15分钟完成Kinetics视频识别训练,除了超级计算机你还需要TSM
Posted 机器之心
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了15分钟完成Kinetics视频识别训练,除了超级计算机你还需要TSM相关的知识,希望对你有一定的参考价值。
选自arXiv
作者:
Ji Lin, Chuang Gan, Song Han
大规模视频识别分布式训练往往具有较高的计算、数据加载和通信成本,为了解决这些问题,MIT 的研究者提出了三项设计原则,并基于这些原则设计了一种时间位移模块(TSM)。这一设计成功将在 Summit 超级计算机上需要近 50 小时的训练时间压缩到了不到 15 分钟。
深度视频识别的计算成本比图像识别更高,尤其是在 Kinetics 等大规模数据集上。因此,为了处理大量视频,可扩展性训练是至关重要的。这篇论文研究了影响视频网络的可扩展性的因素。研究者认定了三个瓶颈,包括数据加载(从磁盘向 GPU 移动数据)、通信(在网络中移动数据)和计算速度(FLOPs)。
针对这些瓶颈,研究者提出了三种可以提升可扩展性的设计原则:(1)使用 FLOPs 更低且对硬件友好的算子来提升计算效率;(2)降低输入帧数以减少数据移动和提升数据加载效率,(3)减少模型大小以降低网络流量和提升网络效率。
基于这些原则,研究者设计了一种新型的算子「时间位移模块(TSM:Temporal Shift Module)」,能够实现高效且可扩展的分布式训练。相比于之前的 I3D 模型,TSM 模型的吞吐量可以高出 1.8 倍。
研究者也通过实验测试了新提出的 TSM 模型。将 TSM 模型的训练扩展到了 1536 个 GPU 上,使用了包含 12288 个视频片段/ 98304 张图像的 minibatch,没有造成准确度损失。使用这样的硬件友好的模型设计,研究者成功地扩展了在 Summit 超级计算机上的训练,将在 Kinetics 数据集上的训练时间从 49 小时 55 分减少到了 14 分 13 秒,同时实现了 74.0% 的 top-1 准确度,这在准确度更高的同时还比之前的 I3D 视频模型快 1.6 和 2.9 倍。
在计算机视觉领域,视频识别是一个至关重要的分支。视频识别问题的难度更高,但得到的研究更少:(1)相比于 2D 图像模型,视频模型的计算成本通常高一个数量级。举个例子,很常见的 ResNet-50 模型的速度大约是 4G FLOPs,而 ResNet-50 I3D 则要消耗 33G FLOPs,多过 8 倍;(2)视频数据集比 2D 图像数据集大得多,而且数据 I/O 也比图像高很多。举个例子,ImageNet 有 128 万张训练图像,而视频数据集 Kinetics-400 有 6300 万训练帧,大约是前者的 50 倍;(3)视频模型的模型大小通常更大,因此需要更高的网络带宽来交换梯度。
这篇论文研究了视频的大规模分布式训练的瓶颈,包括计算、数据加载(I/O)、通信。
对应这些瓶颈,研究者又提出了用于解决这些难题的三项实用的设计原则:模型应当利用对硬件友好的算子来降低计算 FLOPs;模型应当使用更少的输入帧以节省文件系统 I/O;模型应当使用参数更少的算子以节省网络带宽。
基于这些原则,研究者提出了一种零 FLOPs 和零参数的高效视频 CNN 算子「时间位移模块(TSM:Temporal Shift Module)」。它可将 Kinetics 训练扩展到 1536 个 GPU 上,实现包含 12288 个视频片段/ 98304 张图像的 minibatch。整个训练过程可在 15 分钟内完成,并能实现 74.0% 的 top-1 准确度。相比于之前的两种 I3D 模型,TSM 模型在当前引领世界的 Summit 超级计算机上可实现分别高 1.6 和 2.9 倍的训练吞吐量。
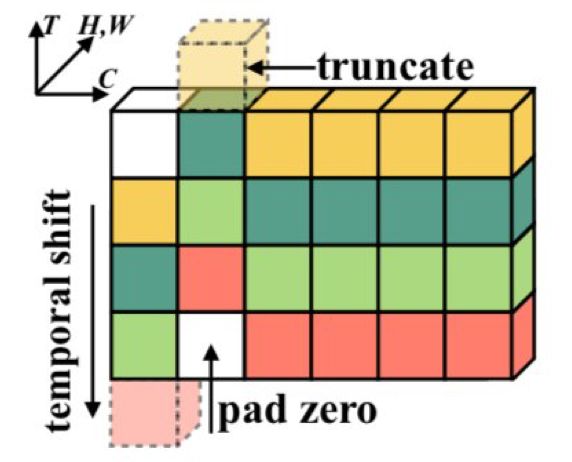
图 1:
时间位移模块(TSM)会沿时间维度位移通道,从而实现近邻帧之间的时间建模
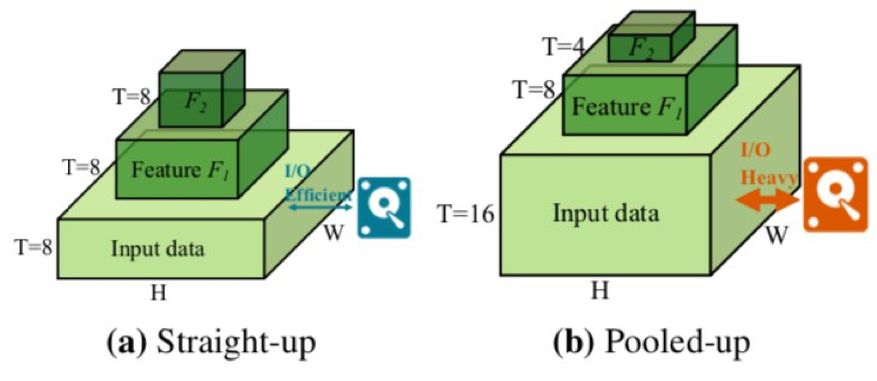
图 2:
两种类型的视频主干设计。
(a) 没有时序上的池化,对数据的利用更加高效。
(b) 需要更多的输入帧数,对 I/O 造成了压力。
为了解决分布式训练系统中的难题,研究者提出了三项视频模型设计原则:(1)为了提升计算效率,使用 FLOPs 更低且硬件效率更高的算子;(2)为了降低数据加载流量,使用「FLOPs/数据」比更高的网络拓扑结构;(3)为了降低网络流量,使用参数更少的算子。
借助于硬件友好的模型设计技术,研究者可将训练扩展到 1536 个 GPU 上,并能在 15 分钟内结束 Kinetics 训练。
在实验中,研究者使用了目前世界上最快的超级计算机 Summit。其由大约 4600 个计算节点构成,每一个节点都有两个 IBM POWER9 处理器和六个英伟达 Volta V100 加速器。POWER9 处理器通过两个 NVLINK bricks 相连,每一个在每个方向都有 25GB/s 的传输速度。节点包含供 POWER9 处理器使用的 512GB 内存和供加速器使用的 96GB 高带宽内存(HBM2)。
分布式训练使用了 PyTorch 和 Horovod。该框架使用 ring-allreduce 算法来执行同步随机梯度下降。训练使用了 CUDA 和 cuDNN 加速。大多数通信都使用了 NVIDIA Collective Communication Library (NCCL) 2。
实验使用的数据集为 Kinetics-400:https://deepmind.com/research/open-source/kinetics。该数据集包含 400 个人类动作类别,每个类别包含至少 400 段视频。该数据集包含大约 24 万段训练视频和 2 万段验证视频,每段视频持续时间为大约 10 秒钟。这样大的规模对模型训练和数据存储构成了严峻挑战。
训练过程持续了 100 epoch。研究者训练了一个有 8 帧输入的 TSM 网络,使用了固定的 n=8。初始学习率设置为每 8 个样本 0.00125,研究者使用了线性缩放规则来增大批大小更大时的学习率。训练过程使用了余弦式的学习率衰减,并有 5 epoch 的预热。权重衰减为 1e-4,没有使用 dropout。另外,没有在批归一化和偏置上使用权重衰减。
测试方法是每段视频采样 10 个片段并计算平均预测结果。视频的大小都经过了部分调整,短边大小均调整为 256,然后再输入网络。

表 1:
不同模型的效率统计。
箭头表示越大或越小的结果更好
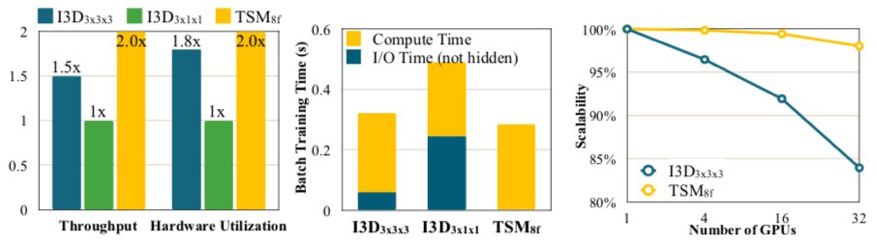
图 3:
分析不同的设计方面将如何影响视频识别模型的分布式训练可扩展性:
(a)计算效率;
(b)数据加载效率;
(c)网络效率
表 2:
每个块的输出特征图的时间分辨率。
TSM 是全 2D 结构,具有最佳的硬件效率。
I3D3×3×3 的最后几个阶段的时间分辨率更低,这使其更接近 2D CNN,因此相比于 I3D3×1×1 有更好的硬件效率。
图 6:
分布式同步 SGD 训练的吞吐量和可扩展性。
甚至当使用 1536 个 GPU 时,TSM8f 也能实现很好的可扩展性(>80%)。
TSM8f 的训练吞吐量比 I3D3×3×3 高 1.6 倍,比 I3D3×1×1 高 2.9 倍,这表明新提出的设计原则是有效的。
✄------------------------------------------------
加入机器之心(全职记者 / 实习生):hr@jiqizhixin.com
投稿或寻求报道:content@jiqizhixin.com
广告 & 商务合作:bd@jiqizhixin.com
以上是关于15分钟完成Kinetics视频识别训练,除了超级计算机你还需要TSM的主要内容,如果未能解决你的问题,请参考以下文章
采用百度飞桨EasyDL完成指定目标识别
3D ResNet 相关论文解读与模型测试
何恺明等最新突破:视频识别快慢结合,取得人体动作AVA数据集最佳水平
18组-Quo Vadis, Action Recognition? A New Model and the Kinetics Dataset
视频识别:SlowFast Networks
极客日报:Twitter 移除了谷歌 FLoC 跟踪技术的支持;iOS 15 引入基于半身照的人物识别功能