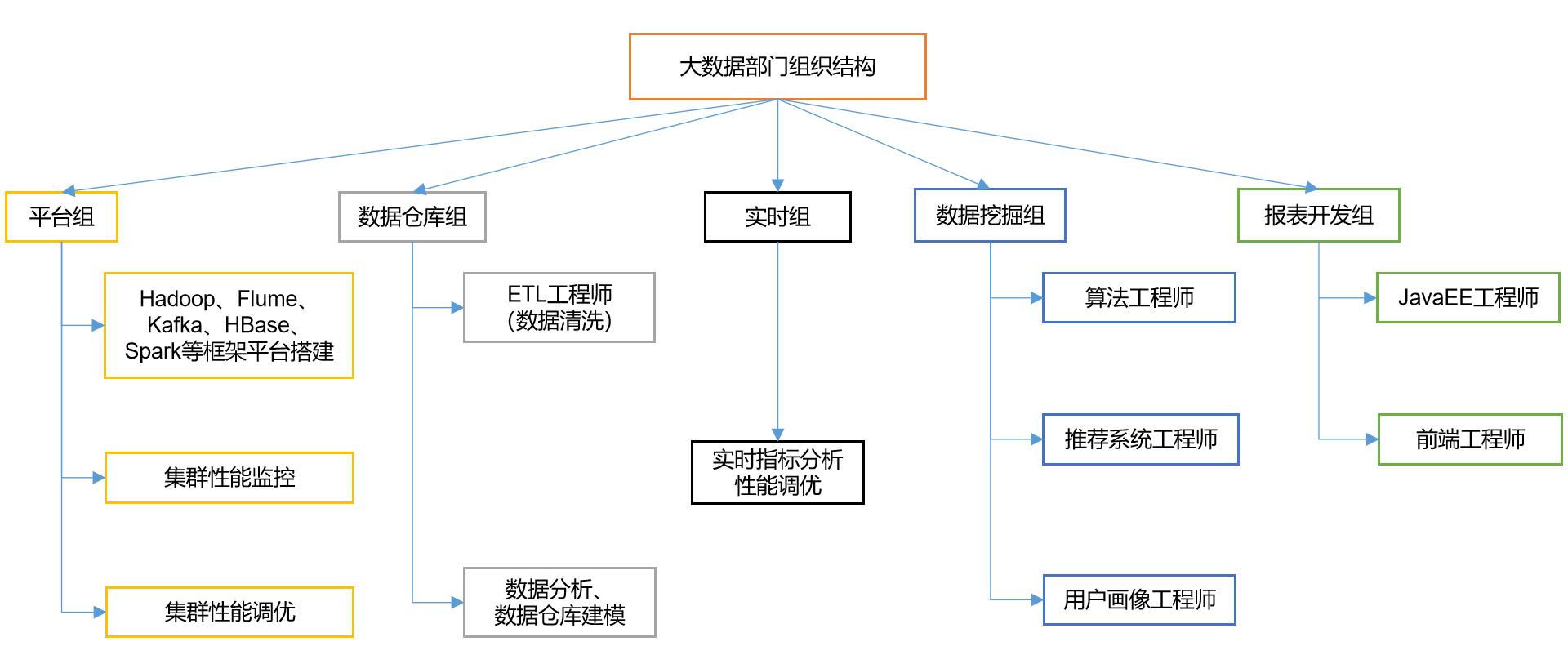
- 平台组:主要是搭建大数据的平台,监控大数据集群的性能以及性能的调优
- 数仓组(数据仓库组):主要是做数据清洗和数据分析,将低密度的数据进行过滤处理,获取到有价值的信息,一般数仓组的数据都是离线数据,比如前一天的数据,去年的数据等
- 实时组:主要是对实时的数据进行处理,比如抖音的推荐电商的推荐,当用户浏览某个信息就可以实时进行数据的推送
- 数据挖掘组:这个也是我的终极梦想,它是大数据工作中最难的一个,要求也很高,一般推荐系统工程师学历都是博士…(所以是梦想),数据挖掘也会使用各种算法进行数据建模,通过人工智能来实现针对实际需求的推荐系统
- 报表开发组:这个就是JavaEE工程师和前端小姐姐的工作,主要将我们处理的数据进行展示
- 好了,大数据的知识点就介绍这么多,下面我们进入第一个大数据框架Hadoop的学习,他是最简单的大数据框架,特别适合入门。所以不要担心
Hadoop概述
Hadoop的创始人是人称Hadoop之父的Doug Cutting,Apache软件基金会主席,是Lucene、Nutch 、Hadoop等项目的发起人
通过Hadoop来介绍大数据生态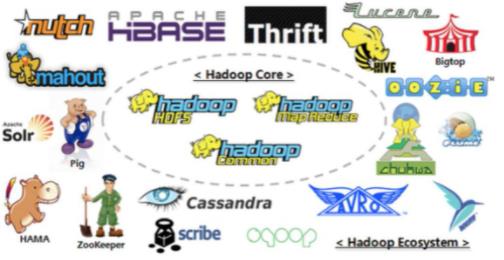
- Hadoop是一个由Apache基金会所开发的分布式系统基础架构
- Hadoop主要用于海量数据的存储和海量数据的分析计算问题
- Hadoop通常指的是Hadoop生态圈
- Hadoop就像我们前面学习的Linux,首先有个大牛写了一个Linux内核,然后各种各样的大牛对其进行扩展,Hadoop也是如此
- Hadoop有三个重要的知识,这些后面会一 一讲到
- HDFS: 用于数据的存储
- MR(MapReduce):用于数据的处理
- HBase: 分布式的存储系统
Hadoop的发行版本
- 发现版本就和我在Java开篇介绍的一样,分为免费开源的,收费的,我介绍的知识点就是基于免费开源的Apache版本
- Hadoop三大发行版本:Apache、Cloudera、Hortonworks。
- Apache版本最原始(最基础)的版本,对于入门学习最好。
- Cloudera内部集成了很多大数据框架。对应产品CDH。
- Hortonworks文档较好。对应产品HDP
- 目前Hortonworks已经被Cloudera收购了,后面两个都是收费的
Hadoop官网&下载地址
- 官网可以辅助我们学习Hadoop的学习,大家记得收藏一下。下载地址中,有源码和完整版两个版本,我们直接下载完整版那个即可,在下一章搭建Hadoop的时候直接解压缩就可以使用了
官网地址:http://hadoop.apache.org/releases.html
下载地址:https://archive.apache.org/dist/hadoop/common/
Hadoop的优点
Hadoop有四大优势
- 高可靠性
- Hadoop底层维护了多个数据副本,即使Hadoop某个计算元素或存储故障也不会导致数据的丢失
- 高扩展性
- Hadoop可以在集群间分配任务数据,可以很方便的扩展很多的节点
- 高效性
- Hadoop是并行工作的,可以大大提高任务处理的速度
- 假设我有1000万条数据,在一台电脑上按照某个规则进行处理需要10个小时,我使用了Hadoop创建了一个集群,10个节点,就会将处理速度提到到1个小时
- 高容错性
- Hadoop能够自动地将失败的任务重新分配
扩展知识点:
- Hadoop能够自动地将失败的任务重新分配
- Hadoop服务器一般是以集群的方式的存在,也就是说它有很多台服务器共同组成,每一台服务器称之为一个节点
Hadoop的组成
我先简单介绍一下它们,后面会详细介绍
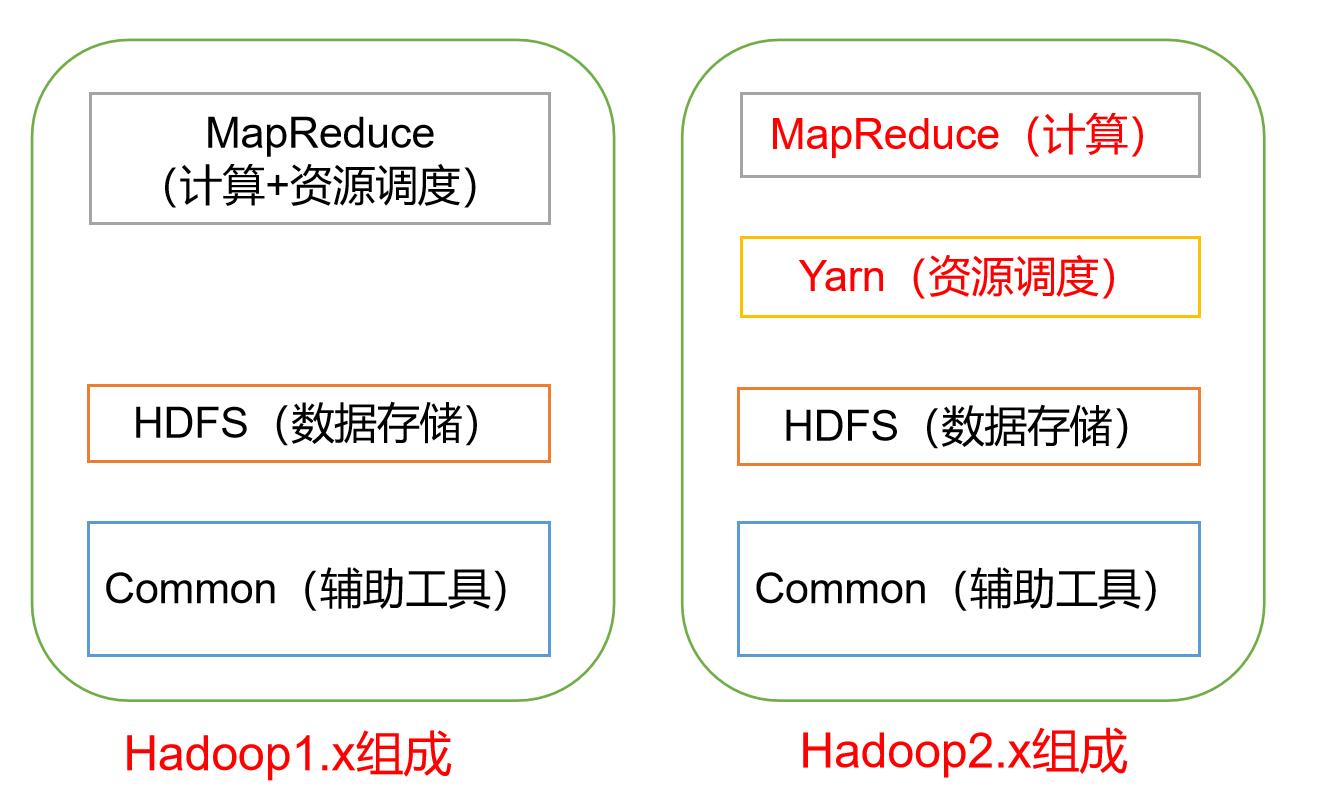
Hadoop版本从2.0之后的组成基本没有改变
Hadoop1.0
- MapReduce:在1.0中计算和资源调度在一起
- HDFS:用于进行数据的存储
- Common:用于配置文件和日志等功能
Hadoop 2.0
- MapReduce:在2.0中MapReduce仅仅只用于计算
- Yarn:将1.0的MR功能拆分出来,建立Yarn模块,专门用于资源调度
- HDFS:用于进行数据的存储
- Common:用于配置文件和日志等功能
将MR的计算与资源调度拆分的优点为:
- 大大提升了计算的效率,因为无需再关注资源调度了
- 解耦合,在1.0时,如果计算中出现问题,资源调度就会出现问题
HDFS
HDFS架构分为三大模块:NnameNode,DataNode和SecondaryNameNode,下面我会通过一个实际的案例来说明它们
- NameNode(nn)
- 存储文件的元数据(文件名,文件目录结构,文件属性,每个文件的块列表和所在的DataNode等)
- 我有一本字典,NameNode就是字典的目录,它会记录我需要查询的数据的一些信息,如拼音的字母,页码等
- DataNode(dn)
- 在本地文件系统存储文件的块数据以及快数据的校验和
- DataNode就是数据的本身,就像字典中某个字的详细信息
- SecondaryNameNode(2nn)
- 每隔一段时间对NameNode元数据进行备份
- 每过一段时间,就会对字典的目录进行更新,因为里面的数据可能会有变化
- 每隔一段时间对NameNode元数据进行备份
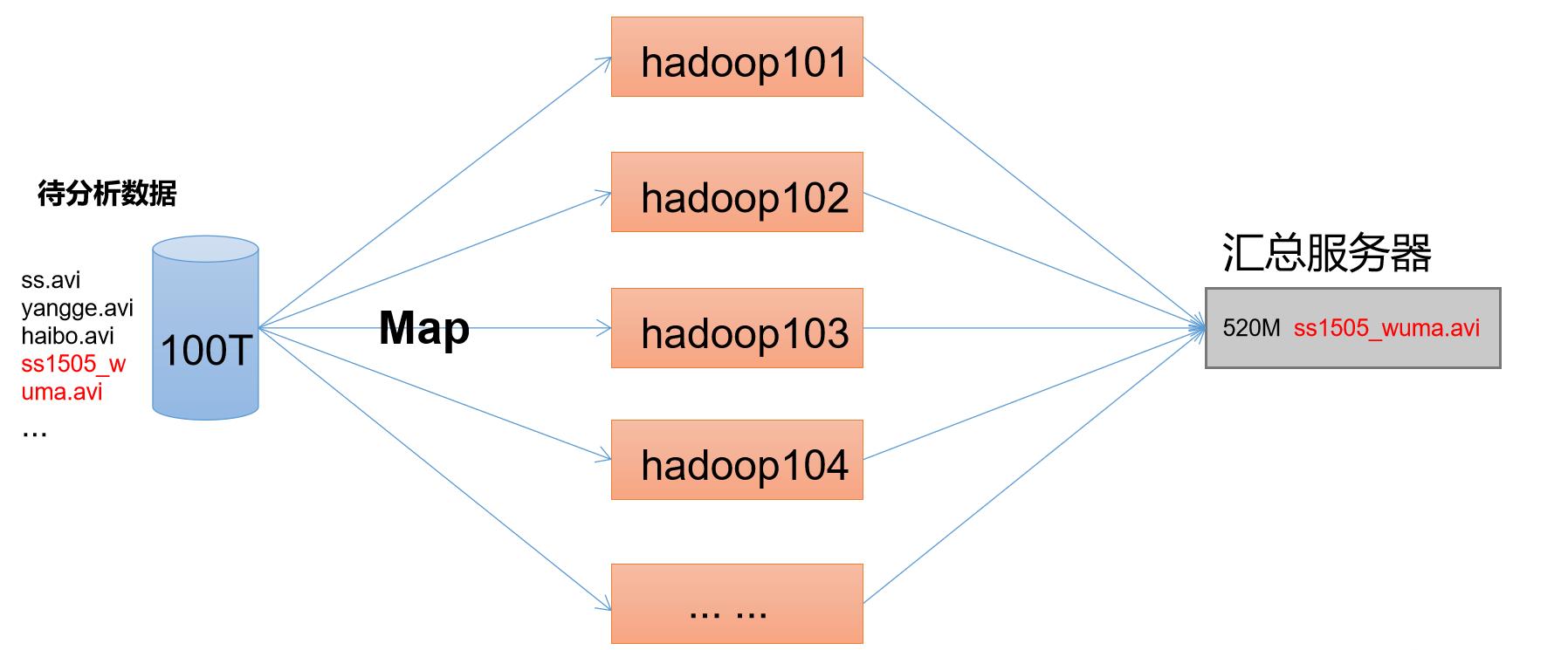
MapReduce
前面说了MR在2.0开始就专门处理数据的计算
MapReduce将计算过程分为两个阶段:Map和Reduce
- Map阶段并行处理输入数据
- Reduce阶段对Map结果进行汇总
- 例如我想在100T的视频中找到我需要的一个视频,在Map来进行处理输入的数据,然后在Reduce阶段对获取到数据进行汇总
YARN
- YARN是Hadoop2.0开始的新的一个模块,它是hadoop集群资源管理器系统,专门用于进行资源调度
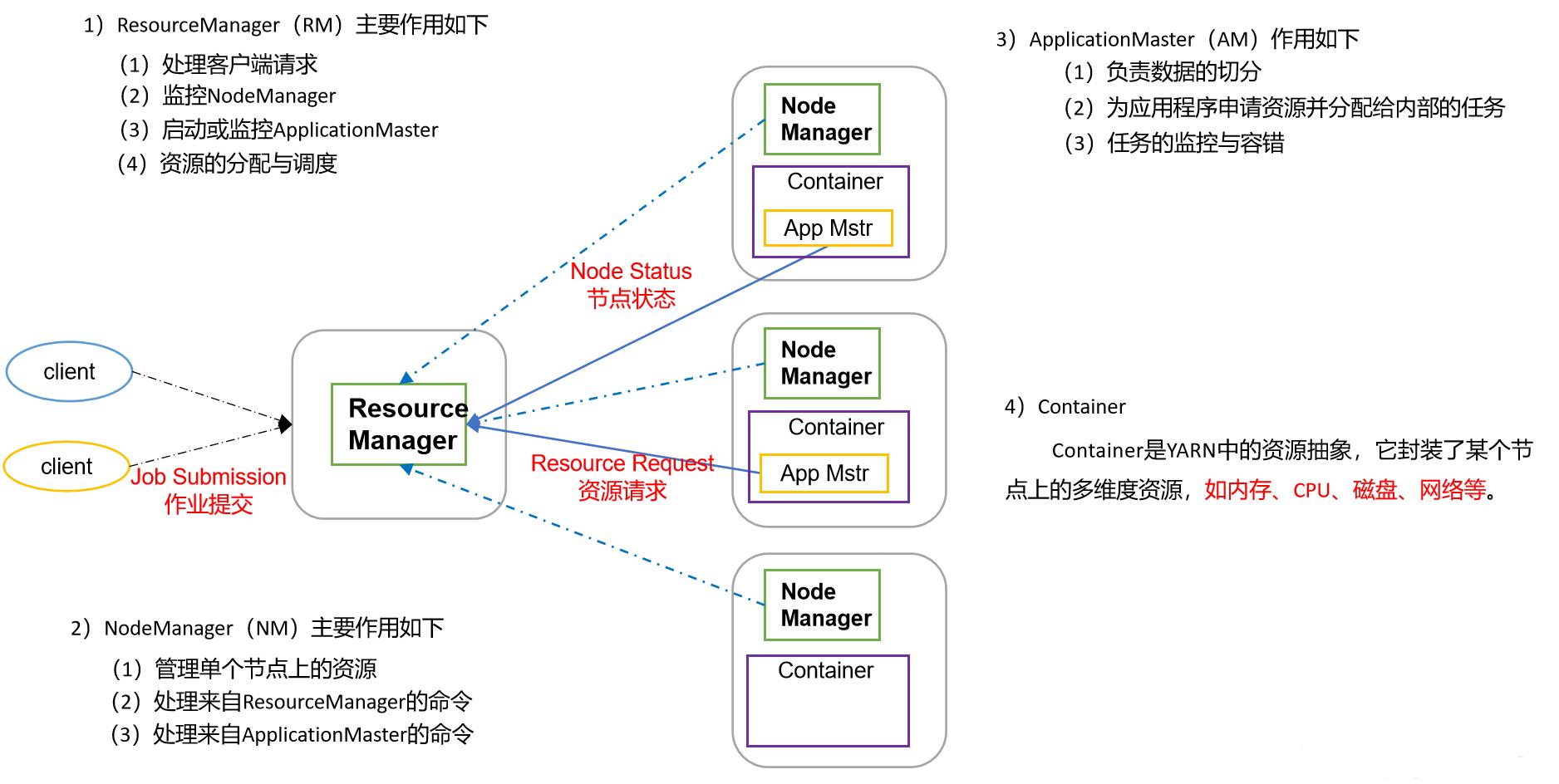
- YARN分类三个组件
- ResourceManager:它是集群的仲裁者,它有两个部分组成
- Scheduler:它是一个可拔插的调度
- ApplicationManager:它用于管理集群中的用户作业
- NodeManager
- 它用于管理每个节点上的用户作业
- ApplicationMaster
- 它是用户作业生命周期的管理者,主要功能是申请计算资源
- ResourceManager:它是集群的仲裁者,它有两个部分组成
大数据的技术生态体系
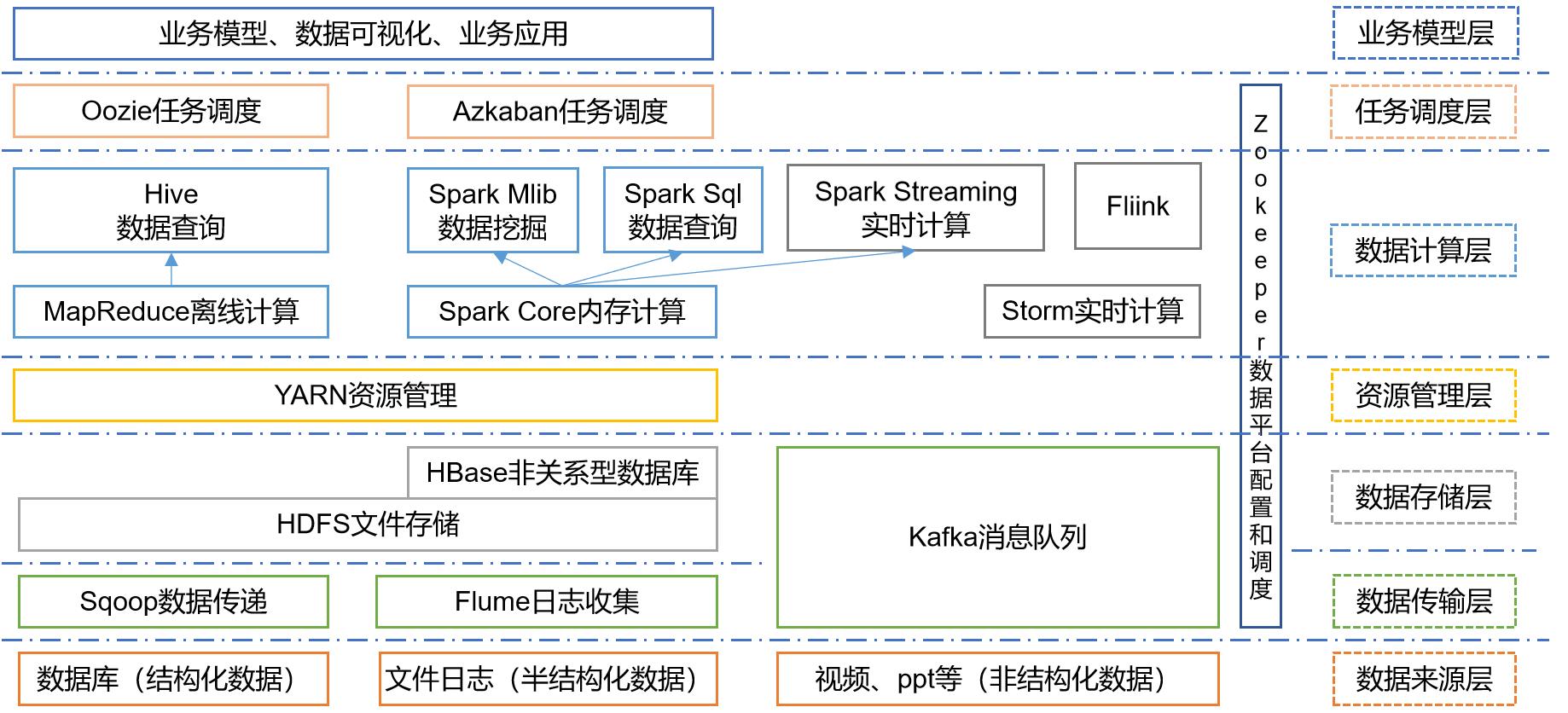
我简单介绍一下这个体系框架图:
- Sqoop:Sqoop是一款开源的工具,主要用于在Hadoop、Hive与传统的数据库(MySql)间进行数据的传递,可以将一个关系型数据库(例如 :MySQL,Oracle 等)中的数据导进到Hadoop的HDFS中,也可以将HDFS的数据导进到关系型数据库中。
- Flume:Flume是一个高可用的,高可靠的,分布式的海量日志采集、聚合和传输的系统,Flume支持在日志系统中定制各类数据发送方,用于收集数据;
- Kafka:Kafka是一种高吞吐量的分布式发布订阅消息系统;
- Storm:Storm用于“连续计算”,对数据流做连续查询,在计算时就将结果以流的形式输出给用户。
- Spark:Spark是当前最流行的开源大数据内存计算框架。可以基于Hadoop上存储的大数据进行计算。
- Flink:Flink是当前最流行的开源大数据内存计算框架。用于实时计算的场景较多。
- Oozie:Oozie是一个管理Hdoop作业(job)的工作流程调度管理系统。
- Hbase:HBase是一个分布式的、面向列的开源数据库。HBase不同于一般的关系数据库,它是一个适合于非结构化数据存储的数据库。
- Hive:Hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供简单的SQL查询功能,可以将SQL语句转换为MapReduce任务进行运行。 其优点是学习成本低,可以通过类SQL语句快速实现简单的MapReduce统计,不必开发专门的MapReduce应用,十分适合数据仓库的统计分析。
- ZooKeeper:它是一个针对大型分布式系统的可靠协调系统,提供的功能包括:配置维护、名字服务、分布式同步、组服务等
总结
- 本章节是大数据的开篇,主要介绍了大数据的概念以及我们的第一个框架Hadoop的概念以及组成,然后我又介绍了大数据的技术生态体系,看不懂没关系,我们刚刚开始,就如同Java一样,开篇先为大家列一个大纲,有个印象,后面我会一 一介绍的。下一章是Hadoop框架的搭建,虽然教程有很多,但我还是想记录一下,毕竟我做的是一个系列
- 好了,今天内容就是这些,欢迎后台留言哈
以上是关于打怪升级之小白的大数据之旅(四十一)<大数据与Hadoop概述>的主要内容,如果未能解决你的问题,请参考以下文章
打怪升级之小白的大数据之旅(四十五)<认识HDFS与常用操作>
打怪升级之小白的大数据之旅(四十六)<HDFS各模块的原理>
打怪升级之小白的大数据之旅(四十二)<Hadoop运行环境搭建>