AI | 图神经网络-Pytorch Biggraph简介及官方文档解读
Posted 运筹OR帷幄
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了AI | 图神经网络-Pytorch Biggraph简介及官方文档解读相关的知识,希望对你有一定的参考价值。
编者按
GNN在社交网络、知识图、推荐系统各个领域得到了越来越广泛的应用。19年的时候,听facebook那边的童鞋分享,第一次了解到BigGraph在工业界的应用。BigGraph是GNN在工业应用中一个比较优秀的实践,从而萌生了我在实际工作场景中实际应用的想法。在实际的工作场景中和对BigGraph的二次开发过程中,对BigGraph调度分布式模式的理解成为应用场景中比较关键的一环。本文是基于BigGraph的官方文档翻译来的,加上了一些我们实践过程中对系统的理解。能力有限,如有问题,欢迎指正。

图嵌入是一种从图中生成无监督节点特征(node features)的方法,生成的特征可以应用在各类机器学习任务上。现代的图网络,尤其是在工业应用中,通常会包含数十亿的节点(node)和数万亿的边(edge)。这已经超出了已知嵌入系统的处理能力。我们介绍了一种嵌入系统,PyTorch-BigGraph(PBG),系统对传统的多关系嵌入系统做了几处修改让系统能扩展到能处理数十亿节点和数万亿条边的图形。PBG使用了图形分区来支持任意大小的嵌入在单机或者分布式环境中训练。我们展示了在功能的基准上与现有嵌入系统的性能比较,同时PBG允许在多台机器上允许缩放到任意大小并且支持并行。我们在使用几个大型社交图网络作为完整Freebase数据集来训练和评估嵌入系统,数据集包含超过1亿个节点和20亿条边。
一
简介
图结构数据是各种机器学习任务的一种常见输入,直接处理图结构数据是比较困难的,常用的技术是通过图嵌入方法为图中的每个节点创建向量化表示使得这些向量间的距离能预测图形中是否存在边。图嵌入已经被证明是下游任务中有意义的特征,如:电子商务中的推荐系统,社交媒体中的链接预测,药物相互作用、表征蛋白网络。
图结构数据在现代网络公司非常常见,这给标准的嵌入方法提出了额外的调整:规模。例如:Facebook图中包含20亿个用户节点和超过1万亿条边,这些边代表朋友关系、喜好、帖子和其他链接。阿里巴巴的用户和产品图也包含10亿以上的用户和20亿以上的商品。在Pinterest,用户到项目的图包含20亿的实体和超过170亿边。对这样大小的图做嵌入主要有两个挑战,一是这个嵌入系统必须足够快,需要在一个合理的时间内完成10^11 - 10^12条边的嵌入;二是拥有20亿个节点,每个节点32个嵌入参数(浮点表示),大概需要800GB大小的内存来存储这些参数,因此许多标准方法超出了典型商用服务器的内存容量。
我们介绍了Pytorch(译注:facebook开源的深度学习框架)Biggraph,一种基于标准模型做了若干改进的嵌入系统。PBG带来的改进是讲标准方案扩展到具有数十亿个节点和数万亿个边图。
PBG的重要组成部分:
1、将邻接矩阵分块,分解为n个桶,每次从一个桶的边缘开始进行训练,然后PBG要么交换每个分区到磁盘的嵌入来减少内存的使用,要么跨机器进行分布式训练。
2、分布式执行模型:对大参数矩阵进行快分解,以及用于特征化节点的全局参数和特征嵌入的参数服务架构
3、高效的节点负采样:在数据中对负向节点进行均匀采样 并在批处理中重用负节点以减少内存用量
4、支持多实体、多关系图,支持边缘权重、关系运算符选择等关系配置选项
我们在Freebase、LiveJournal和YouTube图数据集上评估了PBG,表明了PBG能和当前已有的陷入系统性能能匹配。
我们也给出了更大图数据上的结果,我们构造了一个完整的Freebase图(1.21亿个实体,24亿条边)的嵌入,并将其公开发布。Freebase图的划分减少了88%的内存消耗,嵌入向量的质量只有略微的下降,在8台机器上分布式执行,时间减少了4倍。另外我们在一个Twitter的大图数据上进行了试验,通过近似线性缩放得到了相似的结果。
PBG 作为一个开源项目发布在:
https://github.com/facebookresearch/PyTorch-BigGraph.PBG是通过Pytorch实现的,没有其他外部依赖。
二
BigGraph 中文文档
本系列为翻译的pytouch的官方手册,希望能帮助大家快速入门GNN及其使用,全文十五篇,文中如果有勘误请随时联系。
1.数据模型
源链接:
https://torchbiggraph.readthedocs.io/en/latest/data_model.html
PBG operates 是有向多关系多图,图上的顶点称为实体,每个边将源连接到目标实体。源和目标分别称为左侧和右侧(简称lhs和rhs)。同一对实体之间允许有多个边,也允许使用环,即左侧和右侧相同的边。
每个实体都属于特定的实体类型(即每个实体只有一种类型)。所以类型将所有实体划分为不相交的组。同样,每个边也只属于一个关系类型,并且关系类型的边的左侧实体应该有相同实体类型,以及右侧应该也是相同实体类型(左右侧实体类型可以具有不同的实体类型)。此属性表示每个关系类型都有左侧实体类型和右侧实体类型。
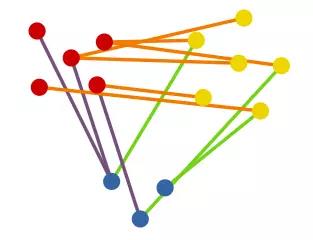
在这个图中,有14个实体:5个红色实体、6个黄色实体、3个蓝色实体;同时,图中有12条边,6条橘色的边,3条紫色的边,3条绿色的边
为了让PBG能够让大规模的图形能运行,我们将图形分解成小块,在这些小块上可以进行分布式的训练。首先是通过将每种类型的实体进一步拆分为若干个子集(称为分区)。然后,对于每种关系类型,它的边被划分为桶:对于每对分区(一个来自左侧,另一个来自右侧实体类型)将创建一个桶,其中包含特定类型的边及对应左、右侧实体。
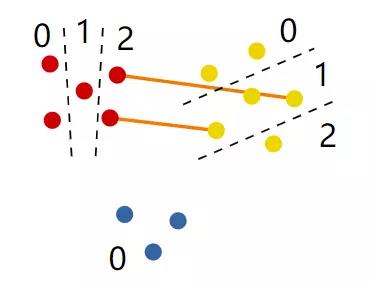
本图展示了一种实体划分的方式,将红色实体分为3类、黄色分为3类,蓝色仅为1类。边显示的是黄色实体分桶1和红色实体分桶2之间的实体边。
注:出于技术原因,当前出现在关系类型左侧的所有实体类型必须划分为相同数量的分区(未分区的实体除外)。对于出现在右侧的所有实体类型,必须保持相同的状态。在numpy中,这意味着所有实体的分区数必须可以扩展到相同的值。
一个实体通过自身的类型、分桶、分组中的索引来定义(索引必须是连续的,这意味着如果一个类型的分区中有n个实体,则其索引位于半开放区间[0,n])。一条边铜鼓变得类型,分桶(即其左侧和右侧实体类型的分区)以及其左侧和右侧实体在各自分区中的索引来标识。边缘不必指定其左侧和右侧实体类型,因为它们隐式地存在于边缘的关系类型中。
形式上,每个桶都可以通过一对整数(i,j)来标识,其中i和j分别是左侧和右侧分区。在该桶中,每个边都可以由整数(x,r,y)的三联体标识,x和y分别表示左侧和右侧实体,r表示关系类型。通过首先在配置中查找关系类型R来“解释”此边缘,并发现其左侧只能有类型e1的实体,右侧只能有类型e2的实体。然后可以确定左侧实体,由(e1,i,x)(其类型、分区及其在分区内的索引)给出,同样,也可以确定右侧实体(e2,j,y)。
2.从实体嵌入到边分值
源链接:
https://torchbiggraph.readthedocs.io/en/latest/scoring.html
Embeding 训练的目标是将每个实体嵌入到R空间中,并且让两个实体的嵌入能很好地预测他们之间是否存在某种特定的关系。
更准确地说,训练的目标是为每个实体学习嵌入并为每个关系类型学习一个函数。函数接受两个实体嵌入,为它们分配一个分数。函数主要是为了让相关实体比不相关实体能获得更高的分数。
训练集中提供的所有边都被视为正实例。为了进行训练,还需要一组负边。这些负边不是由用户提供的,而是由系统在培训期间生成的(参见见负抽样),通常通过固定左侧实体和关系类型并抽样一个新的右侧实体,反之亦然。这种抽样方案在大型稀疏图是合理的,因为这样生成的边在图中是真正边的概率很低。
通常来说,实体嵌入可以在R空间中取任何值。但是,在某些情况下(例如,当限制它们在某个球内时,或者当使用余弦距离比较它们时),它们的“角度”将比它们的范数更重要。
每个关系评分函数必须以特定的形式表示(文献中最常见的功能可以转换为这种表示)。在当前的实现中,只允许对其中一个边的嵌入进行转换,然后使用通用的对称比较器函数将其与另一个边的未转换嵌入进行比较,这对于所有关系都是相同的。形式上,对于左侧实体x和右侧实体y,以及对于关系类型r,得分为:fr(θx,θy)=c(θx,gr(θy)).其中θx和θy分别是x和y的嵌入,fr是r的得分函数,gr是r的操作器,c是比较器。
在“正常”情况下(所谓的“标准”关系模式),运算符仅应用于右侧实体。使用动态关系时不是这样。将运算符应用于两侧通常是多余的。另外,与另一侧相比,首选一侧可以打破对称性并捕捉边缘的方向。

Embeddings 嵌入
嵌入表示存在在D维真实空间中,其中D由维度配置参数确定。通常,每个实体都有自己的嵌入,这完全独立于任何其他实体的嵌入。当使用特征化实体的方法不同,是实体的嵌入将是其特征嵌入的平均值。
如果设置了max_norm配置参数,则每次参数更新后,嵌入将以半径max_norm投影到单位球上。如果要添加新的嵌入类型,需要实现torchbigraph.model.abstractEmbedding类的子类。
Global embeddings 全局嵌入
当global_emb配置参数被激活,每个实体嵌入通过一个特定的实体类型向量(与嵌入同时学习)来转化。
Operators 操作器
none,无操作,使嵌入保持不变;
translation, 平移,增加了嵌入相同维的向量;
diagonal, 对角线,将每个尺寸乘以不同的系数(相当于乘以对角线矩阵);
linear, 线性,应用线性映射,即乘以一个全平方矩阵。
affine, 仿射,应用仿射变换,即线性后接translation。
complex_diagonal, 复数_对角线,它将D-维实向量解释为D/2维复向量(D必须是偶数;向量的前半部分是实向量,后半部分是虚向量),然后将每个条目乘以不同的复杂参数,就像diagonal一样。
所有操作器的参数是在训练中学得的。如果要自定义操作器,我们需要实现torchbiggraph.model.AbstractOperator的子类(在动态关系情况下实现torchbiggraph.model.AbstractDynamicOperator子类,docstrings解释了必须实现什么)并且在torchbiggraph.model.register_operator_as()装饰器中注册(或者torchbiggraph.model.register_dynamic_operator_as())指定一个新名称,然后在配置中使用该名称来选择比较器。上述所有操作都可以在配置文件内部完成。
Comparators 比较器
可用的比较器有:
dot,点积,计算两个嵌入向量的标量或内积;
cos,cos距离,是两个向量之间夹角的余弦,或等于点积除以向量范数的乘积。
l2,负的l2距离,也就是欧几里得距离(负是因为较小的距离会得到较高的分数)。
squared_l2,负平方L2距离。
自定义比较器需要实现torchbiggraph.model.AbstractComparator 子类并且在torchbiggraph.model.register_comparator_as()装饰器中注册,指定一个新名称,然后在配置中使用该名称来选择比较器。上述所有操作都可以在配置文件内部完成。
Bias 偏置
如果使用了bias 配置,那么嵌入的第一个坐标将作为比较器计算中的偏差。这意味着比较器将仅根据向量的最后一个D-1条目进行计算,然后将两个向量的第一个条目都添加到结果中。
Coherent sets of configuration parameters 相关配置集
本章中描述的参数在配置文件中集中显示(为了更接近实现,并允许更灵活的调优),但它们的某些组合比其他组合更优。
除了默认配置外,还发现以下的配置效果较优:init_scale = 0.1, comparator = dot, bias = true, loss_fn = logistic, lr = 0.1.
Interpreting the scores 分值解释
在训练过程中,不同的应用会基于不同的损失函数,这让得到的分值有不同的解释。常见的包括对和实体有关联关系的实体排序,确定两个给定实体之间存在某种关系的概率等。
3.I/O格式化
原链接:
https://torchbiggraph.readthedocs.io/en/latest/input_output.html
Entity and relation types 实体和关系类型
配置文件中需要包含实体字典,文件内容是实体类型(每个类型都由字符串标识)以及别的有关的信息。配置文件的relations key是关系类型的列表(每个类型都由其在该列表中的索引标识)以及别的数据如左右两侧的实体类型。
Entities 实体
需要提供的关于实体的唯一信息是每个实体类型的分区中有多少个实体。这是通过将名为entity_count_type_part.txt的文件放在entity_path config参数指定的目录中,用于由类型标识的每个实体类型和每个分区。这些文件必须包含一个整数(文本),即该分区中的实体数。必须将所有这些文件所在的目录指定为配置文件的entity_path路径。
我们可以通过在init_path配置项中设置特定的值来为embeddings初始化,配置项的值为包含文件内容格式类似于Checkpoint文件的路径,输出格式在Checkpoint中详细介绍。
如果没有提供初始值,每个维度都从中心正态分布中取样来自动生成,标准偏差可以使用init_scale配项键进行配置。出于性能原因,特定类型的所有实体的样本将不独立。
Edges边
对于每个bucket必须有一个文件来存储属于该bucket的所有边和所有关系类型。这代表文件只能由两个整数来标识,即其左侧和右侧实体的分区。它必须命名为edges_lhs_rhs.h5(其中lhs和rhs是上面的整数),文件必须是hdf5格式,包含三个长度相同的一维数据集,称为rel、lhs和rhs。每个元素中第i个位置的元素定义了第i个边缘:rel标识关系类型(从而标识左侧和右侧实体类型),lhs和rhs给出了各自分区中左侧和右侧实体的索引。
为了方便将来格式更新,每个文件需要在顶级组的format_version属性中包含格式版本,当前版本为1。
如果一个实体类型是未分区的(即所有实体都属于同一分区),那么这些实体的边必须均匀分布在所有存储桶中。
这些文件,对于所有的桶,必须存储在同一目录中,该目录通过edge_paths来配置。这个配置实际上可以包含一个路径列表,每个路径指向上面描述的格式的目录:如果这样配置图形将包含所有边的并集。
Checkpoint 检查点
训练的数据,也就是检查点被写入在checkpoint_path中配置的目录中。checkpoint 由连续的正整数(从1开始)标识,并且属于某个checkpoint 的所有文件在其名称和扩展名之间都有一个额外的组件.vversion(例如,对于版本42为.v42.h5)。
最新的完整checkpoint版本存储在同目录下名为checkpoint_version.txt文件中,其中包含一个整数,即当前版本。
每个checkpoint都包含一个配置的JSON转储文件,用于存储在config.json文件中的配置
保存新版本checkpoint后,将自动删除以前的版本。为了定期保留其中一些版本,请将checkpoint_preservation_interval 配置设置为所需的周期(以epoch数表示)。
Model parameters 模型参数
模型参数存储在名为model.h5的文件中,文件格式是一个hdf5文件,其中包含每个参数的一个数据集,所有数据集都位于model 组中。目前提供的参数有:
model/relations/idx/operator/side/param 存储了每个操作器的关系参数
model/entities/type/global_embedding 存储了每个预训实体类型的全局嵌入
这些数据集中的每一个还包含存储在模型状态字典,用state-dict-key属性配置。另外还可能有另一个数据集optimizer/state_dict,包含模型优化器状态字典的二进制文件(可以通过torch.save()获取)。
最后,文件的顶级组包含包含了一些附加元数据的属性。主要包括格式版本、配置的JSON转储和一些有关生checkpoint的迭代的信息。
Embeddings 嵌入
对于每个实体类型及其分区,都有一个文件embeddings_type_part.h5(其中type是类型的名称,part是分区的基于0的索引)。该文件是包含两个数据集的HDF5文件——嵌入,包含实体的嵌入:一个二维数据集,第一个维度是实体数,第二个维度是嵌入的维度。
与模型参数文件一样,优化器状态dict和其他元数据也包含在里面。
图嵌入是一种从图中生成无监督节点特征(node features)的方法,生成的特征可以应用在各类机器学习任务上。现代的图网络,尤其是在工业应用中,通常会包含数十亿的节点(node)和数万亿的边(edge)。这已经超出了已知嵌入系统的处理能力。我们介绍了一种嵌入系统,PyTorch-BigGraph(PBG),系统对传统的多关系嵌入系统做了几处修改让系统能扩展到能处理数十亿节点和数万亿条边的图形。
4.批预处理
原链接:
https://torchbiggraph.readthedocs.io/en/latest/batch_preparation.html
本节介绍了每一批次数据在损失的计算和优化前是如何准备和组织的。
训练通过循环嵌套来迭代处理边。扫描从外层到内层叫代(时期),代际间是相互独立并且过程基本一致,这样的目的是重复内部循环直到收敛。每代迭代会访问到所有的边,epochs的数目在num_epochs配置参数中指定。
译者注:
(1)batch:1个batch代表深度学习算法一次参数的更新,所需要损失函数并不是由一个数据获得的,而是由一组数据加权得到的,这一组数据的数量叫batchsize;
(2)iteration:1个iteration等于使用batchsize个样本训练一次;
(3)epoch:1个epoch等于使用训练集中的全部样本训练一次,通俗的讲epoch的值num_epoch就是整个数据集被轮几次。
当迭代一个边集合时,每个分桶首先会被分割为大小相等的块:每个块由连续间隔的边构成(和存储在文件中的顺序一致),块的数量可以通过设置num_edge_chunks来调整。训练从所有桶的第一个块开始,然后第二个,以此类推。
然后算法开始迭代桶,训练桶的顺序依赖于配置文件中bucket_order这个配置项。除了随机排列之外,有一些方法用于尝试将训连续的桶之间共享一个分区:这让分区能够被重用,从而允许可以允许参数存储在内存中而不是先注销然后被另一个桶加载到自己的空间中(在分布式模式下,不同的训练器进程同时在桶上运行,因此迭代的管理方式不同)。
当训练器被固定了一个确定的桶和一个指定的快,边会最终磁盘上加载起来。当在训练中评估的时候,这些边的一个子集被保留(这个子集对所有的代都是一样的)。被保留的这些边会被均匀打散然后分为相等的部分。为了让训练过程中可以训练过程可以在同一时间并行进行,打散后的分片会放到一个分布式的处理池中处理Processes。这些子流程相互间不同步他们的计算或内存,我们叫 “Hogwild” worker,这些节点worker的数据量通过workers参数来控制。
每个worker上训练边集合的方式取决于动态关系是否被用了。最简单的情况是边被分割到连续的batches(每个batch都和batch_size中配置指定的大小一样,除了最后一个可以略小一点),这样便可以对样本一批接一批顺序训练。
当动态关系没有被使用,也就是说损失的计算只能对一个边的集合中所有具有相同类型的边计算。因此,worker首先随机一个关系类型,选取的数量应该和样本池中同类型边的概率占比一致。然后采用手个batch_size大小的同类关系(如果剩下的样本不够),在训练池中删除掉这些样本并开始训练。
5.分布式模式
源链接:
https://torchbiggraph.readthedocs.io/en/latest/distributed_training.html
PBG可以跨多台机器训练,通过网络进行机器间通信,以减少大型图形上的训练时长。分布式训练可以同时利用更大的计算资源,同时将整个模型跨机器存储在内存中,避免了内存和硬盘间的数据交换。训练在每个机器上多个子流程间进一步的并行化。
Setup 启动
启动分布式训练,在每台机器上启动torchbiggraph_train --rank rank config.py ,其中对每台机器,rank需要替换成从0到N-1的不同的整数。每个机器上必须已经安装了PBG并且都有一份相同的配置文件。
在某些非常规的情况下,需求是希望将嵌入存放到不同的机器上而不是训练嵌入。在这种情况下,可以配置num_partition_servers及存放的机器数,并且在一些实例上启动torchbiggraph_partitionserver。请参阅下面的详细信息。
Tip:
推荐的默认设置是将num_machines设置为分区数量的一半(参见下面的原因),并让num_partition_servers保持未设置状态。
一旦启动所有这些命令,就不再需要手动干预。
Warning:
未分区的实体不应该用于做分布式训练。原因是尽管分区实体类型的嵌入一次只能在一台计算机上使用,并可以根据需要在计算机之间进行交换,但未分区实体类型的嵌入是通过一个优化不良的参数服务器异步通信的,该服务器是为共享关系而设计的,空间很小,所以不支持同步大量参数。例如,具有1000多个实体的未分区实体类型,在这种情况下,未划分的嵌入的质量可能非常差。
Communication protocols 通信协议
分布式训练包含机器间协同和通信的在不同目标下的不同方式,包含以下几种:
1)广播那个训练器正在操作哪个分桶,通过分配来避免冲突;
2)在需要时将实体分区的嵌入从一个训练器传递到下一个训练器(针对一次只能由一个训练器访问的数据类型)
3)通过收集和重新分发更新参数,共享所有训练器需要同时访问的参数。
上述的方案都被独立实现为“协议”,每个训练器通过启动子流程作为协议的一部分或者全部,在不同的协议中扮演客户端或者服务端的角色。下面将对这些协议进行说明,以深入了解系统。
Synchronizing bucket access 同步分桶访问
PBG通过在多机上训练不交叉的分桶来实现分布式训练(如:分桶间不会包含有相同的partition)。因此,每个分区一次最多由一台机器使用,每台机器最多使用两个分区(唯一的例外是“对角线上”的存储桶,它们具有相同的左侧和右侧分区)。这意味着可以同时训练的bucket数量大约是分区总数的一半。
这种方式让集群通过“lock server”商定哪个机器可以对哪个桶进行操作。服务器隐式的从排序为0训练器开始,其他所有机器作为他的客户端,请求一个新的分桶来开始训练操作(当他们需要新的分桶时),获得一个服务器指定的分桶(或者未获得,如果所有的分桶都已经被训练或者在“locked”状态,即该partitions被其他训练器使用中),开始训练,训练完成后返回并重复上述动作。lock server 优化I/O的策略:当训练器请求bucket时,尽可能的分配和上一个bucket相邻的bucket到的相同的训练器上,这样这些分区就可以保存在内存中,而不必卸载和重新加载。
Exchanging partition embeddings 分区交换嵌入
当一个训练器开始对一个分桶的数据操作的时候,它需要访问所有实体的嵌入向量embeddings,这些向量不然是分桶的左邻接节点,不然是右邻接节点。locking 机制通过lock server确保在给定时刻内只有一个训练器对partition进行操作。但是这无法处理未分区的实体类型,这需要再所有训练器中共享,参照下文。因此保证了每个训练器对自己持有的partition是独占的。
一旦一个训练器开始在新的bucket上工作,就需要获取其分区的嵌入,在完成后释放,并在其更新版本中提供给下一个需要它们的训练器。为了支持上述过程,有一个顾名思义叫“partition servers”的系统来存储嵌入向量,提供给需要这些嵌入的训练器并接收对这些向量的更新并存储。
这个服务是可选的,当吧num_partition_servers设置为0时被禁用。在这种情况下,训练器只需将嵌入内容写入检查点目录(该目录应位于共享磁盘上),然后其他训练器从那里取回,就可以相互“传送”。
启用此系统后,它可以在两种模式下工作。最简单的模式是我们把num_partition_servers设置为-1(默认):在这种情况下,所有训练器会生成一个本地进程作为partition服务。另外一种模式则num_partition_servers是一个正值,那么训练器将不会生成任何进程,但是我们需要通过在适当数量的机器上手动通过torchbiggraph_partitionserver命令来启动该系统。
共享参数更新
有些模型参数需要一直被全局的训练器访问(包含操作器operator的权重,每个实体类型的全局嵌入,未分区实体的嵌入向量)。有些参数不依赖于训练器处理的分桶,但所有训练器都需要常驻以使用到(和跟进需要反复加载和卸载的实体嵌入相反)。这些参数通过一组“parameter servers”来同步,每个训练器启动一个本地的参数服务器(一个独立的子进程)并且和其他参数服务器连接。训练器间共享每个参数并且存储在parameter server(如果太大的话可能是分片)。每个训练器也有一个循环(也在一个单独的子进程中)定期遍历每个共享参数,计算其当前本地值和上次与参数的服务器同步时的值之间的差值,并将该差值发送给服务器。服务器依次累加从所有训练器接收到的所有增量,更新参数值并将此新值发送回训练器。同时,为了防止参数服务器使其他通信不足,参数服务器限制100个更新/s或1Gb/s。
参考文献
[1]https://github.com/facebookresearch/PyTorch-BigGraph.PBG
[2] https://www.jianshu.com/u/a0aed87ff1be
相关文章推荐
近几年学习人工智能的热潮可说是居高不下,涌现了大量机器学习、深度学习相关的教学资源,这些学习资料的质量参差不齐,我们要有选择性的学习,不可盲从、急功近利,更重要的是对基础知识的学习,毕竟百尺高楼非平地而起的。
点击蓝字标题,即可阅读

号外!『运筹OR帷幄』入驻知识星球!
随着算法相关专业热度和难度岗位对专业人才要求的提高,考研、读博、留学申请、求职的难度也在相应飙升。
『运筹OR帷幄』特建立知识星球,依托社区30w+专业受众和30+细分领域硕博微信群,特邀国内外名校教授、博士及腾讯、百度、阿里、华为等公司大咖与大家一起聊算法。快来扫码加入,点对点提问50位大咖嘉宾!

# 加入知识星球,您将收获以下福利 #
全球Top名校教授|博士和名企研发高管一起交流算法相关学术|研发干货
中国你能说出名字的几乎所有大厂|欧美数家大厂(资深)算法工程师入驻
依托『运筹OR帷幄』30w+专业受众和30+细分领域硕博微信群的算法技术交流
以上所有公司|高校独家内推招聘|实习机会、多家offer选择指导
以面试题|作业题|业界项目为学习资料学习算法干货,从小白变成大咖
享受『运筹OR帷幄』各大城市线下Meetup免费入场资格,拓展人脉
本文福利
—— 完 ——
文章须知
责任编辑:周岩
审核编辑:阿春
微信编辑:玖蓁
本文由『运筹OR帷幄』原创发布
以上是关于AI | 图神经网络-Pytorch Biggraph简介及官方文档解读的主要内容,如果未能解决你的问题,请参考以下文章
图神经网络版本的PyTorch来了,Facebook开源GTN框架,还可对图自动微分
(d2l-ai/d2l-zh)《动手学深度学习》pytorch 笔记(序言pytorch的安装神经网络涉及符号)
送书 | AI插画师:如何用基于PyTorch的生成对抗网络生成动漫头像?
AI大事件 | 谷歌发布Cloud AutoML,PyTorch2017年总结,巨大神经网络适应内存方法