Flink1.11+Hive批流一体数仓
Posted DataFunTalk
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Flink1.11+Hive批流一体数仓相关的知识,希望对你有一定的参考价值。

分享嘉宾:李锐 阿里巴巴 技术专家
编辑整理:马小宝
出品平台:DataFunTalk
Flink与Hive集成的背景介绍
Flink 1.11中的新特性
打造Hive批流一体数仓
为什么要做Flink和Hive集成的功能呢?最早的初衷是我们希望挖掘Flink在批处理方面的能力。众所周知,Flink在流计算方面已经是成功的引擎了,使用的用户也非常多。在Flink的设计理念当中,批计算是流处理中的一个特例。也就意味着,如果Flink在流计算方面做好,其实它的架构也能很好的支持批计算的场景。在批计算的场景中,SQL是一个很重要的切入点。因为做数据分析的同学,他们更习惯使用SQL进行开发,而不是去写DataStream或者DataSet这样的程序。
Hadoop生态圈的SQL引擎,Hive是一个事实上的标准。大部分的用户环境中都会使用到了Hive的一些功能,来搭建数仓。一些比较新的SQL的引擎,例如Spark SQL、Impala,它们其实都提供了与Hive集成的能力。为了方便的能够对接上目前用户已有的使用场景,所以我们认为对Flink而言,对接Hive也是不可缺少的功能。
因此,我们在Flink 1.9当中,就开始提供了与Hive集成的功能。当然在1.9版本里面,这个功能是作为试用版发布的。到了Flink 1.10版本,与Hive集成的功能就达到了生产可用。同时在Flink 1.10发布的时候,我们用10TB的TPC-DS测试集,对Flink和Hive on MapReduce进行了对比,对比结果如下:
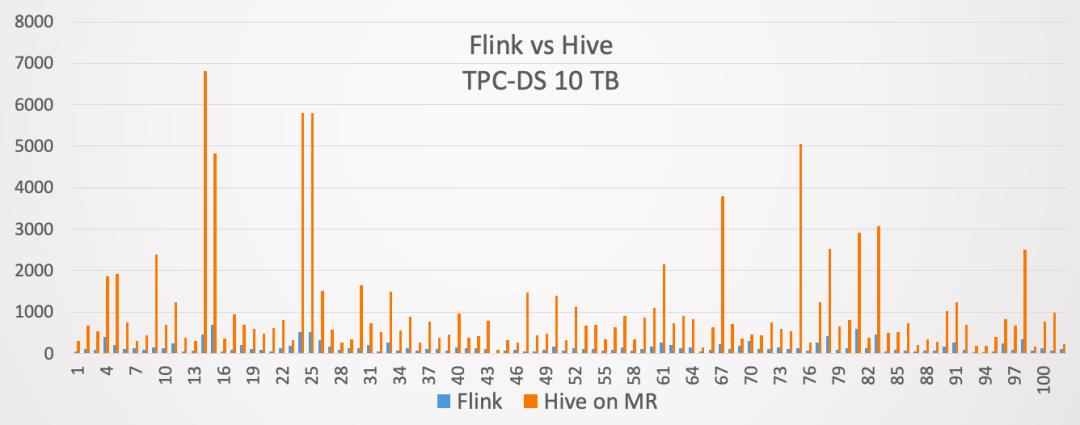
蓝色的方框表示Flink用的时间,桔红色的方框表示Hive on MapReduce用的时间。最终的结果是Flink对于Hive on MapReduce大概提升了7倍左右的性能。所以验证了Flink SQL可以很好的支持批计算的场景。
接下来介绍下Flink对接Hive的设计架构。对接Hive的时候需要几个层面,分别是:
能够访问Hive的元数据;
读写Hive表数据;
Production Ready;
1. 访问Hive元数据
使用过Hive的同学应该都知道,Hive的元数据是通过Hive Metastore来管理的。所以意味着Flink需要打通与Hive Metastore的通信。为了更好的访问Hive元数据,在Flink这边是提出了一套全新设计的Catalog API。
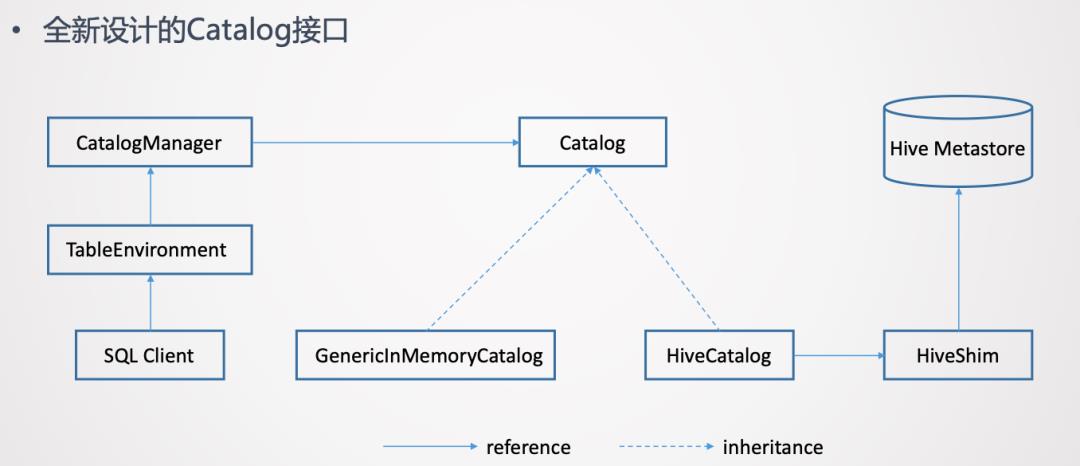
这个全新的接口是一个通用化的设计。它并不只是为了对接Hive元数据,理论上是它可以对接不同外部系统的元数据。
而且在一个Flink Session当中,是可以创建多个Catalog,每一个Catalog对应于一个外部系统。用户可以在Flink Table API或者如果使用的是SQL Client的话,可以在Yaml文件里指定定义哪些Catalog。然后在SQL Client创建TableEnvironment的时候,就会把这些Catalog加载起来。TableEnvironment通过CatalogManager来管理这些不同的Catalog的实例。这样SQL Client在后续的提交SQL语句的过程中,就可以使用这些Catalog去访问外部系统的元数据了。
上面这张图里列出了2个Catalog的实现。一个是GenericlnMemoryCatalog,把所有的元数据都保存在Flink Client端的内存里。它的行为是类似于Catalog接口出现之前Flink的行为。也就是所有的元数据的生命周期跟SQL Client的Session周期是一样的。当Session结束,在Session里面创建的元数据也就自动的丢失了。
另一个是对接Hive着重介绍的HiveCatalog。HiveCatalog背后对接的是Hive Metastore的实例,要与Hive Metastore进行通信来做元数据的读写。为了支持多个版本的Hive,不同版本的Hive Metastore的API可能存在不兼容。所以在HiveCatalog和Hive Metastore之间又加了一个HiveShim,通过HiveShim可以支持不同版本的Hive。
这里的HiveCatalog一方面可以让Flink去访问Hive自身有的元数据,另一方面它也为Flink提供了持久化元数据的能力。也就是HiveCatalog既可以用来存储Hive的元数据,也可以存Flink使用的元数据。例如,在Flink中创建一张Kafka的表,那么这张表也是可以存到HiveCatalog里的。这样也就是为Flink提供了持久化元数据的能力。在没有HiveCatalog之前,是没有持久化能力的。
2. 读写Hive表数据
有了访问Hive元数据的能力后,另一个重要的方面是读写Hive表数据。Hive的表是存在Hadoop的file system里的,这个file system是一个HDFS,也可能是其他文件系统。只要是实现了Hadoop的file system接口的,理论上都可以存储Hive的表。
在Flink当中:
读数据时实现了HiveTableSource
写数据时实现了HiveTableSink
而且设计的一个原则是:希望尽可能去复用Hive原有的Input/Output Format、SerDe等,来读写Hive的数据。这样做的好处主要是2点,一个是复用可以减少开发的工作量。另一个是复用好处是尽可能与Hive保证写入数据的兼容性。目标是Flink写入的数据,Hive必须可以正常的读取。反之,Hive写入的数据,Flink也可以正常读取。
3. Production Ready
在Flink 1.10中,对接Hive的功能已经实现了Production Ready。实现Production Ready主要是认为在功能上已经完备了。具体实现的功能如下:

下面将介绍下,在Flink 1.11版本中,对接Hive的一些新特性。
1. 简化的依赖管理
首先做的是简化使用Hive connector的依赖管理。Hive connector的一个痛点是需要添加若干个jar包的依赖,而且使用的Hive版本的不同,所需添加的jar包就不同。例如下图:
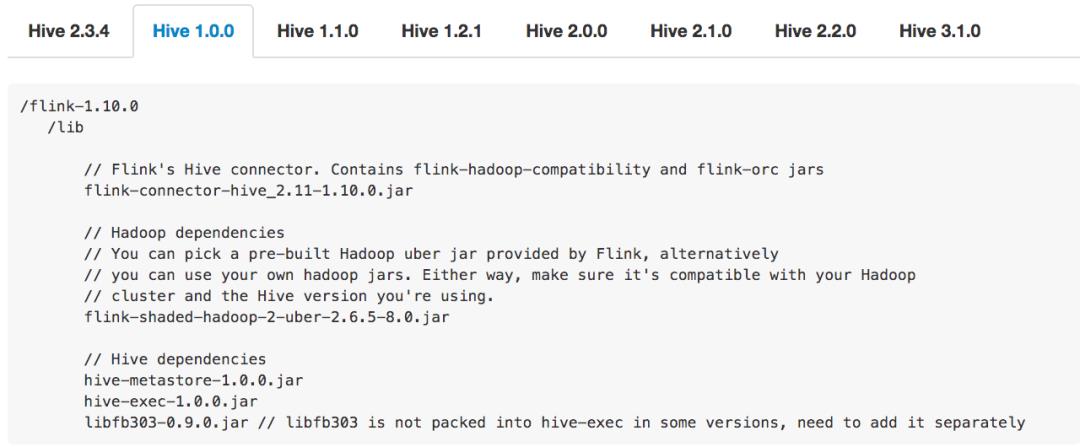
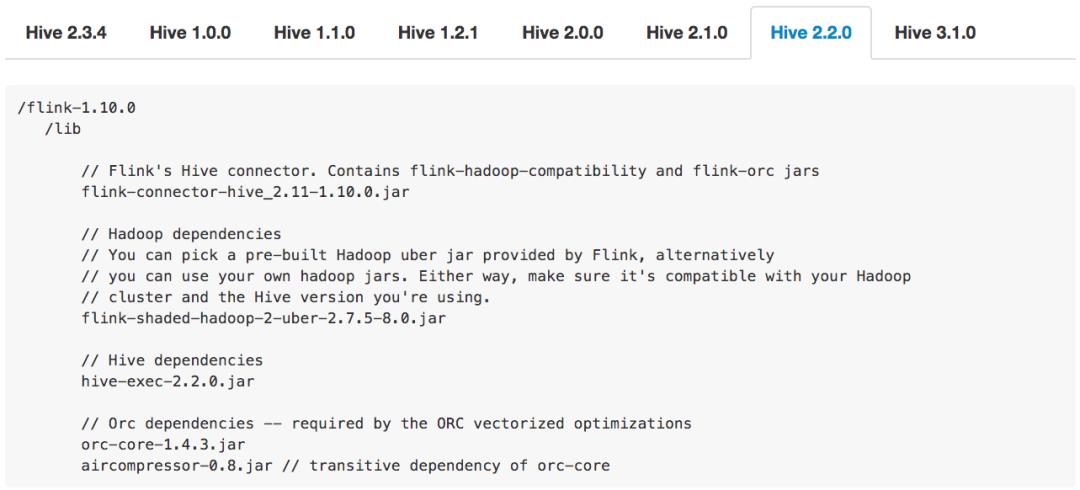
第一张图是使用的Hive 1.0.0版本需要添加的jar包。第二张图是用Hive 2.2.0版本需要添加的jar包。可以看出,不管是从jar包的个数、版本等,不同Hive版本添加的jar包是不一样的。所以如果不仔细去读文档的话,就很容易导致用户添加的依赖错误。一旦添加错误,例如添加少了或者版本不对,那么会报出来一些比较奇怪、难理解的错误。这也是用户在使用Hive connector时暴露最多的问题之一。
所以我们希望能简化依赖管理,给用户提供更好的体验。具体的做法是,在Flink 1.11版本中开始,会提供一些预先打好的Hive依赖包:

用户可以根据自己的Hive版本,选择对应的依赖包就可以了。
如果用户使用的Hive并不是开源版本的Hive,用户还是可以使用1.10那种方式,去自己添加单个jar包。
2. Hive Dialect 的增强
在Flink 1.10就引入了Hive Dialect,但是很少有人使用,因为这个版本的Hive Dialect功能比较弱。仅仅的一个功能是:是否允许创建分区表的开关。就是如果设置了Hive Dialect,那就可以在Flink SQL中创建分区表。如果没设置,则不允许创建。
另一个关键的是它不提供Hive语法的兼容。如果设置了Hive Dialect并可以创建分区表,但是创建分区表的DDL并不是Hive的语法。
在Flink 1.11中着重对Hive Dialect的功能进行了增强。增强的目标是:希望用户在使用Flink SQL Client的时候,能够获得与使用Hive CLI或Beeline近似的使用体验。就是在使用Flink SQL Client中,可以去写一些Hive特定的一些语法。或者说用户在迁移至Flink的时候,Hive的脚本可以完全不用修改。
为了实现上述目标,在Flink 1.11中做了如下改进:
给Dialect做了参数化,目前参数支持default和hive两种值。default是Flink自身的Dialect,hive是Hive的Dialect。
SQL Client和API均可以使用。
可以灵活的做动态切换,切换是语句级别的。例如Session创建后,第一个语句想用Flink的Dialect来写,就设置成default。在执行了几行语句后,想用Hive的Dialect来写,就可以设置成hive。在切换时,就不需要重启Session。
兼容Hive常用DDL以及基础的DML。
提供与Hive CLI或Beeline近似的使用体验。
3. 开启Hive Dialect
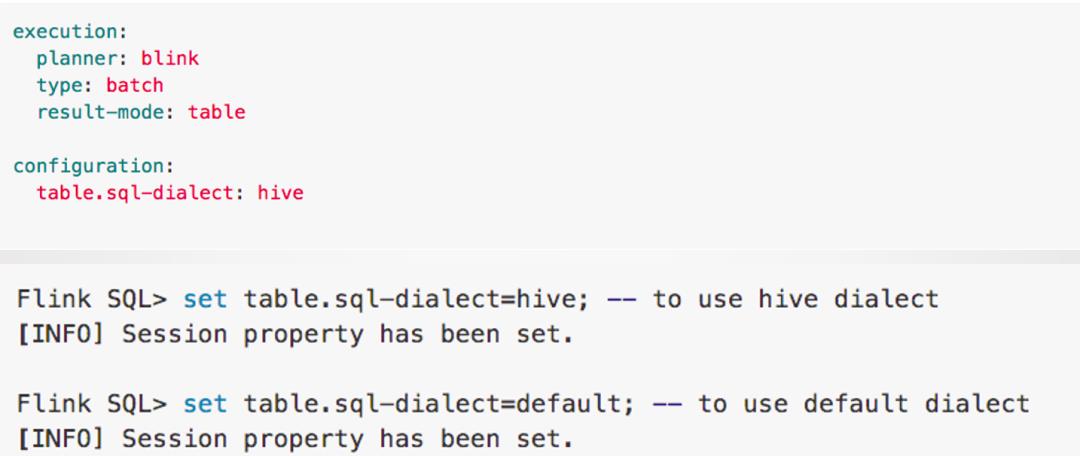
上图是在SQL Client中开启Hive Dialect的方法。在SQL Client中可以设置初始的Dialect。可以在Yaml文件里设置,也可以在SQL Client起来后,进行动态的切换。
还可以通过Flink Table API的方式开启Hive Dialect:

可以看到通过TableEnvironment去获取Config然后设置开启。
4. Hive Dialect支持的语法
Hive Dialect的语法主要是在DDL方面进行了增强。因为在1.10中通过Flink SQL写DDL去操作Hive的元数据不是十分可用,所以要解决这个痛点,将主要精力集中在DDL方向了。
目前所支持的DDL如下:


5. 流式数据写入Hive
在Flink 1.11中还做了流式数据场景,以及跟Hive相结合的功能,通过Flink与Hive 的结合,来帮助Hive数仓进行实时化的改造。

流式数据写入Hive是借助Streaming File Sink实现的,它是完全SQL化的,不需要用户进行代码开发。流式数据写入Hive也支持分区和非分区表。Hive数仓一般都是离线数据,用户对数据一致性要求比较高,所以支持Exactly-Once语义。流式数据写Hive大概有5-10分钟级别的延迟。如果希望延迟尽可能的低,那么产生的一个结果就是会生成更多的小文件。小文件对HDFS来说是不友好的,小文件多了以后,会影响HDFS的性能。这种情况下可以做一些小文的合并操作。
流式数据写入Hive需要有几个配置的地方:

对于分区表来说,要设置Partition Commit Delay的参数。这个参数的意义就是控制每个分区包含多长时间的数据,例如可设置成天、小时等。
Partition Commit Trigger 表示Partition Commit什么时候触发,在1.11版本中支持Process-time 和 Partition-time触发机制。
Partition Commit Policy表示用什么方式提交分区。对于Hive来说,是需要将分区提交到metastore,这样分区才是可见的。metastore策略只支持Hive表。还有一个是success-file方式,success-file是告诉下游的作业分区的数据已经准备好了。用户也可以自定义,自己去实现一个提交方式。另外Policy可以指定多个的,例如可以同时指定metastore和success-file。
下面看下流式数据写入Hive的实现原理:
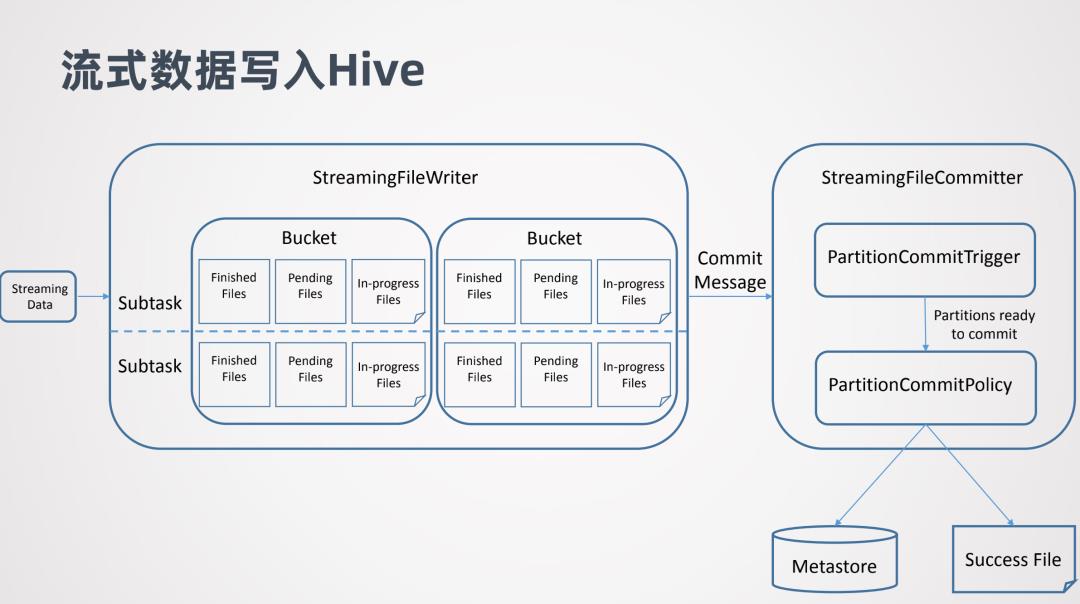
主要是两个部分,一个是StreamingFileWriter,借助它实现数据的写入,它会区分Bucket,这里的Buck类似Hive的分区概念,每个Subtask都会往不同的Bucket去写数据。每个Subtask写的Bucket同一个时间可能会维持3种文件,In-progress Files表示正在写的文件,Pending Files表示文件已经写完了但是还没有提交,Finished Files表示文件已经写完并且也已经提交了。
另一个是StreamingFileCommitter,在StreamingFileWriter后执行。它是用来提交分区的,所以对于非分区表就不需要它了。当StreamingFileWriter的一个分区数据准备好后,StreamingFileWriter会向StreamingFileCommitter发一个Commit Message,Commit Message告诉StreamingFileCommitter那些数据已经准备好了的。然后进行提交的触发Commit Trigger,以及提交方式Commit Policy。
下面是一个具体的例子:

例子中创建了一个叫hive_table的分区表,它有两个分区dt和hour。dt代表的是日期的字符串,hour代表小时的字符串。Commit trigger设置的是partition-time,Commit delay 设置的是1小时,Commit Policy设置的是metastore和success-file。
6. 流式消费Hive
在Flink 1.10中读Hive数据的方式是批的方式去读的,从1.11版本中,提供了流式的去读Hive数据。

通过不断的监控Hive数据表有没有新数据,有的话就进行增量数据的消费。
如果要针对某一张Hive表开启流式消费,可以在table property中开启,或者也可以使用在1.11中新加的dynamic options功能,可以查询的时候动态的指定Hive表是否需要打开流式读取。
流式消费Hive支持分区表和非分区表。对于非分区表会监控表目录下新文件添加,并增量读取。对于分区表通过监控分区目录和Metastore的方式确认是否有新分区添加,如果有新增分区,就会把新增分区数据读取出来。这里需要注意,读新增分区数据是一次性的。也就是新增加分区后,会把这个分区数据一次性都读出来,在这之后就不再监控这个分区的数据了。所以如果需要用Flink流式消费Hive的分区表,那应该保证分区在添加的时候它的数据是完整的。

流式消费Hive数据也需要额外的指定一些参数。首先要指定消费顺序,因为数据是增量读取,所以需要指定要用什么顺序消费数据,目前支持两种消费顺序create-time和partition-time。
用户还可以指定消费起点,类似于消费kafka指定offset这样的功能,希望从哪个时间点的数据开始消费。Flink去消费数据的时候,就会检查并只会读取这个时间点之后的数据。
最后还可以指定监控的间隔。因为目前监控新数据的添加都是要扫描文件系统的,可能你希望监控的不要太频繁,太频繁会给文件系统造成比较大的压力。所以可以控制一个间隔。
最后看下流式消费的原理。先看流式消费非分区表:

图中ContinuoousFileMonitoringFunction会不断监控非分区表目录下面的文件,会不断的跟文件系统进行交互。一旦发现有新的文件添加了,就会对这些文件生成Splits,并将Splits传到ContinuoousFileReaderOperator,FileReaderOperator拿到Splits后就会到文件系统中实际的消费这些数据,然后把读出来的数据再传往下游处理。
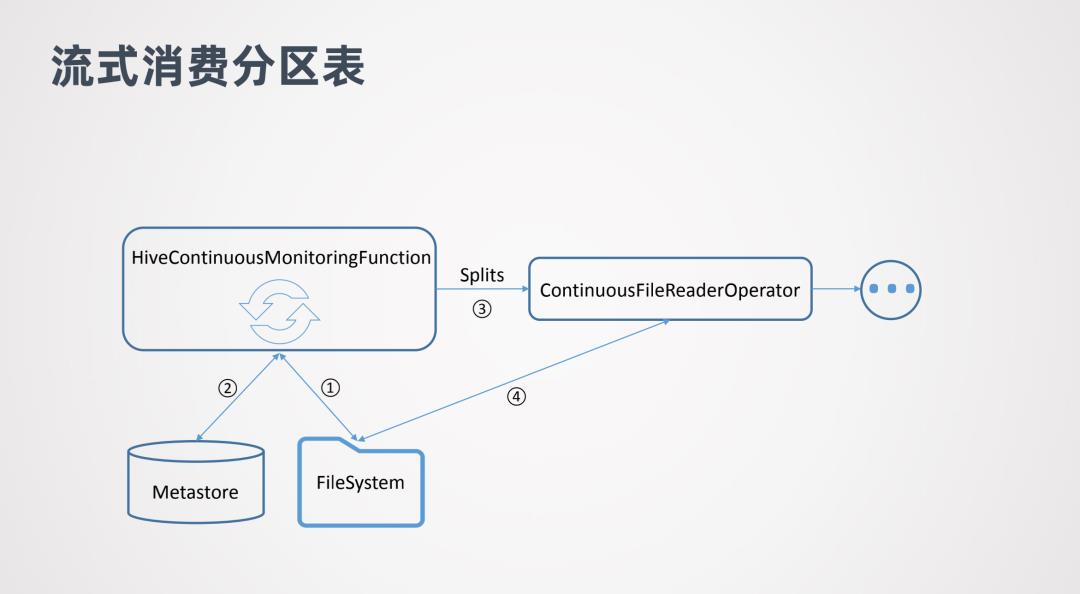
对于流式消费分区表和非分区表区别不是很大,其中HiveContinuousMonitoringFunction也会去不断的扫描文件系统,但是它扫描的是新增分区的目录。当它发现有新增的分区目录后,会进一步到metstore中做核查,查看是否这个分区已经提交到metstore中。如果已经提交,那就可以消费分区中的数据了。然后会把分区中的数据生成Splits传给ContinuousFileReaderOperator,然后就可以对数据进行消费了。
7. 关联Hive维表
关于Hive跟流式数据结合的另一个场景就是:关联Hive维表。例如在消费流式数据时,与一张线下的Hive维表进行join。

关联Hive维表采用了Flink的Temporal Table的语法,就是把Hive的维表作为Temporal Table,然后与流式的表进行join。想了解更多关于Temporal Table的内容,可查看Flink的官网。
关联Hive维表的实现是每个sub-task将Hive表缓存在内存中,是缓存整张的Hive表。如果Hive维表大小超过sub-task的可用内存,那么作业会失败。
Hive维表在关联的时候,Hive维表可能会发生更新,所以会允许用户设置hive表缓存的超时时间。超过这个时间后,sub-task会重新加载Hive维表。需要注意,这种场景不适用于Hive维表频繁更新的情况,这样会对HDFS文件系统造成很大的压力。所以适用于Hive维表缓慢更新的情况。缓存超时时间一般设置的比较长,一般是小时级别的。
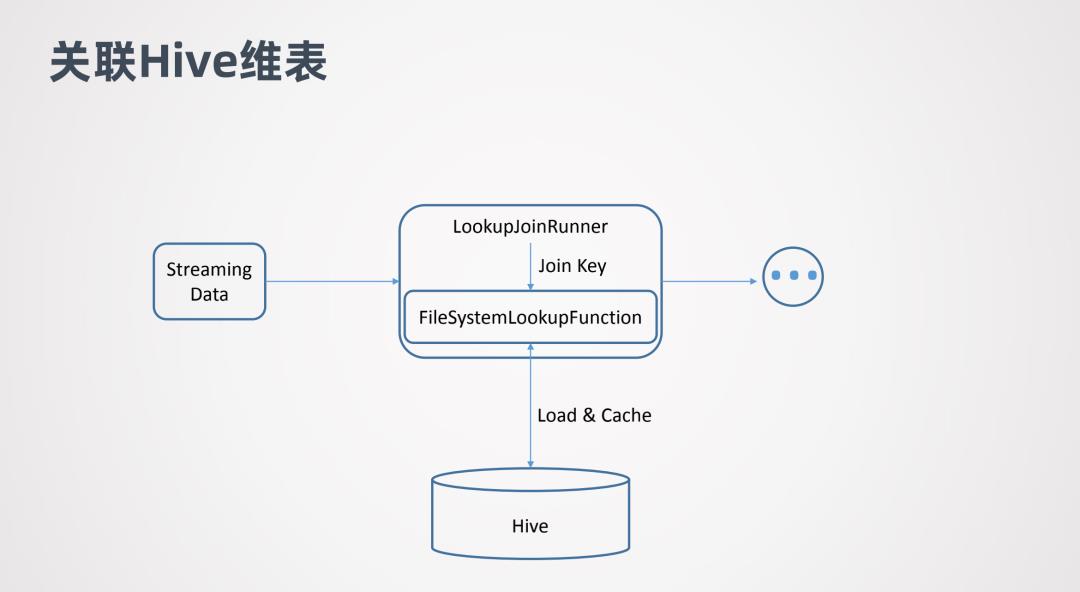
这张图表示的是关联Hive维表的原理。Streaming Data代表流式数据,LookupJoinRunner 表示Join算子,它会拿到流式数据的join key,并把join key传给FileSystemLookupFunction。
FileSystemLookupFunction是一个Table function,它会去跟底层的文件系统交互并加载Hive表,然后在Hive表中查询join key,判断哪些行数据是可以join的。
下面是关联Hive维表的例子:

这是Flink官网的一个例子,流式表是Orders,LatestTates是Hive的维表。
经过上面的介绍可以看出,在Flink 1.11中,在Hive数仓和批流一体的功能是进行了着重的开发。因为Flink是一个流处理的引擎,希望帮用户更好的将批和流结合,让Hive数仓实现实时化的改造,让用户更方便的挖掘数据的价值。
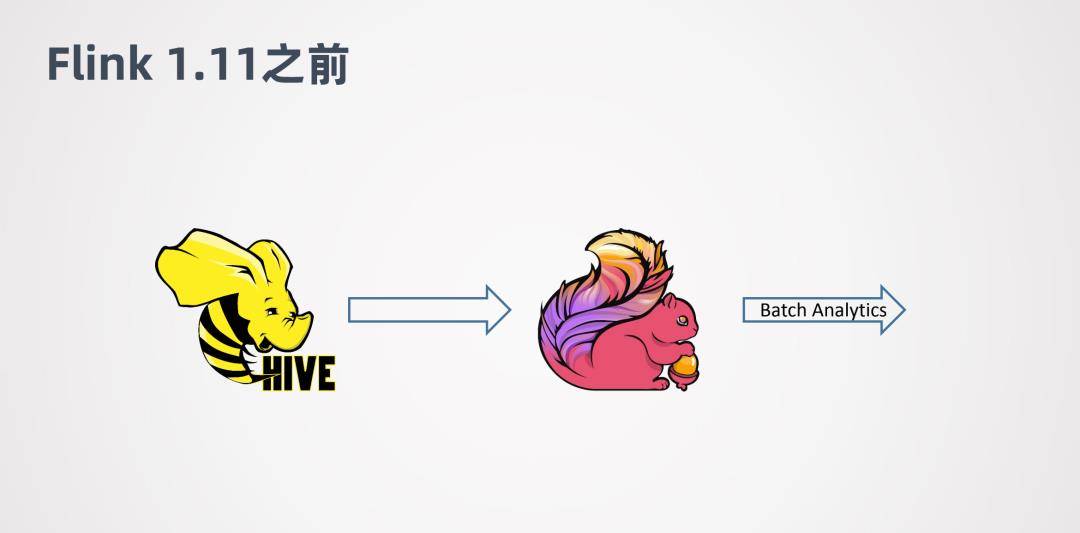
在Flink 1.11之前,Flink对接Hive会做些批处理的计算,并且只支持离线的场景。离线的场景一个问题是延迟比较大,批作业的调度一般都会通过一些调度的框架去调度。这样其实延迟会有累加的作用。例如第一个job跑完,才能去跑第二个job...这样依次执行。所以端对端的延迟就是所有job的叠加。
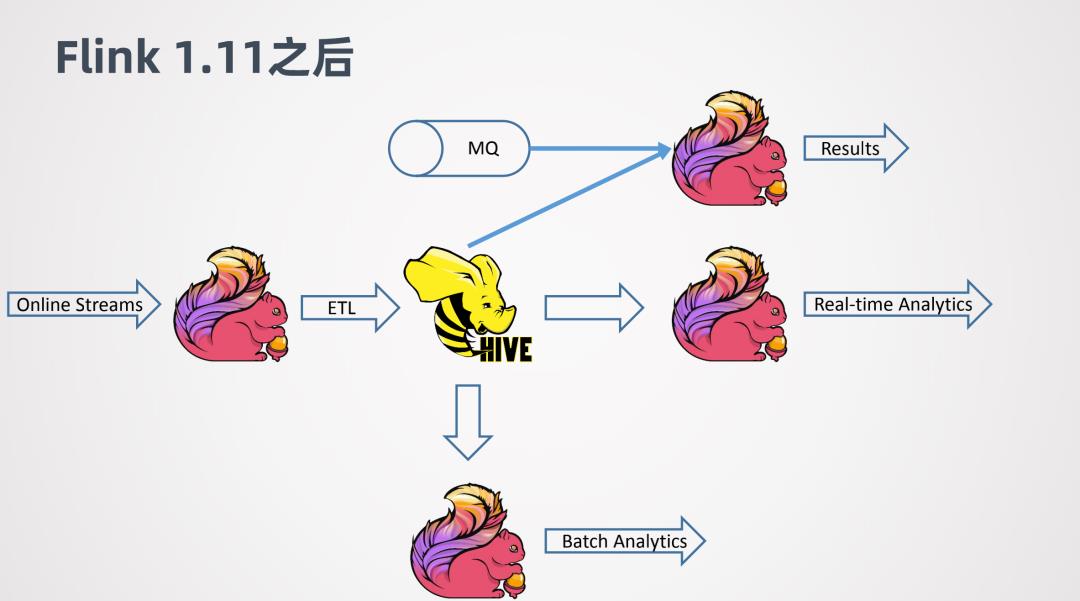
到了1.11之后,支持了Hive的流式处理的能力,就可以对Hive数仓进行一个实时化的改造。
例如Online的一些数据,用Flink做ETL,去实时的写入Hive。当数据写入Hive之后,可以进一步接一个新的Flink job,来做实时的查询或者近似实时的查询,可以很快的返回结果。同时,其他的Flink job还可以利用写入Hive数仓的数据作为维表,来跟其它线上的数据进行关联整合,来得到分析的结果。
今天的分享就到这里,谢谢大家。
在文末分享、点赞、在看,给个3连击呗~
嘉宾介绍:

李锐
阿里巴巴技术专家 | Apache Hive PMC
文章推荐:
社群推荐:
关于我们:
以上是关于Flink1.11+Hive批流一体数仓的主要内容,如果未能解决你的问题,请参考以下文章 Flink SQL 1.11新功能详解:Hive 数仓实时化 & Flink SQL + CDC 实践 基于 ClickHouse OLAP 的生态:构建基于 ClickHouse 计算存储为核心的“批流一体”数仓体系... 基于 ClickHouse OLAP 的生态:构建基于 ClickHouse 计算存储为核心的“批流一体”数仓体系...