视频识别:SlowFast Networks
Posted 老黄陪你读paper
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了视频识别:SlowFast Networks相关的知识,希望对你有一定的参考价值。
本次介绍的文章《SlowFast Networks for Video Recognition》来自于FAIR,提出了一种SlowFast网络架构用于视频行为识别。网络类似于双流结构,包含:
慢速流:低帧率来捕获图像的空间语义信息。
快速流:高帧率捕获运动行为,网络轻量级。
模型在视频的动作分类和检测上均表现出色,在Kinetics上达到了79.8%的精度,Charades and AVA等上也达到了 state-of-the-art的水平。
文中提出的SlowFast的概念,通过语义空间和运动行为的分别处理和融合,为视频动作识别提供了一些新的思路,这篇文章的试验做的非常详细,特别是对比消融试验对细节参数等进行很多的分析。
源码github链接:
https://github.com/facebookresearch/SlowFast
01
背景与介绍
视频行为识别,主要是识别视频中的行为动作。例如要识别一个视频是否存在打架这一行为,需要关注视频中的人并分辨视频中人的行为动作。相对于图像识别,视频识别除了与图像的空间信息有关,还与时间序列有关,是一个时空问题。
视频识别的主流技术以下几种:
基于单帧的识别方法:抛弃了时间序列,只采样提取一帧图像识别,效果不佳。
扩展卷积的识别方法:单帧抛弃了时间,将卷积方法进行扩展,根据w,h,c,t对卷积进行扩展。这种方法将卷积核扩展到了时域,进行3D的卷积。
LSTM方法:LSTM对时间序列处理有效,将时间信号融入进来。
双路网络:一路进行单帧的CNN,另一路将多帧的图像融合到一起,再经过CNN。最终结合两路的结果作最后的分类。
对于图像I(x,y)识别问题,因为图像的特性很自然的将图像看为x和y两个对称空间维度。但对于视频I(x,y,t)识别,运动是时空对应的,并不能将时间维度简单的看为第三个空间维度,所以单纯的将卷积进行扩展,效果提升有限。
作者认为时空不能一致的对待处理(时间上非对称),但可以分别处理空间场和时间场。分两步走:空间上识别对象,时间上识别行为。
在空间特征上,比如挥动的手,手这个对象变化是缓慢的,所以可以相对缓慢地刷新对类别语义(包括颜色,纹理,光照等)的识别。另一方面,在识别比如拍打和跳跃等行为,可能希望高时间分辨率的图像来有效地识别快速变化的运动。
基于上述的分析,作者提出了一种用于视频识别的双流SlowFast网络。
02
网络结构
灵长类动物视觉系统中视网膜神经细胞的生物学研究发现,在这些细胞中,80%是P细胞,而15-20%的M细胞。其中M细胞以较高的时间频率运行,对快速的变化做出响应,但对空间细节或颜色不敏感。P细胞时间分辨率较低,但可提供良好的空间细节和色彩。
类似于灵长类的视觉系统,作者设计的网络具有许多的相似之处:
慢速流,捕获空间细节信息。
快速流,捕获运动信息,且轻量级,总的计算比例大约为20%。
横向连接,快速流的动作信心融合到慢速流的空间信息中。
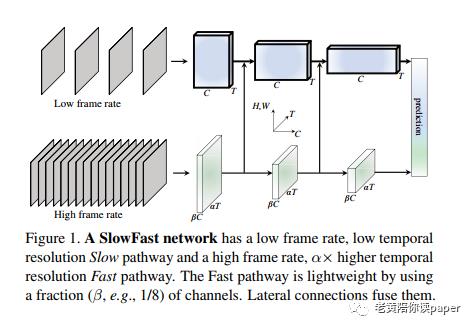
如图1所示,是整体的网络结构。慢速流和快速流输入的是同一个视频,两者的采样频率不同。中间各个层,两者都通过横向连接融合,最后对每个流的输出执行全局平均池化,然后将两个池化的特征向量串联起来,作为全连接分类器层的输入。
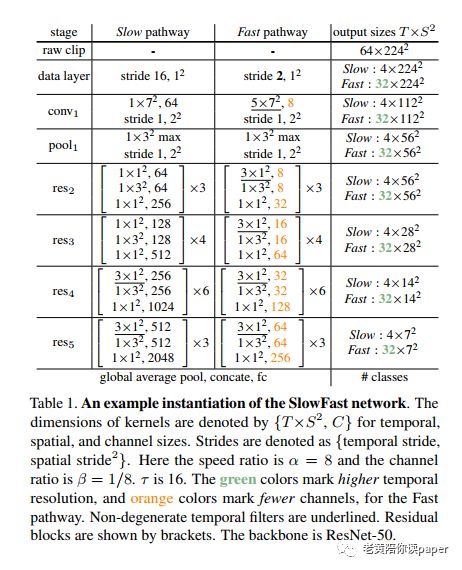
表1是以ResNet50作为backbone的一个SlowFast实例:
2.1
慢速流
慢速分支的“慢”体现在输入帧的时间跨度上,参数称之为τ。对于30fps的视频,默认τ=16,即约每秒采样2帧。将慢速流中总采样时间表示为T,那么输入的视频总的帧数为T×τ帧。
表1中实例中参数T=4帧,τ=16,网络从64帧原始图像中稀疏采样。从conv1到res3都是2D卷积核,在res4和res5才进行时间维度的压缩。因为通过试验观察,较早层中的时间卷积会降低准确性。作者认为当物体移动得很快而且时间跨度很大时,只有空间感受野足够大时,时间上才有相关性。即空间感受野较小时看不到整体的对象随时间变化,导致在浅层在时间维度上相关性就很小,做时间尺度上的卷积效果不好。
2.2
快速流
高帧率:时间跨度为τ/α,α是快速流和慢速流的帧频比(α>1)。快速通道每τ/α时间就采样了αT帧,比慢速通道α倍的密集。试验中默认值为α= 8。
高时间分辨率:整个快速流,在全局池化层前都没有在任何时间上进行下采样层操作,尽可能地保留时间保真度。
通道数量低:快速流与慢速流类似,都是一个卷积网络,但是快速流的通道比率为β(β<1)。实验中默认值为β=1/8。通道数是计算量的二次方,通过减少通道数,使得快速流变得轻量级,只占总计算量的20%。
虽然低通道的空间语义能力较弱,但是这个分支主要关注时间维度上的变化,所以理论上空间建模能力弱影响不大。
2.3
横向连接
横向连接是一种用于合并不同级别的空间分辨率和语义的常用技术。快速流关注行为,慢速流关注语义空间,通过横向连接可以将两者信息融合到一起。图1网络结构中每个stage的两个路径之间都有横向连接,紧接在pool1,res2,res3和res4之后。
快速流的特征图形状:[T,SxS,C],慢速流的特征图形状:[αT,SxS,βC]。侧向连接时两者维度需要匹配融合。总共有三种方式:
时间转变为通道:重新转变[αT,SxS,βC]为[T,SxS,αβC]。
时间维度抽样:每α个帧抽取1帧,将[αT,SxS,βC]为[T,SxS,βC]。
3D卷积:时间维度上stride=α,kernel_size=5x5,输出channel=2βC,通过卷积实现匹配。
03
试验结果
3.1
数据集介绍
视频行为分类:
Kinetics-400:约240k训练集和20k个验证集,400种人类行为类别。
Kinetics-600:约392k训练集和30k验证集,共600个类别。
Charades:9.8k训练集和1.8k验证集,采用多标签标注,一共157个类别。视频时间平均为30秒。
视频动作检测:
AVA数据集:通过时空位置来检测人类行为。数据取自437电影,1帧/秒提供每个人的一个边界框和动作(可能有多个)标注,211k训练集和57k验证集,一共60个类。
3.2
训练与评测
训练:初始化不使用ImageNet或任何预训练。
对于时域,在一个完整视频中随机采样一个αT×τ帧的片段,慢速流和快速流输入分别是T和αT帧;
对于空间域,将短边放缩到[256,320]像素中,然后水平随机翻转以及随机裁剪224×224像素。
对于视频动作检测的训练细节可参照原文。
评测:
视频行为分类:从视频中均匀采样10个片段。对于每个片段将较短边缩放到256像素,然后裁剪256×256的图片裁剪3次来覆盖空间尺寸。最终相当于将30个片段结果通过softmax平均后进行预测。在结果中报告了精度和计算时间。
视频动作检测:指标是平均精度(mAP),使用的框架级IoU阈值为0.5。
3.3
视频动作分类
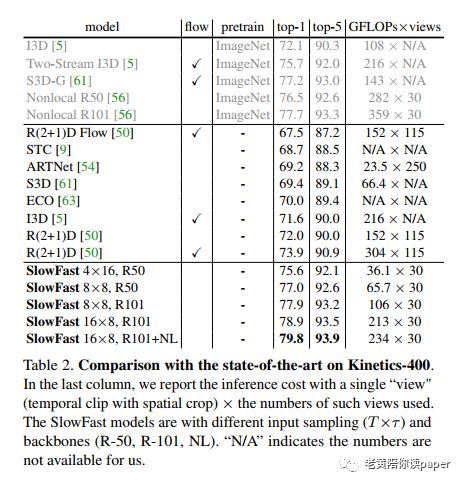
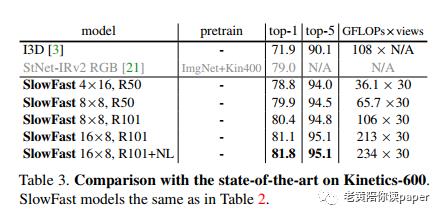
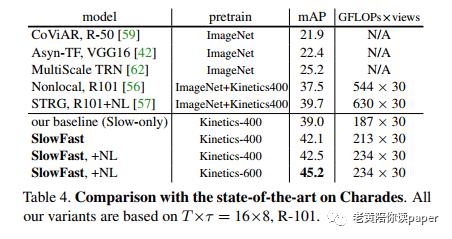
表2显示了在Kinetics-400上的精度以及计算量。与其他最好的方案相比,top-1提高了2.1%。
比较SlowFast是否预训练的影响,试验结果发现两者精度(±0.3%),差别不大。
Kinetics-600的结果达到了81.8%,相比现今最高的模型79.0%,top1提高了2.8%。
Charades结果上,SlowFast在基准上增加3.1mAP。
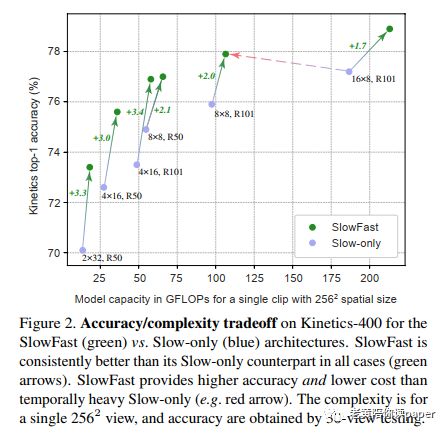
快速流分支的效果:从图2结果中可以看到,当提高慢速流中的帧数,精度提高但是计算量加倍。而加入了快速流,在只增加一小点计算量的条件下精度提高了很多。
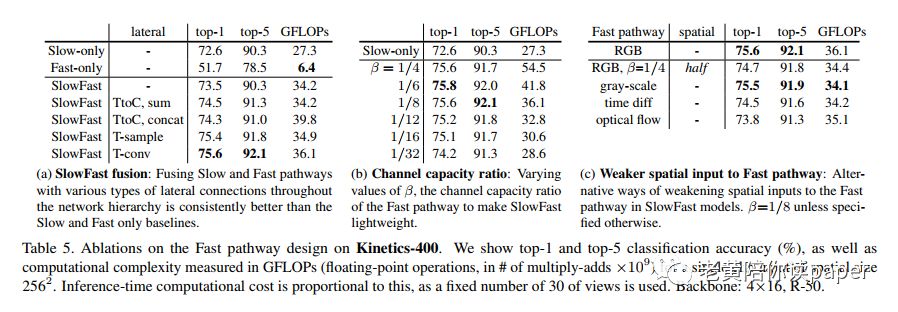
横向连接方式:最简单的串联方式,精度提升了0.9%。后续测试了2.3中的三种横向连接方式,表5a中结果显示,时间维度上的卷积表现最佳,提升了3.0%。
快速流通道容量:通过通道比β来控制快速流的通道数量。结果如表5b所示,效果最好的β值是1/6和1/8。同时从实验中发现不管β取值为1/32到1/4,实验结果都比单个slow分支要好,也变相证明了fast的有效性。
输入空间的大小:因为快速流负责时间域,空间域不大需要管,所以尝试降低输入空间的大小。表5c的实验结果显示快速流的灰度图版本结果几乎与RGB相同,同时计算量降低了5%。
上述的消融试验通过不同的参数试验以及变体,除了对参数的效果进行消融试验证明外,也证实了快速流的加入显著的增强了视频行为识别的性能。
3.4
视频动作检测
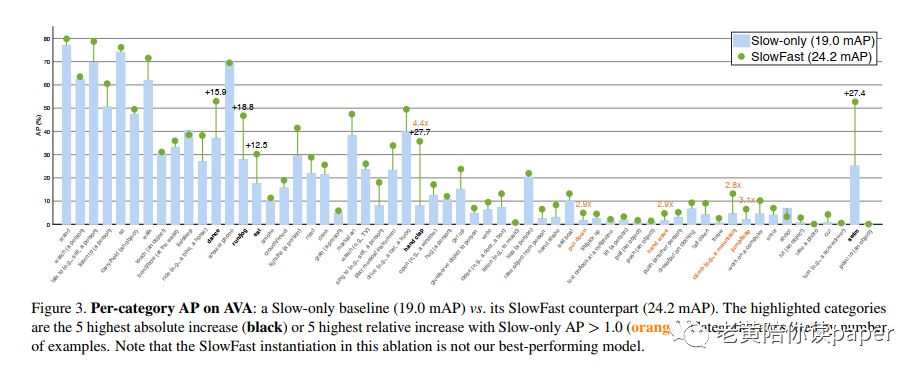
同样的,在视频动作检测中SlowFast显著提升了性能。作者利用AVA数据集做了验证,也对快速流、快速流的通道数等做了消融试验,说明了其有效性。
特别的,在图3中按类别进行可视化,对于一些行为动作,如“拍手”(+27.7AP),“游泳”增加了(+27.4 AP),“跑步/慢跑”(+18.8 AP),“跳舞”(+15.9 AP)和“进餐”(+12.5 AP)。这些都和快速的动作行文有很大的关系。
04
后记
这篇文章出自FAIR,他们的文章总是深入浅出,让人醍醐灌顶醍。正如他们文中所说,希望提供一种思路,针对动作行为识别中图像空间和时间域的特点,提出针对性处理时间和空间并融合的双流结构。同时,文章的实验做的非常的详细,对于各个参数的消融等,都分析了其作用以及特点。作者已经提供了源码,如果有条件可以进行在源码基础上进行一些实验。
这篇文章主要也是针对动作行为数据集的一个时空特点,提出了这样一种框架。个人思考了以下几个问题:
对待行为识别问题,快速流主要关注时间域动作行为的变化,那么是否可以用图卷积,关注关键节点的图序列的变化?
方案领域的适用性,实际想要探索下对于一些特定领域的视频序列数据特点的归纳总结?
如需转载,请后台留言。
参考资料:
Christoph Feichtenhofer, Haoqi Fan, Jitendra Malik, Kaiming He. SlowFast Networks for Video Recognition.

老黄陪你读paper
github:https://github.com/JaryHuang
以上是关于视频识别:SlowFast Networks的主要内容,如果未能解决你的问题,请参考以下文章