基于 prometheus 的微服务指标监控
Posted GoCN
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了基于 prometheus 的微服务指标监控相关的知识,希望对你有一定的参考价值。
在微服务架构下随着服务越来越多,定位问题也变得越来越复杂,因此监控服务的运行状态以及针对异常状态及时的发出告警也成为微服务治理不可或缺的一环。服务的监控主要有日志监控、调用链路监控、指标监控等几种类型方式,其中指标监控在整个微服务监控中比重最高,也是实际生产中排查问题最重要的依赖
指标监控又可以细分为多种类型:
基础监控: 是针运行服务的基础设施的监控,比如容器、虚拟机、物理机等,监控的指标主要有内存的使用率,cpu 的使用率等资源的监控,通过对资源的监控和告警能够及时发现资源瓶颈从而进行扩容操作避免影响服务,同时针对资源的异常变化也能辅助定位服务问题,比如内存泄漏会导致内存异常
运行时监控: 运行时监控主要有 GC 的监控包括 GC 次数、GC 耗时,线程数量的监控等等
通用监控: 通用监控主要包括对流量和耗时的监控,通过流量的变化趋势可以清晰的了解到服务的流量高峰以及流量的增长情况,流量同时也是资源分配的重要参考指标。耗时是服务性能的直观体现,耗时比较大的服务我们往往需要进行优化,平均耗时往往参考价值不大,因为我们采取中位数,包括 90、95、99 值等
错误监控: 错误监控是服务健康状态的直观体现,主要包括请求返回的错误码,如 HTTP 的错误码 5xx、4xx,熔断、限流等等,通过对服务错误率的观察可以了解到服务当前的健康状态
prometheus是一个开源的系统监控和告警工具,支持强大的查询语言 PromQL 允许用户实时选择和汇聚时间序列数据,时间序列数据是服务端通过 HTTP 协议主动拉取获得,也可以通过中间网关来推送时间序列数据,可以通过静态配置文件或服务发现来获取监控目标,同时可以设置告警规则,prometheus 周期性通过 PromQL 进行计算,当满足条件就会触发告警
1 Prometheus 的架构
Prometheus 的整体架构以及生态系统组件如下图所示:
Prometheus Server 直接从监控目标中或者间接通过推送网关来拉取监控指标,它在本地存储所有抓取到样本数据,并对此数据执行一系列规则,以汇总和记录现有数据的新时间序列或生成告警。可以通过 Grafana 或者其他工具来实现监控数据的可视化
下面我们通过一个简单的实例来演示如何对微服务进行指标监控,以及相关组件的使用
2 go-zero 基于 Prometheus 的服务指标监控
go-zero 框架中集成了基于 prometheus 的服务指标监控,下面我们通过 go-zero 官方的示例shorturl来演示是如何对服务指标进行收集监控的:
第一步需要先安装 Prometheus,安装步骤请参考官方文档
Prometheus:
Host: 127.0.0.1
Port: 9091
Path: /metrics
编辑 prometheus 的配置文件 prometheus.yml,添加如下配置,并创建 targets.json
- job_name: 'file_ds'
file_sd_configs:
- files:
- targets.json[{
"targets": ["127.0.0.1:9091"],
"labels": {
"job": "shorturl-api",
"app": "shorturl-api",
"env": "test",
"instance": "127.0.0.1:8888"
}
}]启动 prometheus 服务,默认侦听在 9090 端口
prometheus --config.file=prometheus.yml在浏览器输入http://127.0.0.1:9090/Status,然后点击 -> Targets 即可看到状态为 Up 的 Job,并且 Lables 栏可以看到我们配置的默认的标签
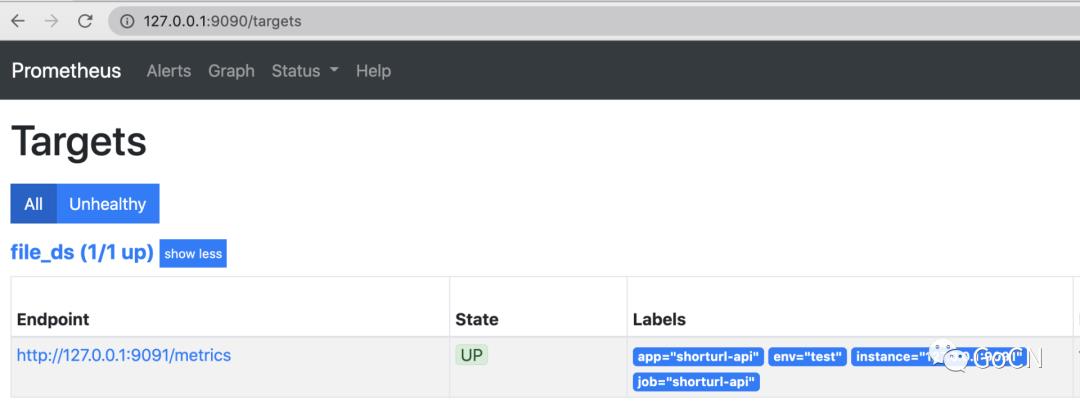
通过以上几个步骤我们完成了 prometheus 对 shorturl 服务的指标监控收集的配置工作,为了演示简单我们进行了手动的配置,在实际的生产环境中一般采用定时更新配置文件或者服务发现的方式来配置监控目标,篇幅有限这里不展开讲解,感兴趣的同学请自行查看相关文档
3 go-zero 监控的指标类型
go-zero 中目前在 http 的中间件和 rpc 的拦截器中添加了对请求指标的监控。
主要从请求耗时和请求错误两个维度,请求耗时采用了 Histogram 指标类型定义了多个 Buckets 方便进行分位统计,请求错误采用了 Counter 类型,并在 http metric 中添加了 path 标签 rpc metric 中添加了 method 标签以便进行细分监控。
接下来演示如何查看监控指标:
首先在命令行多次执行如下命令
curl -i "http://localhost:8888/shorten?url=http://www.xiaoheiban.cn"
打开 Prometheus 切换到 Graph 界面,在输入框中输入{path="/shorten"}指令,即可查看监控指标,如下图
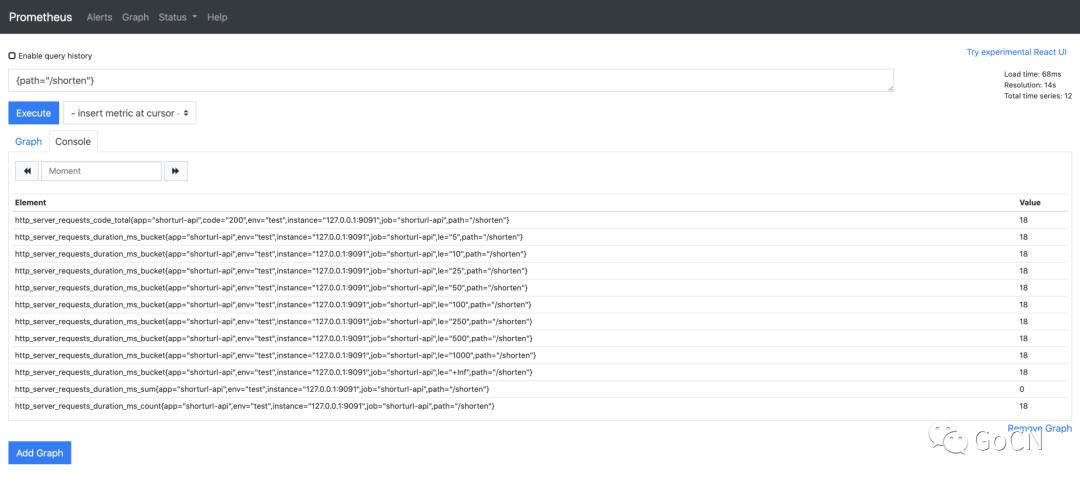
我们通过 PromQL 语法查询过滤 path 为/shorten 的指标,结果中显示了指标名以及指标数值,其中 http_server_requests_code_total 指标中 code 值为 http 的状态码,200 表明请求成功,http_server_requests_duration_ms_bucket 中对不同 bucket 结果分别进行了统计,还可以看到所有的指标中都添加了我们配置的默认指标
Console 界面主要展示了查询的指标结果,Graph 界面为我们提供了简单的图形化的展示界面,在实际的生产环境中我们一般使用 Grafana 做图形化的展示
4 grafana 可视化界面
grafana是一款可视化工具,功能强大,支持多种数据来源 Prometheus、Elasticsearch、Graphite 等,安装比较简单请参考官方文档,grafana 默认端口 3000,安装好后再浏览器输入http://localhost:3000/admin,默认账号和密码都为
下面演示如何基于以上指标进行可视化界面的绘制:
点击左侧边栏添加 dashboard,然后添加 Variables 方便针对不同的标签进行过滤筛选比如添加 app 变量用来过滤不同的服务
进入 dashboard 点击右上角 Add panel 添加面板,以 path 维度统计接口的 qps

最终的效果如下所示,可以通过服务名称过滤不同的服务,面板展示了 path 为/shorten 的 qps 变化趋势
5 总结
以上演示了 go-zero 中基于 prometheus+grafana 服务指标监控的简单流程,生产环境中可以根据实际的场景做不同维度的监控分析。现在 go-zero 的监控指标主要还是针对 http 和 rpc,这对于服务的整体监控显然还是不足的,比如容器资源的监控,依赖的 mysql、redis 等资源的监控,以及自定义的指标监控等等,go-zero 在这方面后续还会持续优化
监控不是万能的,虽然监控能帮助我们及时的发现问题,但很多场景下告警一旦产生可能就已经对用户产生了影响,所以我们应该提前预测问题发生的可能,采取的手段主要有对服务的压测,对使用资源的评估,以及定期的进行服务巡检等等,希望本文能给大家带来帮助
项目地址
https://github.com/tal-tech/go-zero
微信交流群
2020 GopherChinaCon 隆重开启!
时间:2020年11月20-22日
地点:上海由由喜来登酒店
报名方式:点击“阅读原文”,早鸟票火热开启中
以上是关于基于 prometheus 的微服务指标监控的主要内容,如果未能解决你的问题,请参考以下文章