教程 | 如何从TensorFlow转入PyTorch
Posted 深度学习世界
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了教程 | 如何从TensorFlow转入PyTorch相关的知识,希望对你有一定的参考价值。
选自Medium
机器之心编译
参与:李泽南、黄小天
当我第一次尝试学习 PyTorch 时,没几天就放弃了。和 TensorFlow 相比,我很难弄清 PyTorch 的核心要领。但是随后不久,PyTorch 发布了一个新版本,我决定重新来过。在第二次的学习中,我开始了解这个框架的易用性。在本文中,我会简要解释 PyTorch 的核心概念,为你转入这个框架提供一些必要的动力。其中包含了一些基础概念,以及先进的功能如学习速率调整、自定义层等等。
PyTorch 的易用性如何?Andrej Karpathy 是这样评价的
资源
首先要知道的是:PyTorch 的主目录和教程是分开的。而且因为开发和版本更新的速度过快,有时候两者之间并不匹配。所以你需要不时查看源代码:http://pytorch.org/tutorials/。
当然,目前网络上已有了一些 PyTorch 论坛,你可以在其中询问相关的问题,并很快得到回复:https://discuss.pytorch.org/。
把 PyTorch 当做 NumPy 用
让我们先看看 PyTorch 本身,其主要构件是张量——这和 NumPy 看起来差不多。这种性质使得 PyTorch 可支持大量相同的 API,所以有时候你可以把它用作是 NumPy 的替代品。PyTorch 的开发者们这么做的原因是希望这种框架可以完全获得 GPU 加速带来的便利,以便你可以快速进行数据预处理,或其他任何机器学习任务。将张量从 NumPy 转换至 PyTorch 非常容易,反之亦然。让我们看看如下代码:
import torch
import numpy as np
numpy_tensor = np.random.randn(10, 20)
# convert numpy array to pytorch array
pytorch_tensor = torch.Tensor(numpy_tensor)
# or another way
pytorch_tensor = torch.from_numpy(numpy_tensor)
# convert torch tensor to numpy representation
pytorch_tensor.numpy()
# if we want to use tensor on GPU provide another type
dtype = torch.cuda.FloatTensor
gpu_tensor = torch.randn(10, 20).type(dtype)
# or just call `cuda()` method
gpu_tensor = pytorch_tensor.cuda()
# call back to the CPU
cpu_tensor = gpu_tensor.cpu()
# define pytorch tensors
x = torch.randn(10, 20)
y = torch.ones(20, 5)
# `@` mean matrix multiplication from python3.5, PEP-0465
res = x @ y
# get the shape
res.shape # torch.Size([10, 5])
从张量到变量
张量是 PyTorch 的一个完美组件,但是要想构建神经网络这还远远不够。反向传播怎么办?当然,我们可以手动实现它,但是真的需要这样做吗?幸好还有自动微分。为了支持这个功能,PyTorch 提供了变量,它是张量之上的封装。如此,我们可以构建自己的计算图,并自动计算梯度。每个变量实例都有两个属性:包含初始张量本身的.data,以及包含相应张量梯度的.grad
import torch
from torch.autograd import Variable
# define an inputs
x_tensor = torch.randn(10, 20)
y_tensor = torch.randn(10, 5)
x = Variable(x_tensor, requires_grad=False)
y = Variable(y_tensor, requires_grad=False)
# define some weights
w = Variable(torch.randn(20, 5), requires_grad=True)
# get variable tensor
print(type(w.data)) # torch.FloatTensor
# get variable gradient
print(w.grad) # None
loss = torch.mean((y - x @ w) ** 2)
# calculate the gradients
loss.backward()
print(w.grad) # some gradients
# manually apply gradients
w.data -= 0.01 * w.grad.data
# manually zero gradients after update
w.grad.data.zero_()
你也许注意到我们手动计算了自己的梯度,这样看起来很麻烦,我们能使用优化器吗?当然。
import torch
from torch.autograd import Variable
import torch.nn.functional as F
x = Variable(torch.randn(10, 20), requires_grad=False)
y = Variable(torch.randn(10, 3), requires_grad=False)
# define some weights
w1 = Variable(torch.randn(20, 5), requires_grad=True)
w2 = Variable(torch.randn(5, 3), requires_grad=True)
learning_rate = 0.1
loss_fn = torch.nn.MSELoss()
optimizer = torch.optim.SGD([w1, w2], lr=learning_rate)
for step in range(5):
pred = F.sigmoid(x @ w1)
pred = F.sigmoid(pred @ w2)
loss = loss_fn(pred, y)
# manually zero all previous gradients
optimizer.zero_grad()
# calculate new gradients
loss.backward()
# apply new gradients
optimizer.step()
并不是所有的变量都可以自动更新。但是你应该可以从最后一段代码中看到重点:我们仍然需要在计算新梯度之前将它手动归零。这是 PyTorch 的核心理念之一。有时我们会不太明白为什么要这么做,但另一方面,这样可以让我们充分控制自己的梯度。
静态图 vs 动态图
PyTorch 和 TensorFlow 的另一个主要区别在于其不同的计算图表现形式。TensorFlow 使用静态图,这意味着我们是先定义,然后不断使用它。在 PyTorch 中,每次正向传播都会定义一个新计算图。在开始阶段,两者之间或许差别不是很大,但动态图会在你希望调试代码,或定义一些条件语句时显现出自己的优势。就像你可以使用自己最喜欢的 debugger 一样!
你可以比较一下 while 循环语句的下两种定义——第一个是 TensorFlow 中,第二个是 PyTorch 中:
import tensorflow as tf
first_counter = tf.constant(0)
second_counter = tf.constant(10)
some_value = tf.Variable(15)
# condition should handle all args:
def cond(first_counter, second_counter, *args):
return first_counter < second_counter
def body(first_counter, second_counter, some_value):
first_counter = tf.add(first_counter, 2)
second_counter = tf.add(second_counter, 1)
return first_counter, second_counter, some_value
c1, c2, val = tf.while_loop(
cond, body, [first_counter, second_counter, some_value])
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
counter_1_res, counter_2_res = sess.run([c1, c2])
import torch
first_counter = torch.Tensor([0])
second_counter = torch.Tensor([10])
some_value = torch.Tensor(15)
while (first_counter < second_counter)[0]:
first_counter += 2
second_counter += 1
看起来第二种方法比第一个简单多了,你觉得呢?
模型定义
现在我们看到,想在 PyTorch 中创建 if/else/while 复杂语句非常容易。不过让我们先回到常见模型中,PyTorch 提供了非常类似于 Keras 的、即开即用的层构造函数:
神经网络包(nn)定义了一系列的模块,它可以粗略地等价于神经网络的层。模块接收输入变量并计算输出变量,但也可以保存内部状态,例如包含可学习参数的变量。nn 包还定义了一组在训练神经网络时常用的损失函数。
from collections import OrderedDict
import torch.nn as nn
# Example of using Sequential
model = nn.Sequential(
nn.Conv2d(1, 20, 5),
nn.ReLU(),
nn.Conv2d(20, 64, 5),
nn.ReLU()
)
# Example of using Sequential with OrderedDict
model = nn.Sequential(OrderedDict([
('conv1', nn.Conv2d(1, 20, 5)),
('relu1', nn.ReLU()),
('conv2', nn.Conv2d(20, 64, 5)),
('relu2', nn.ReLU())
]))
output = model(some_input)
如果你想要构建复杂的模型,我们可以将 nn.Module 类子类化。当然,这两种方式也可以互相结合。
from torch import nn
class Model(nn.Module):
def __init__(self):
super().__init__()
self.feature_extractor = nn.Sequential(
nn.Conv2d(3, 12, kernel_size=3, padding=1, stride=1),
nn.Conv2d(12, 24, kernel_size=3, padding=1, stride=1),
)
self.second_extractor = nn.Conv2d(
24, 36, kernel_size=3, padding=1, stride=1)
def forward(self, x):
x = self.feature_extractor(x)
x = self.second_extractor(x)
# note that we may call same layer twice or mode
x = self.second_extractor(x)
return x
在__init__方法中,我们需要定义之后需要使用的所有层。在正向方法中,我们需要提出如何使用已经定义的层的步骤。而在反向传播上,和往常一样,计算是自动进行的。
自定义层
如果我们想要定义一些非标准反向传播模型要怎么办?这里有一个例子——XNOR 网络:
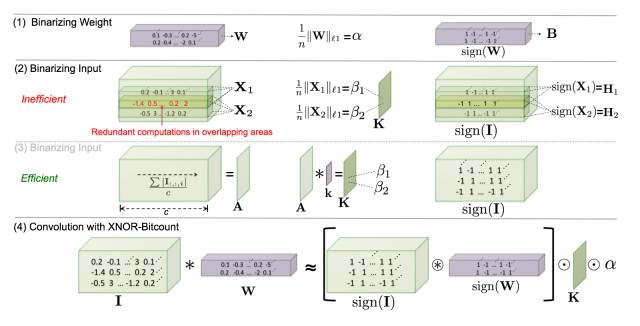
在这里我们不会深入细节,如果你对它感兴趣,可以参考一下原始论文:https://arxiv.org/abs/1603.05279
与我们问题相关的是反向传播需要权重必须介于-1 到 1 之间。在 PyTorch 中,这可以很容易实现:
import torch
class MyFunction(torch.autograd.Function):
@staticmethod
def forward(ctx, input):
ctx.save_for_backward(input)
output = torch.sign(input)
return output
@staticmethod
def backward(ctx, grad_output):
# saved tensors - tuple of tensors, so we need get first
input, = ctx.saved_variables
grad_output[input.ge(1)] = 0
grad_output[input.le(-1)] = 0
return grad_output
# usage
x = torch.randn(10, 20)
y = MyFunction.apply(x)
# or
my_func = MyFunction.apply
y = my_func(x)
# and if we want to use inside nn.Module
class MyFunctionModule(torch.nn.Module):
def forward(self, x):
return MyFunction.apply(x)
正如你所见,我们应该只定义两种方法:一个为正向传播,一个为反向传播。如果我们需要从正向通道访问一些变量,我们可以将它们存储在 ctx 变量中。注意:在此前的 API 正向/反向传播不是静态的,我们存储变量需要以 self.save_for_backward(input) 的形式,并以 input, _ = self.saved_tensors 的方式接入。
在 CUDA 上训练模型
我们曾经讨论过传递一个张量到 CUDA 上。但如果希望传递整个模型,我们可以通过调用.cuda() 来完成,并将每个输入变量传递到.cuda() 中。在所有计算后,我们需要用返回.cpu() 的方法来获得结果。
同时,PyTorch 也支持在源代码中直接分配设备:
import torch
### tensor example
x_cpu = torch.randn(10, 20)
w_cpu = torch.randn(20, 10)
# direct transfer to the GPU
x_gpu = x_cpu.cuda()
w_gpu = w_cpu.cuda()
result_gpu = x_gpu @ w_gpu
# get back from GPU to CPU
result_cpu = result_gpu.cpu()
### model example
model = model.cuda()
# train step
inputs = Variable(inputs.cuda())
outputs = model(inputs)
# get back from GPU to CPU
outputs = outputs.cpu()
因为有些时候我们想在 CPU 和 GPU 中运行相同的模型,而无需改动代码,我们会需要一种封装:
class Trainer:
def __init__(self, model, use_cuda=False, gpu_idx=0):
self.use_cuda = use_cuda
self.gpu_idx = gpu_idx
self.model = self.to_gpu(model)
def to_gpu(self, tensor):
if self.use_cuda:
return tensor.cuda(self.gpu_idx)
else:
return tensor
def from_gpu(self, tensor):
if self.use_cuda:
return tensor.cpu()
else:
return tensor
def train(self, inputs):
inputs = self.to_gpu(inputs)
outputs = self.model(inputs)
outputs = self.from_gpu(outputs)
权重初始化
在 TesnorFlow 中权重初始化主要是在张量声明中进行的。PyTorch 则提供了另一种方法:首先声明张量,随后在下一步里改变张量的权重。权重可以用调用 torch.nn.init 包中的多种方法初始化为直接访问张量的属性。这个决定或许并不直接了当,但当你希望初始化具有某些相同初始化类型的层时,它就会变得有用。
import torch
from torch.autograd import Variable
# new way with `init` module
w = torch.Tensor(3, 5)
torch.nn.init.normal(w)
# work for Variables also
w2 = Variable(w)
torch.nn.init.normal(w2)
# old styled direct access to tensors data attribute
w2.data.normal_()
# example for some module
def weights_init(m):
classname = m.__class__.__name__
if classname.find('Conv') != -1:
m.weight.data.normal_(0.0, 0.02)
elif classname.find('BatchNorm') != -1:
m.weight.data.normal_(1.0, 0.02)
m.bias.data.fill_(0)
# for loop approach with direct access
class MyModel(nn.Module):
def __init__(self):
for m in self.modules():
if isinstance(m, nn.Conv2d):
n = m.kernel_size[0] * m.kernel_size[1] * m.out_channels
m.weight.data.normal_(0, math.sqrt(2. / n))
elif isinstance(m, nn.BatchNorm2d):
m.weight.data.fill_(1)
m.bias.data.zero_()
elif isinstance(m, nn.Linear):
m.bias.data.zero_()
反向排除子图
有时,当你希望保留模型中的某些层或者为生产环境做准备的时候,禁用某些层的自动梯度机制非常有用。在这种思路下,PyTorch 设计了两个 flag:requires_grad 和 volatile。第一个可以禁用当前层的梯度,但子节点仍然可以计算。第二个可以禁用自动梯度,同时效果沿用至所有子节点。
import torch
from torch.autograd import Variable
# requires grad
# If there’s a single input to an operation that requires gradient,
# its output will also require gradient.
x = Variable(torch.randn(5, 5))
y = Variable(torch.randn(5, 5))
z = Variable(torch.randn(5, 5), requires_grad=True)
a = x + y
a.requires_grad # False
b = a + z
b.requires_grad # True
# Volatile differs from requires_grad in how the flag propagates.
# If there’s even a single volatile input to an operation,
# its output is also going to be volatile.
x = Variable(torch.randn(5, 5), requires_grad=True)
y = Variable(torch.randn(5, 5), volatile=True)
a = x + y
a.requires_grad # False
训练过程
当然,PyTorch 还有一些其他卖点。例如你可以设定学习速率,让它以特定规则进行变化。或者你可以通过简单的训练标记允许/禁止批规范层和 dropout。如果你想要做的话,让 CPU 和 GPU 的随机算子不同也是可以的。
# scheduler example
from torch.optim import lr_scheduler
optimizer = torch.optim.SGD(model.parameters(), lr=0.01)
scheduler = lr_scheduler.StepLR(optimizer, step_size=30, gamma=0.1)
for epoch in range(100):
scheduler.step()
train()
validate()
# Train flag can be updated with boolean
# to disable dropout and batch norm learning
model.train(True)
# execute train step
model.train(False)
# run inference step
# CPU seed
torch.manual_seed(42)
# GPU seed
torch.cuda.manual_seed_all(42)
同时,你也可以添加模型信息,或存储/加载一小段代码。如果你的模型是由 OrderedDict 或基于类的模型字符串,它的表示会包含层名。
from collections import OrderedDict
import torch.nn as nn
model = nn.Sequential(OrderedDict([
('conv1', nn.Conv2d(1, 20, 5)),
('relu1', nn.ReLU()),
('conv2', nn.Conv2d(20, 64, 5)),
('relu2', nn.ReLU())
]))
print(model)
# Sequential (
# (conv1): Conv2d(1, 20, kernel_size=(5, 5), stride=(1, 1))
# (relu1): ReLU ()
# (conv2): Conv2d(20, 64, kernel_size=(5, 5), stride=(1, 1))
# (relu2): ReLU ()
# )
# save/load only the model parameters(prefered solution)
torch.save(model.state_dict(), save_path)
model.load_state_dict(torch.load(save_path))
# save whole model
torch.save(model, save_path)
model = torch.load(save_path)
根据 PyTorch 文档,用 state_dict() 的方式存储文档更好。
记录
训练过程的记录是一个非常重要的部分。不幸的是,PyTorch 目前还没有像 Tensorboard 这样的东西。所以你只能使用普通文本记录 Python 了,你也可以试试一些第三方库:
logger:https://github.com/oval-group/logger
Crayon:https://github.com/torrvision/crayon
tensorboard_logger:https://github.com/TeamHG-Memex/tensorboard_logger
tensorboard-pytorch:https://github.com/lanpa/tensorboard-pytorch
Visdom:https://github.com/facebookresearch/visdom
掌控数据
你可能会记得 TensorFlow 中的数据加载器,甚至想要实现它的一些功能。对于我来说,我花了四个小时来掌握其中所有管道的执行原理。
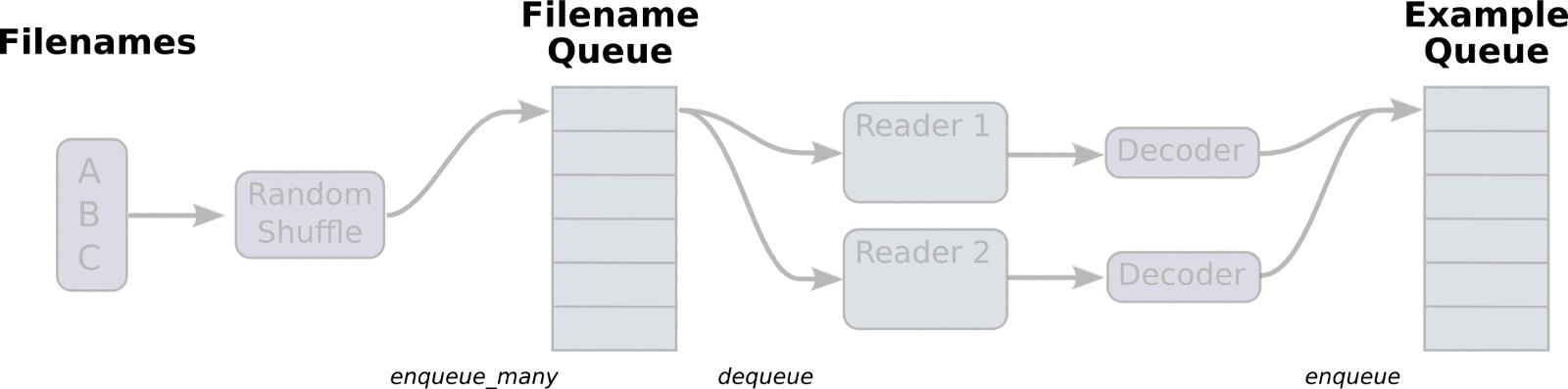
首先,我想在这里添加一些代码,但我认为上图足以解释它的基础理念了。
PyTorch 开发者不希望重新发明轮子,他们只是想要借鉴多重处理。为了构建自己的数据加载器,你可以从 torch.utils.data.Dataset 继承类,并更改一些方法:
import torch
import torchvision as tv
class ImagesDataset(torch.utils.data.Dataset):
def __init__(self, df, transform=None,
loader=tv.datasets.folder.default_loader):
self.df = df
self.transform = transform
self.loader = loader
def __getitem__(self, index):
row = self.df.iloc[index]
target = row['class_']
path = row['path']
img = self.loader(path)
if self.transform is not None:
img = self.transform(img)
return img, target
def __len__(self):
n, _ = self.df.shape
return n
# what transformations should be done with our images
data_transforms = tv.transforms.Compose([
tv.transforms.RandomCrop((64, 64), padding=4),
tv.transforms.RandomHorizontalFlip(),
tv.transforms.ToTensor(),
])
train_df = pd.read_csv('path/to/some.csv')
# initialize our dataset at first
train_dataset = ImagesDataset(
df=train_df,
transform=data_transforms
)
# initialize data loader with required number of workers and other params
train_loader = torch.utils.data.DataLoader(train_dataset,
batch_size=10,
shuffle=True,
num_workers=16)
# fetch the batch(call to `__getitem__` method)
for img, target in train_loader:
pass
有两件事你需要事先知道:
1. PyTorch 的图维度和 TensorFlow 的不同。前者的是 [Batch_size × channels × height × width] 的形式。但如果你没有通过预处理步骤 torchvision.transforms.ToTensor() 进行交互,则可以进行转换。在 transforms 包中还有很多有用小工具。
2. 你很可能会使用固定内存的 GPU,对此,你只需要对 cuda() 调用额外的标志 async = True,并从标记为 pin_memory = True 的 DataLoader 中获取固定批次。
最终架构
现在我们了解了模型、优化器和很多其他细节。是时候来个总结了:
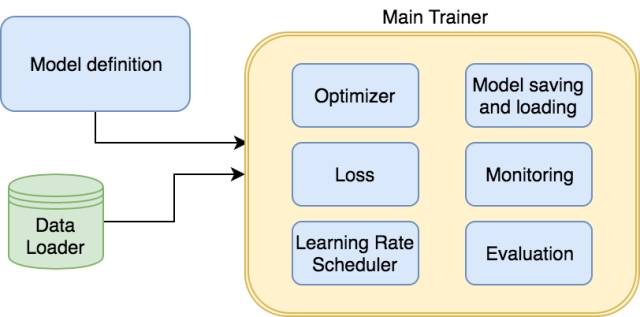
这里有一段用于解读的伪代码:
class ImagesDataset(torch.utils.data.Dataset):
pass
class Net(nn.Module):
pass
model = Net()
optimizer = torch.optim.SGD(model.parameters(), lr=0.01)
scheduler = lr_scheduler.StepLR(optimizer, step_size=30, gamma=0.1)
criterion = torch.nn.MSELoss()
dataset = ImagesDataset(path_to_images)
data_loader = torch.utils.data.DataLoader(dataset, batch_size=10)
train = True
for epoch in range(epochs):
if train:
lr_scheduler.step()
for inputs, labels in data_loader:
inputs = Variable(to_gpu(inputs))
labels = Variable(to_gpu(labels))
outputs = model(inputs)
loss = criterion(outputs, labels)
if train:
optimizer.zero_grad()
loss.backward()
optimizer.step()
if not train:
save_best_model(epoch_validation_accuracy)
结论
希望本文可以让你了解 PyTorch 的如下特点:
它可以用来代替 Numpy
它的原型设计非常快
调试和使用条件流非常简单
有很多方便且开箱即用的工具
PyTorch 是一个正在快速发展的框架,背靠一个富有活力的社区。现在是尝试 PyTorch 的好时机。 ![]()

点击下方“阅读原文”了解大数据实验平台 ↓↓↓
以上是关于教程 | 如何从TensorFlow转入PyTorch的主要内容,如果未能解决你的问题,请参考以下文章
如何从零使用 Keras + TensorFlow 开发一个复杂深度学习模型?