7 papers | PyTorch官方框架论文;浙大阿里等新方法提升唇读效果 Posted 2021-05-02 机器之心
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了7 papers | PyTorch官方框架论文;浙大阿里等新方法提升唇读效果相关的知识,希望对你有一定的参考价值。
本周既有深度学习社区非常关注的 PyTorch 框架论文,还有浙大和阿里巴巴等利用学习语音识别器增强唇读效果的研究。
PyTorch: An Imperative Style, High-Performance Deep Learning Library
On The Equivalence Between Node Embeddings And Structural Graph Representations
SEAN: Image Synthesis with Semantic Region-Adaptive Normalization
Hearing Lips: Improving Lip Reading by Distilling Speech Recognizers
Neural Academic Paper Generation
DEEP DOUBLE DESCENT: WHERE BIGGER MODELS AND MORE DATA HURT
A Simple Proof of the Quadratic Formula
论文 1:PyTorch: An Imperative Style, High-Performance Deep Learning Library
摘要:
近年来,随着深度学习的兴起,机器学习工具也如雨后春笋般发展起来。Caffe、CNTK、TensorFlow、Theano 等很多流行框架都构建了一个表征计算的静态数据流图,这些图可以重复应用于批量数据。但一直以来,这些深度学习框架要么关注易用性,要么关注速度,很难二者兼顾。PyTorch 的出现打破了这一限制。作为一个机器学习库,它提供了一种命令式、Python 式的编程风格,支持代码作为模型,使得调试变得简单,并且与其他流行的科学计算库保持一致,同时保持高效并支持 GPU 等硬件加速器。在这篇论文中,作者介绍了驱动 PyTorch 实现的详细原则以及这些原则在 PyTorch 架构中的反映。此外,作者还解释了如何谨慎而务实地实现 PyTorch 运行时的关键组件,使得这些组件能够协调配合,达到令人满意的性能。研究者在几个常见的基准上展示了 PyTorch 单个子系统的效率以及整体速度。
通过与三个流行的图深度学习框架(CNTK、MXNet 和 TensorFlow)、define-by-run 框架(Chainer)和生产导向型平台(PaddlePaddle)的比较,研究者从整体上得出了 PyTorch 的单机 eager 模式性能。 具体结果如表所示,PyTorch 的性能在最快框架性能的 17% 以内。
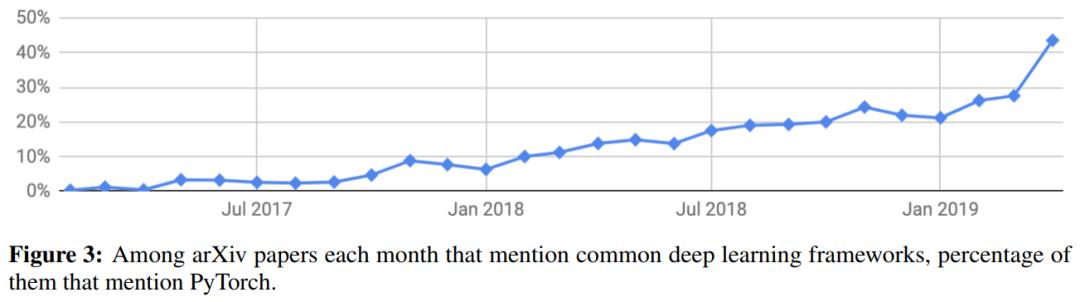
自 2017 年 1 月以来,在所有常见的深度学习框架中,PyTorch 在 arXiv 论文中每月被提及的比例。
推荐:
PyTorch 已开源好几年了,现在是最火热的深度学习框架之一。但是,和其他有着论文介绍的开源项目相比,PyTorch 背后的特性和思想还没有被完整介绍过。近日,趁着 NeurlPS 2019 大会即将召开,PyTorch 开发项目组也「水」了一篇论文——PyTorch 框架论文。这篇论文完整且系统地介绍了 PyTorch 本身,引起了社区的关注。
论文 2:On The Equivalence Between Node Embeddings And Structural Graph Representations
摘要:
在本文中,来自普渡大学计算机科学系的两位研究者提供了首个用于节点(位置)嵌入和结构化图表征的统一的理论框架,该框架结合了矩阵分解和图神经网络等方法。通过利用不变量理论(invariant theory),研究者表明,结构化表征和节点嵌入之间的关系与分布和其样本之间的关系类似。他们还证明,可以通过节点嵌入执行的任务也同样能够利用结构化表征来执行,反之亦然。此外,研究者还表明,直推学习和归纳学习的概念与节点表征和图表征无关,从而澄清了文献中的另一个困惑点。最后,研究者介绍了用于生成和使用节点嵌入的新的实践指南,从而修复了现在所使用的的标准操作流程的缺陷。
推荐:
实证研究结果表明,在本文提出的理论框架加持下,节点嵌入可以成功地作为归纳学习方法使用,并且 non-GNN 节点嵌入在大多数任务上的准确度显著优于简单的图神经网络(GNN)方法。
论文 3:SEAN: Image Synthesis with Semantic Region-Adaptive Normalization
摘要:
本论文要解决的问题是使用条件生成对抗网络(cGAN)生成合成图像。具体来说,本文要完成的具体任务是使用一个分割掩码控制所生成的图像的布局,该分割掩码的每个语义区域都具有标签,而网络可以根据这些标签为每个区域「添加」具有真实感的风格。尽管之前已经有一些针对该任务的框架了,但当前最佳的架构是 SPADE(也称为 GauGAN)。因此,本论文的研究也是以 SPADE 为起点的。具体来说,本文针对原始 SPADE 的两个缺陷提出了新的改进方案。本文在几个高难度的数据集(CelebAMaskHQ、CityScapes、ADE20K 和作者新建的 Facades 数据集)上对新提出的方法进行了广泛的实验评估。定量实验方面,作者基于 FID、PSNR、RMSE 和分割性能等多种指标对新方法进行了评估;定性实验方面,作者展示了可通过视觉观察进行评估的样本。
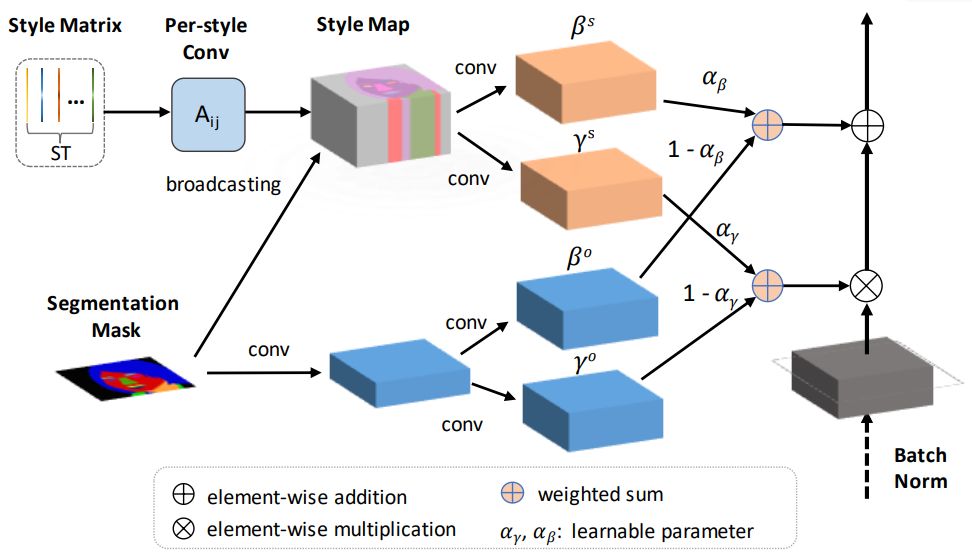
SEAN 归一化。 输入是风格矩阵 ST 和分割掩码 M。 在上部分,ST 中的风格代码会进行每风格卷积,然后根据 M 将其广播至它们对应的区域,从而得到风格映射图。 下部分(浅蓝色层)以与 SPADE 类似的方式仅使用区域信息创建每像素的归一化。
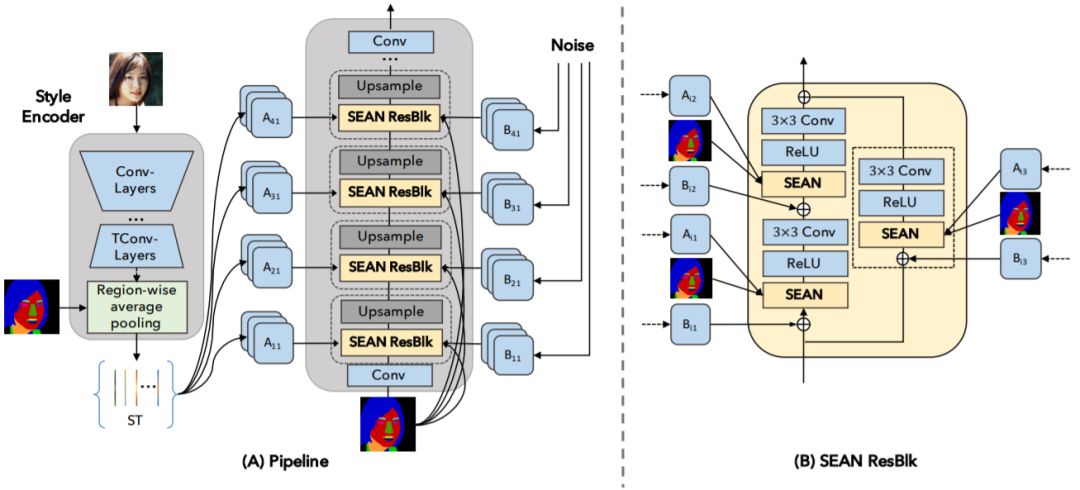
SEAN 生成器。 (A)在左图中,风格编码器以一张图像为输入,输出一个风格矩阵 ST。 右图的生成器由交错的 SEAN ResBlock 和 Upsample 层构成; (B)SEAN ResBlock 的详细情况。
推荐:
图像合成是近来非常热门的研究领域,世界各地的研究者为这一任务提出了许多不同的框架和算法,只为能合成出更具真实感的图像。阿卜杜拉国王科技大学和卡迪夫大学近日提出了一种新改进方案 SEAN,能够分区域对合成图像的内容进行控制和编辑(比如只更换眼睛或嘴),同时还能得到更灵活更具真实感的合成结果。有了这个技术,修图换眼睛时不用再担心风格不搭了。
论文 4:Hearing Lips: Improving Lip Reading by Distilling Speech Recognizers
摘要:
近年来,得益于深度学习和大型数据集的可用性,唇读(lip reading)已经出现了前所未有的发展。尽管取得了鼓舞人心的结果,但唇读的性能表现依然弱于类似的语音识别,这是因为唇读刺激因素的不确定性导致很难从嘴唇运动视频中提取判别式特征(discriminant feature)。
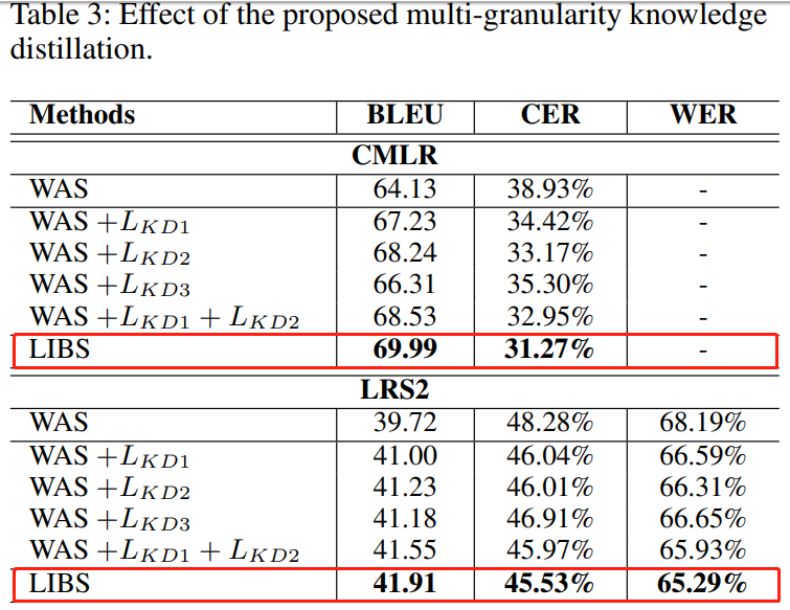
在本文中,来自浙江大学、斯蒂文斯理工学院和阿里巴巴的研究者提出了一种名为 LIBS(Lip by Speech)的方法,其目的是通过学习语音识别器来增强唇读效果。方法背后的基本原理是:提取自语音识别器的特征可能提供辅助性和判别式线索,而这些线索从嘴唇的微妙 yun'don 运动中很难获得,并且这些线索会因此促进唇阅读器的训练。具体而言,这是通过将语音识别器中的多粒度知识蒸馏到唇阅读器实现的。为了进行这种跨模式的知识蒸馏,研究者不仅利用有效的对齐方案来处理音频和视频之间长度不一致的问题,而且采用一种创造性的过滤策略来重新定义语音识别器的预测结果。研究者提出的方法在 CMLR 和 LRS2 数据集上取得了新的 SOTA 结果,在字符误差率(Character Error Rate,CER)方面分别超出基准方法 7.66% 和 2.75%。
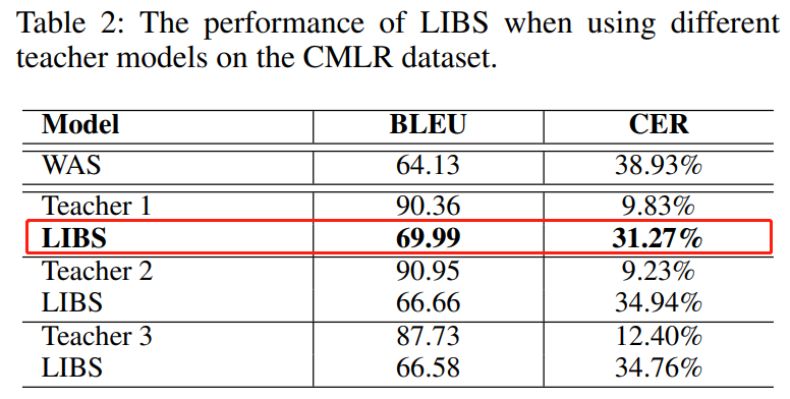
当使用不同的教师模型时,研究者提出的 LIBS 和 WAS 模型在 CMLR 数据集上的 BLEU 和 CER 数据对比。
研究者提出的 LIBS 方法在 CLMR 和 LRS2 数据集上的 CER 分别超出基准方法(WAS)。
推荐:
本文在唇读领域取得了新的 SOTA 结果,并且论文作者表示他们希望今后将该框架应用到语音和手语等其他多模态对中。
论文 5:Neural Academic Paper Generation
摘要:
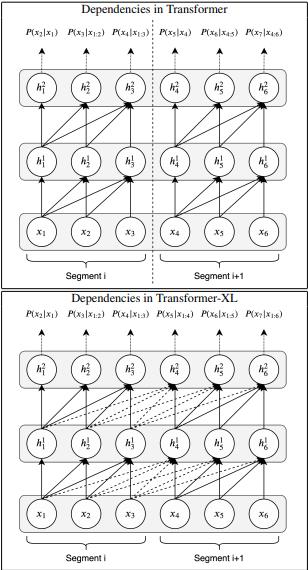
在本文中,受到基本字符级语言模型良好结果的启发,研究者解决了结构化的文本生成问题,尤其是 LATEX 中的学术论文生成问题。他们的动机是在更复杂的 LATEX 源文件数据集中使用更新、更高级的语言建模方法来生成现实的学术论文。本文的第一项贡献是在最近开源的计算机视觉论文上使用 LATEX 源文件的数据集;第二项贡献是尝试使用最新的语言建模和文本生成方法(例如 Transformer 和 Transformer-XL)来生成连贯的 LATEX 代码。研究者给出了经训练模型的交叉熵和每字符比特(bits per character,BPC)结果,并且还在生成的 LATEX 代码的一些示例中探讨了有趣的观点。
Transformer 与 Transformer-XL 的依赖对比。
推荐:
在这篇论文中,来自土耳其 Bogaziçi University 和伊斯坦布尔比尔基大学的研究者发现在文本生成,特别是论文生成领域,Transformer-XL 模型的性能优于 Char-LSTM 和 Transformer 模型。
论文 6:DEEP DOUBLE DESCENT: WHERE BIGGER MODELS AND MORE DATA HURT
摘要:
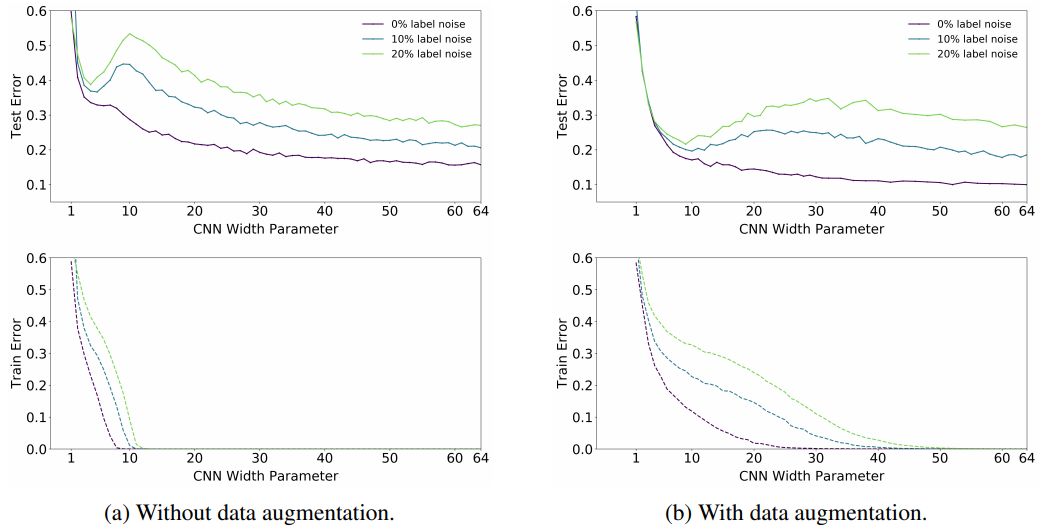
在本文中,研究者证明,各种现代深度学习任务都表现出「双重下降」现象,并且随着模型尺寸的增加,性能首先变差,然后变好。此外,他们表明双重下降不仅作为模型大小的函数出现,而且还可以作为训练时间点数量的函数。研究者通过定义一个新的复杂性度量(称为有效模型复杂性,Effective Model Complexity)来统一上述现象,并针对该度量推测一个广义的双重下降。此外,他们对模型复杂性的概念使其能够确定某些方案,在这些方案中,增加(甚至四倍)训练样本的数量实际上会损害测试性能。
用于 ResNet18 和 CNN(宽度为 128)的 Epoch-wise 双重下降。
推荐:
在本文中,哈佛大学联合 OpenAI 提出了泛化的双重下降假设,即当模型和训练过程的有效模型复杂性与训练样本数量相当时,它们会呈现出非典型的行为。
论文 7: A Simple Proof of the Quadratic Formula
摘要:
在一个「简单」问题上找到了一个新的、更好的解法,这真的是人类的第一次发现吗?前不久陶哲轩等人求解特征值向量的研究《Eigenvectors from Eigenvalues》,在令人兴奋的发表之后,还被认为是「重复造轮子」。对此罗博深对自己提出方法的原创性进行了一番探讨。简而言之,他研究了有关数学历史的大量文献,包括古巴比伦人、中国人、希腊人、印度人和阿拉伯人以及从文艺复兴时期到今天的现代数学家提出的方法,想要寻找前人发现过的可能性,然而并没有成功。看起来,我们有了一个全新的二次方程求解方法。
推荐:
不论你对数学是否感冒,全世界上过中学的人都会遇到这样一个挑战:背下二次方程的求解公式,然后学会如何使用它。不过最近来自卡耐基梅隆大学(CMU)的研究者找到了一个超级简单的推导方法。
以上是关于7 papers | PyTorch官方框架论文;浙大阿里等新方法提升唇读效果的主要内容,如果未能解决你的问题,请参考以下文章
Paper Mark2
推荐不可思议的PyTorch:PyTorch教程论文项目社区资源大汇总
学习笔记图神经网络库 DGL 入门教程(backend pytorch)
PyTorch笔记 - A ConvNet for the 2020s (ConvNeXt) 论文
PyTorch笔记 - A ConvNet for the 2020s (ConvNeXt) 论文
来势汹汹PyTorch!ICLR论文提及频率直追TensorFlow(附对比)